 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalized Routing: Model and Agent Orchestration for Adaptive and Efficient Inference
Sep 09, 2025The rapid advancement of large language models (LLMs) and domain-specific AI agents has greatly expanded the ecosystem of AI-powered services. User queries, however, are highly diverse and often span multiple domains and task types, resulting in a complex and heterogeneous landscape. This diversity presents a fundamental routing challenge: how to accurately direct each query to an appropriate execution unit while optimizing both performance and efficiency. To address this, we propose MoMA (Mixture of Models and Agents), a generalized routing framework that integrates both LLM and agent-based routing. Built upon a deep understanding of model and agent capabilities, MoMA effectively handles diverse queries through precise intent recognition and adaptive routing strategies, achieving an optimal balance between efficiency and cost. Specifically, we construct a detailed training dataset to profile the capabilities of various LLMs under different routing model structures, identifying the most suitable tasks for each LLM. During inference, queries are dynamically routed to the LLM with the best cost-performance efficiency. We also introduce an efficient agent selection strategy based on a context-aware state machine and dynamic masking. Experimental results demonstrate that the MoMA router offers superior cost-efficiency and scalability compared to existing approaches.
Inorganic Catalyst Efficiency Prediction Based on EAPCR Model: A Deep Learning Solution for Multi-Source Heterogeneous Data
Mar 10, 2025



The design of inorganic catalysts and the prediction of their catalytic efficiency are fundamental challenges in chemistry and materials science. Traditional catalyst evaluation methods primarily rely on machine learning techniques; however, these methods often struggle to process multi-source heterogeneous data, limiting both predictive accuracy and generalization. To address these limitations, this study introduces the Embedding-Attention-Permutated CNN-Residual (EAPCR) deep learning model. EAPCR constructs a feature association matrix using embedding and attention mechanisms and enhances predictive performance through permutated CNN architectures and residual connections. This approach enables the model to accurately capture complex feature interactions across various catalytic conditions, leading to precise efficiency predictions. EAPCR serves as a powerful tool for computational researchers while also assisting domain experts in optimizing catalyst design, effectively bridging the gap between data-driven modeling and experimental applications. We evaluate EAPCR on datasets from TiO2 photocatalysis, thermal catalysis, and electrocatalysis, demonstrating its superiority over traditional machine learning methods (e.g., linear regression, random forest) as well as conventional deep learning models (e.g., ANN, NNs). Across multiple evaluation metrics (MAE, MSE, R2, and RMSE), EAPCR consistently outperforms existing approaches. These findings highlight the strong potential of EAPCR in inorganic catalytic efficiency prediction. As a versatile deep learning framework, EAPCR not only improves predictive accuracy but also establishes a solid foundation for future large-scale model development in inorganic catalysis.
Increasing SLAM Pose Accuracy by Ground-to-Satellite Image Registration
Apr 14, 2024Vision-based localization for autonomous driving has been of great interest among researchers. When a pre-built 3D map is not available, the techniques of visual simultaneous localization and mapping (SLAM) are typically adopted. Due to error accumulation, visual SLAM (vSLAM) usually suffers from long-term drift. This paper proposes a framework to increase the localization accuracy by fusing the vSLAM with a deep-learning-based ground-to-satellite (G2S) image registration method. In this framework, a coarse (spatial correlation bound check) to fine (visual odometry consistency check) method is designed to select the valid G2S prediction. The selected prediction is then fused with the SLAM measurement by solving a scaled pose graph problem. To further increase the localization accuracy, we provide an iterative trajectory fusion pipeline. The proposed framework is evaluated on two well-known autonomous driving datasets, and the results demonstrate the accuracy and robustness in terms of vehicle localization.
Homography Guided Temporal Fusion for Road Line and Marking Segmentation
Apr 11, 2024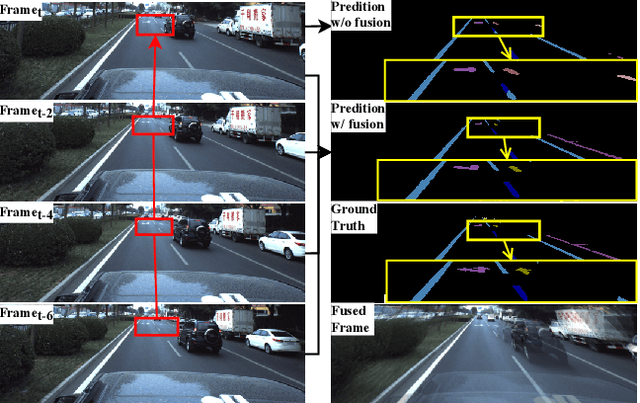
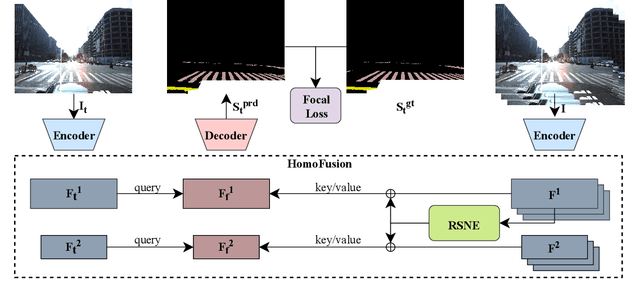


Reliable segmentation of road lines and markings is critical to autonomous driving. Our work is motivated by the observations that road lines and markings are (1) frequently occluded in the presence of moving vehicles, shadow, and glare and (2) highly structured with low intra-class shape variance and overall high appearance consistency. To solve these issues, we propose a Homography Guided Fusion (HomoFusion) module to exploit temporally-adjacent video frames for complementary cues facilitating the correct classification of the partially occluded road lines or markings. To reduce computational complexity, a novel surface normal estimator is proposed to establish spatial correspondences between the sampled frames, allowing the HomoFusion module to perform a pixel-to-pixel attention mechanism in updating the representation of the occluded road lines or markings. Experiments on ApolloScape, a large-scale lane mark segmentation dataset, and ApolloScape Night with artificial simulated night-time road conditions, demonstrate that our method outperforms other existing SOTA lane mark segmentation models with less than 9\% of their parameters and computational complexity. We show that exploiting available camera intrinsic data and ground plane assumption for cross-frame correspondence can lead to a light-weight network with significantly improved performances in speed and accuracy. We also prove the versatility of our HomoFusion approach by applying it to the problem of water puddle segmentation and achieving SOTA performance.
Inclusive Design Insights from a Preliminary Image-Based Conversational Search Systems Evaluation
Mar 29, 2024



The digital realm has witnessed the rise of various search modalities, among which the Image-Based Conversational Search System stands out. This research delves into the design, implementation, and evaluation of this specific system, juxtaposing it against its text-based and mixed counterparts. A diverse participant cohort ensures a broad evaluation spectrum. Advanced tools facilitate emotion analysis, capturing user sentiments during interactions, while structured feedback sessions offer qualitative insights. Results indicate that while the text-based system minimizes user confusion, the image-based system presents challenges in direct information interpretation. However, the mixed system achieves the highest engagement, suggesting an optimal blend of visual and textual information. Notably, the potential of these systems, especially the image-based modality, to assist individuals with intellectual disabilities is highlighted. The study concludes that the Image-Based Conversational Search System, though challenging in some aspects, holds promise, especially when integrated into a mixed system, offering both clarity and engagement.
Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants
Oct 01, 2023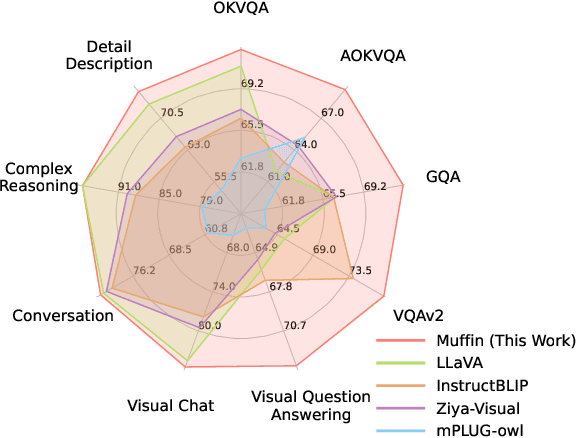
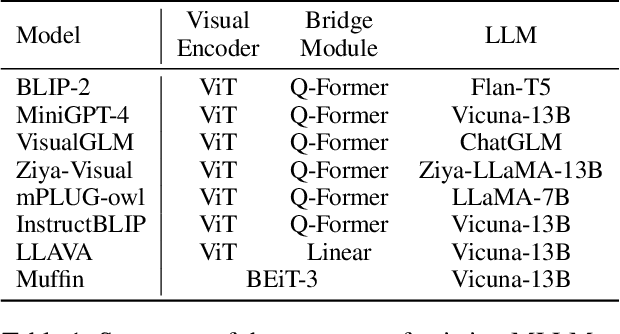
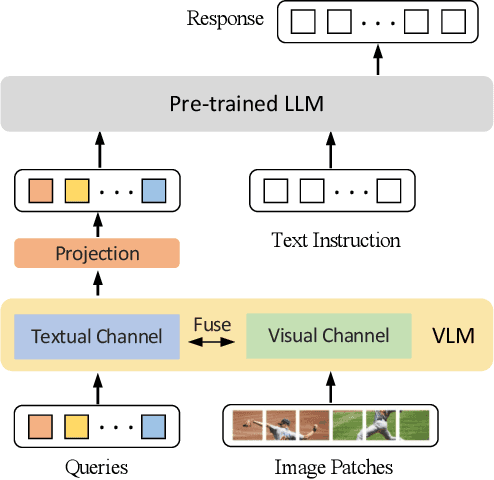
Recent Multimodal Large Language Models (MLLMs) exhibit impressive abilities to perceive images and follow open-ended instructions. The capabilities of MLLMs depend on two crucial factors: the model architecture to facilitate the feature alignment of visual modules and large language models; the multimodal instruction tuning datasets for human instruction following. (i) For the model architecture, most existing models introduce an external bridge module to connect vision encoders with language models, which needs an additional feature-alignment pre-training. In this work, we discover that compact pre-trained vision language models can inherently serve as ``out-of-the-box'' bridges between vision and language. Based on this, we propose Muffin framework, which directly employs pre-trained vision-language models to act as providers of visual signals. (ii) For the multimodal instruction tuning datasets, existing methods omit the complementary relationship between different datasets and simply mix datasets from different tasks. Instead, we propose UniMM-Chat dataset which explores the complementarities of datasets to generate 1.1M high-quality and diverse multimodal instructions. We merge information describing the same image from diverse datasets and transforms it into more knowledge-intensive conversation data. Experimental results demonstrate the effectiveness of the Muffin framework and UniMM-Chat dataset. Muffin achieves state-of-the-art performance on a wide range of vision-language tasks, significantly surpassing state-of-the-art models like LLaVA and InstructBLIP. Our model and dataset are all accessible at https://github.com/thunlp/muffin.
Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages
Aug 23, 2023



Recently there has been a significant surge in multimodal learning in terms of both image-to-text and text-to-image generation. However, the success is typically limited to English, leaving other languages largely behind. Building a competitive counterpart in other languages is highly challenging due to the low-resource nature of non-English multimodal data (i.e., lack of large-scale, high-quality image-text data). In this work, we propose MPM, an effective training paradigm for training large multimodal models in low-resource languages. MPM demonstrates that Multilingual language models can Pivot zero-shot Multimodal learning across languages. Specifically, based on a strong multilingual large language model, multimodal models pretrained on English-only image-text data can well generalize to other languages in a zero-shot manner for both image-to-text and text-to-image generation, even surpassing models trained on image-text data in native languages. Taking Chinese as a practice of MPM, we build large multimodal models VisCPM in image-to-text and text-to-image generation, which achieve state-of-the-art (open-source) performance in Chinese. To facilitate future research, we open-source codes and model weights at https://github.com/OpenBMB/VisCPM.git.
View Consistent Purification for Accurate Cross-View Localization
Aug 16, 2023

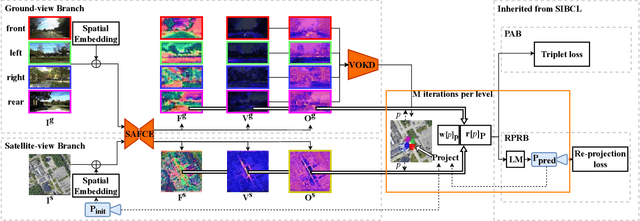

This paper proposes a fine-grained self-localization method for outdoor robotics that utilizes a flexible number of onboard cameras and readily accessible satellite images. The proposed method addresses limitations in existing cross-view localization methods that struggle to handle noise sources such as moving objects and seasonal variations. It is the first sparse visual-only method that enhances perception in dynamic environments by detecting view-consistent key points and their corresponding deep features from ground and satellite views, while removing off-the-ground objects and establishing homography transformation between the two views. Moreover, the proposed method incorporates a spatial embedding approach that leverages camera intrinsic and extrinsic information to reduce the ambiguity of purely visual matching, leading to improved feature matching and overall pose estimation accuracy. The method exhibits strong generalization and is robust to environmental changes, requiring only geo-poses as ground truth. Extensive experiments on the KITTI and Ford Multi-AV Seasonal datasets demonstrate that our proposed method outperforms existing state-of-the-art methods, achieving median spatial accuracy errors below $0.5$ meters along the lateral and longitudinal directions, and a median orientation accuracy error below 2 degrees.
Model Calibration in Dense Classification with Adaptive Label Perturbation
Aug 03, 2023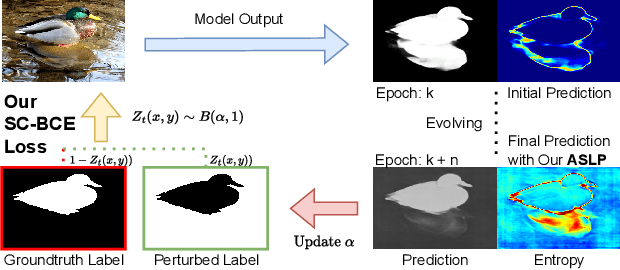
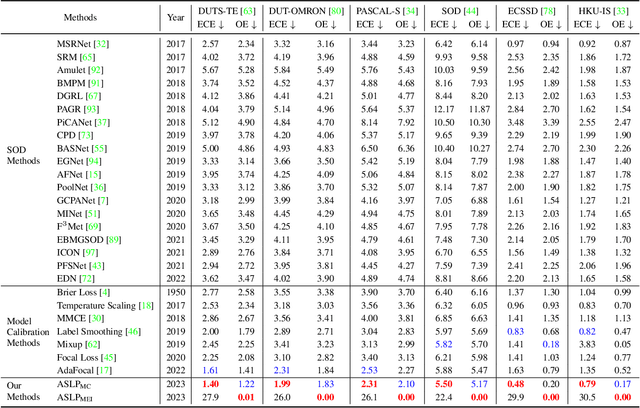
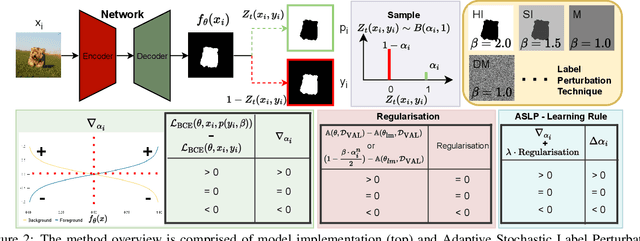
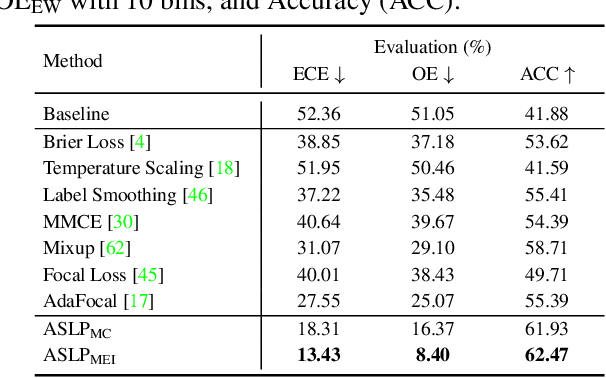
For safety-related applications, it is crucial to produce trustworthy deep neural networks whose prediction is associated with confidence that can represent the likelihood of correctness for subsequent decision-making. Existing dense binary classification models are prone to being over-confident. To improve model calibration, we propose Adaptive Stochastic Label Perturbation (ASLP) which learns a unique label perturbation level for each training image. ASLP employs our proposed Self-Calibrating Binary Cross Entropy (SC-BCE) loss, which unifies label perturbation processes including stochastic approaches (like DisturbLabel), and label smoothing, to correct calibration while maintaining classification rates. ASLP follows Maximum Entropy Inference of classic statistical mechanics to maximise prediction entropy with respect to missing information. It performs this while: (1) preserving classification accuracy on known data as a conservative solution, or (2) specifically improves model calibration degree by minimising the gap between the prediction accuracy and expected confidence of the target training label. Extensive results demonstrate that ASLP can significantly improve calibration degrees of dense binary classification models on both in-distribution and out-of-distribution data. The code is available on https://github.com/Carlisle-Liu/ASLP.
Samplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.