 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025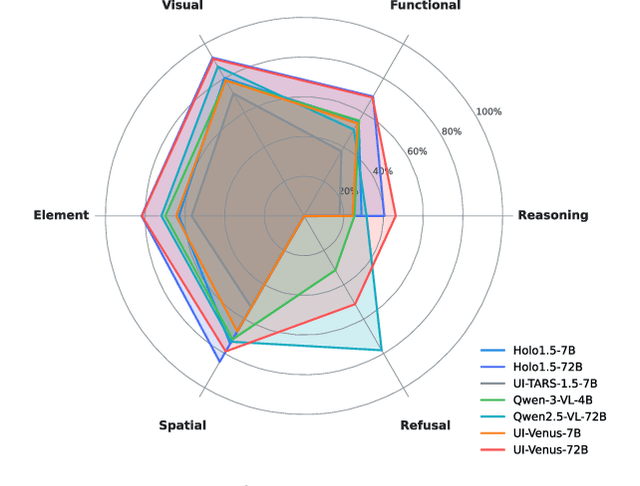
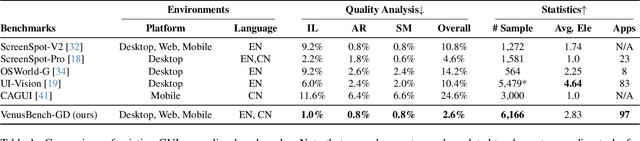
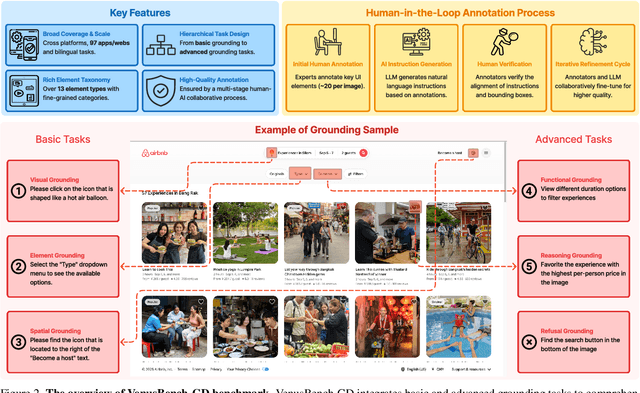
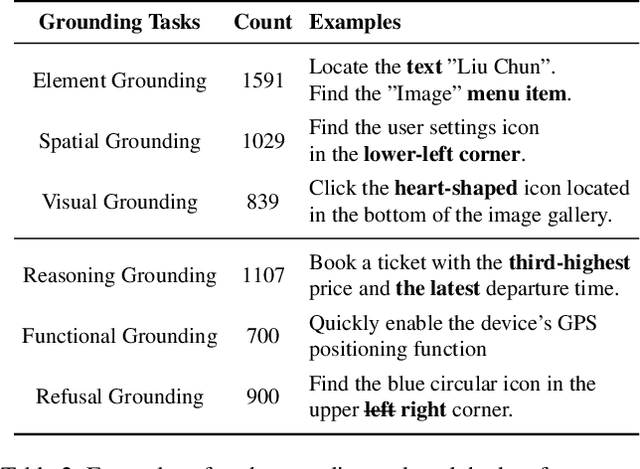
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
E-ANT: A Large-Scale Dataset for Efficient Automatic GUI NavigaTion
Jun 20, 2024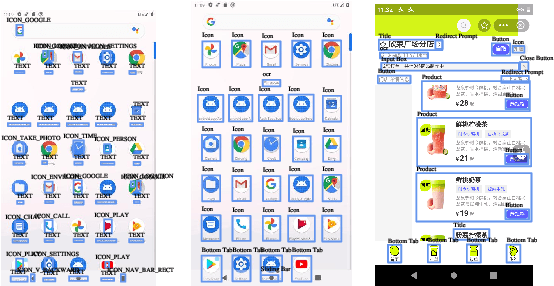
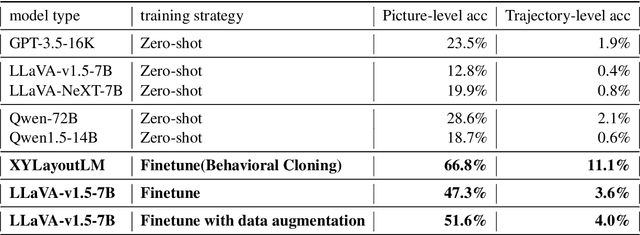
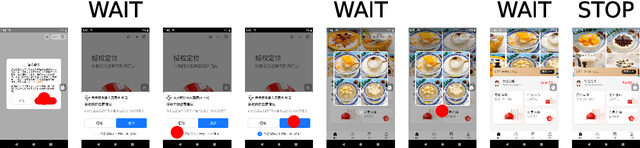
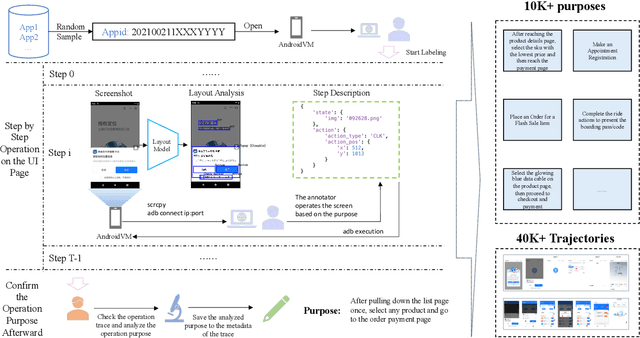
Online GUI navigation on mobile devices has driven a lot of attention recent years since it contributes to many real-world applications. With the rapid development of large language models (LLM), multimodal large language models (MLLM) have tremendous potential on this task. However, existing MLLMs need high quality data to improve its abilities of making the correct navigation decisions according to the human user inputs. In this paper, we developed a novel and highly valuable dataset, named \textbf{E-ANT}, as the first Chinese GUI navigation dataset that contains real human behaviour and high quality screenshots with annotations, containing nearly 40,000 real human traces over 5000+ different tinyAPPs. Furthermore, we evaluate various powerful MLLMs on E-ANT and show their experiments results with sufficient ablations. We believe that our proposed dataset will be beneficial for both the evaluation and development of GUI navigation and LLM/MLLM decision-making capabilities.
Inclusive Design Insights from a Preliminary Image-Based Conversational Search Systems Evaluation
Mar 29, 2024



The digital realm has witnessed the rise of various search modalities, among which the Image-Based Conversational Search System stands out. This research delves into the design, implementation, and evaluation of this specific system, juxtaposing it against its text-based and mixed counterparts. A diverse participant cohort ensures a broad evaluation spectrum. Advanced tools facilitate emotion analysis, capturing user sentiments during interactions, while structured feedback sessions offer qualitative insights. Results indicate that while the text-based system minimizes user confusion, the image-based system presents challenges in direct information interpretation. However, the mixed system achieves the highest engagement, suggesting an optimal blend of visual and textual information. Notably, the potential of these systems, especially the image-based modality, to assist individuals with intellectual disabilities is highlighted. The study concludes that the Image-Based Conversational Search System, though challenging in some aspects, holds promise, especially when integrated into a mixed system, offering both clarity and engagement.
Differentially Private Learning with Per-Sample Adaptive Clipping
Dec 01, 2022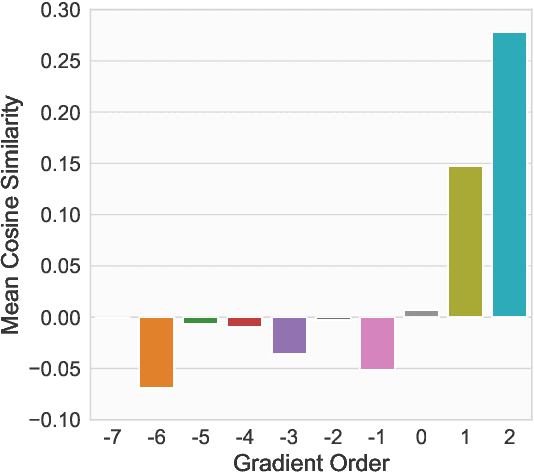

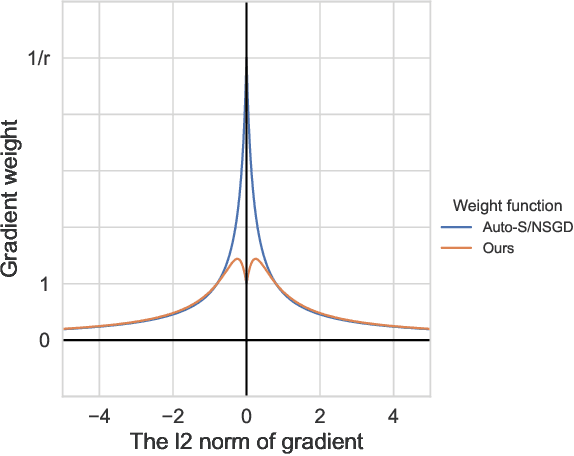
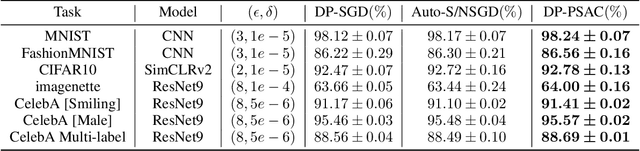
Privacy in AI remains a topic that draws attention from researchers and the general public in recent years. As one way to implement privacy-preserving AI, differentially private learning is a framework that enables AI models to use differential privacy (DP). To achieve DP in the learning process, existing algorithms typically limit the magnitude of gradients with a constant clipping, which requires carefully tuned due to its significant impact on model performance. As a solution to this issue, latest works NSGD and Auto-S innovatively propose to use normalization instead of clipping to avoid hyperparameter tuning. However, normalization-based approaches like NSGD and Auto-S rely on a monotonic weight function, which imposes excessive weight on small gradient samples and introduces extra deviation to the update. In this paper, we propose a Differentially Private Per-Sample Adaptive Clipping (DP-PSAC) algorithm based on a non-monotonic adaptive weight function, which guarantees privacy without the typical hyperparameter tuning process of using a constant clipping while significantly reducing the deviation between the update and true batch-averaged gradient. We provide a rigorous theoretical convergence analysis and show that with convergence rate at the same order, the proposed algorithm achieves a lower non-vanishing bound, which is maintained over training iterations, compared with NSGD/Auto-S. In addition, through extensive experimental evaluation, we show that DP-PSAC outperforms or matches the state-of-the-art methods on multiple main-stream vision and language tasks.