 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Autonomous Agents against Temporal, Spatial, and Semantic Evasions
May 21, 2026As autonomous agents (e.g., OpenClaw) increasingly operate with deep system-level privileges to execute complex tasks, they introduce severe, unmitigated security risks. Current vulnerability analyses overwhelmingly focus on single-turn, stateless behaviors, overlooking the expanded attack surface inherent in stateful, multi-turn interactions and dynamic tool invocations. In this paper, we propose a novel, multi-dimensional evasion framework targeting LLM-based agent systems. We introduce three stealthy attack vectors: (1) Temporal evasion, which fragments malicious payloads across sequential interaction turns; (2) Spatial evasion, which conceals payloads within complex external artifacts that evade standard LLM parsing mechanisms; and (3) Semantic evasion, which obscures malicious intents beneath benign contextual noise. To systematically quantify these threats, we construct A3S-Bench, a comprehensive benchmark comprising 2,254 real-world agent execution trajectories. Evaluating a standard agent framework separately integrated with 10 mainstream LLM backbones against 20 practical threat scenarios, we demonstrate that our evasion framework elevates the average risk trigger rate from a 28.3\% baseline to 52.6\%. These findings reveal systemic, architecture-level vulnerabilities in current autonomous agent systems that existing defenses fail to address, highlighting an urgent need for defense mechanisms tailored to the unique threats.
DR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
Apr 21, 2026Edge-scale deep research agents based on small language models are attractive for real-world deployment due to their advantages in cost, latency, and privacy. In this work, we study how to train a strong small deep research agent under limited open-data by improving both data quality and data utilization. We present DR-Venus, a frontier 4B deep research agent for edge-scale deployment, built entirely on open data. Our training recipe consists of two stages. In the first stage, we use agentic supervised fine-tuning (SFT) to establish basic agentic capability, combining strict data cleaning with resampling of long-horizon trajectories to improve data quality and utilization. In the second stage, we apply agentic reinforcement learning (RL) to further improve execution reliability on long-horizon deep research tasks. To make RL effective for small agents in this setting, we build on IGPO and design turn-level rewards based on information gain and format-aware regularization, thereby enhancing supervision density and turn-level credit assignment. Built entirely on roughly 10K open-data, DR-Venus-4B significantly outperforms prior agentic models under 9B parameters on multiple deep research benchmarks, while also narrowing the gap to much larger 30B-class systems. Our further analysis shows that 4B agents already possess surprisingly strong performance potential, highlighting both the deployment promise of small models and the value of test-time scaling in this setting. We release our models, code, and key recipes to support reproducible research on edge-scale deep research agents.
Taming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats
Mar 12, 2026Autonomous Large Language Model (LLM) agents, exemplified by OpenClaw, demonstrate remarkable capabilities in executing complex, long-horizon tasks. However, their tightly coupled instant-messaging interaction paradigm and high-privilege execution capabilities substantially expand the system attack surface. In this paper, we present a comprehensive security threat analysis of OpenClaw. To structure our analysis, we introduce a five-layer lifecycle-oriented security framework that captures key stages of agent operation, i.e., initialization, input, inference, decision, and execution, and systematically examine compound threats across the agent's operational lifecycle, including indirect prompt injection, skill supply chain contamination, memory poisoning, and intent drift. Through detailed case studies on OpenClaw, we demonstrate the prevalence and severity of these threats and analyze the limitations of existing defenses. Our findings reveal critical weaknesses in current point-based defense mechanisms when addressing cross-temporal and multi-stage systemic risks, highlighting the need for holistic security architectures for autonomous LLM agents. Within this framework, we further examine representative defense strategies at each lifecycle stage, including plugin vetting frameworks, context-aware instruction filtering, memory integrity validation protocols, intent verification mechanisms, and capability enforcement architectures.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Mitigating Conversational Inertia in Multi-Turn Agents
Feb 03, 2026Large language models excel as few-shot learners when provided with appropriate demonstrations, yet this strength becomes problematic in multiturn agent scenarios, where LLMs erroneously mimic their own previous responses as few-shot examples. Through attention analysis, we identify conversational inertia, a phenomenon where models exhibit strong diagonal attention to previous responses, which is associated with imitation bias that constrains exploration. This reveals a tension when transforming few-shot LLMs into agents: longer context enriches environmental feedback for exploitation, yet also amplifies conversational inertia that undermines exploration. Our key insight is that for identical states, actions generated with longer contexts exhibit stronger inertia than those with shorter contexts, enabling construction of preference pairs without environment rewards. Based on this, we propose Context Preference Learning to calibrate model preferences to favor low-inertia responses over highinertia ones. We further provide context management strategies at inference time to balance exploration and exploitation. Experimental results across eight agentic environments and one deep research scenario validate that our framework reduces conversational inertia and achieves performance improvements.
Unified Generation and Self-Verification for Vision-Language Models via Advantage Decoupled Preference Optimization
Jan 04, 2026Parallel test-time scaling typically trains separate generation and verification models, incurring high training and inference costs. We propose Advantage Decoupled Preference Optimization (ADPO), a unified reinforcement learning framework that jointly learns answer generation and self-verification within a single policy. ADPO introduces two innovations: a preference verification reward improving verification capability and a decoupled optimization mechanism enabling synergistic optimization of generation and verification. Specifically, the preference verification reward computes mean verification scores from positive and negative samples as decision thresholds, providing positive feedback when prediction correctness aligns with answer correctness. Meanwhile, the advantage decoupled optimization computes separate advantages for generation and verification, applies token masks to isolate gradients, and combines masked GRPO objectives, preserving generation quality while calibrating verification scores. ADPO achieves up to +34.1% higher verification AUC and -53.5% lower inference time, with significant gains of +2.8%/+1.4% accuracy on MathVista/MMMU, +1.9 cIoU on ReasonSeg, and +1.7%/+1.0% step success rate on AndroidControl/GUI Odyssey.
VenusBench-GD: A Comprehensive Multi-Platform GUI Benchmark for Diverse Grounding Tasks
Dec 18, 2025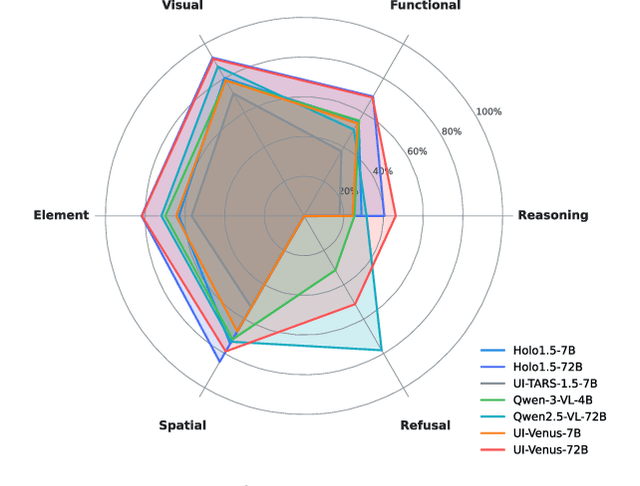
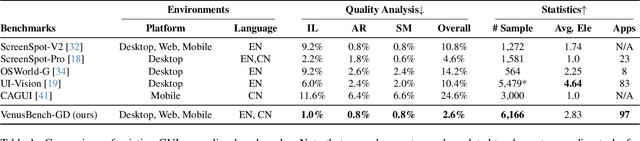
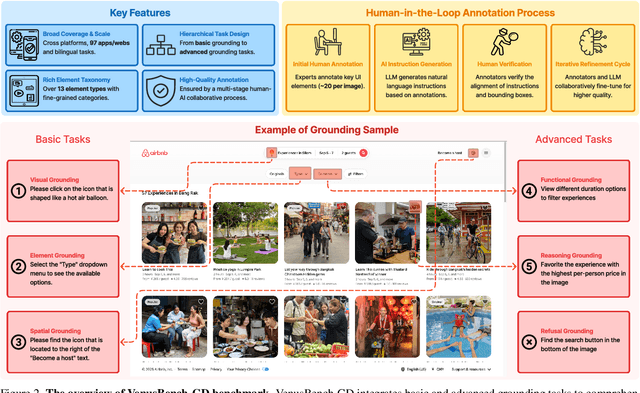
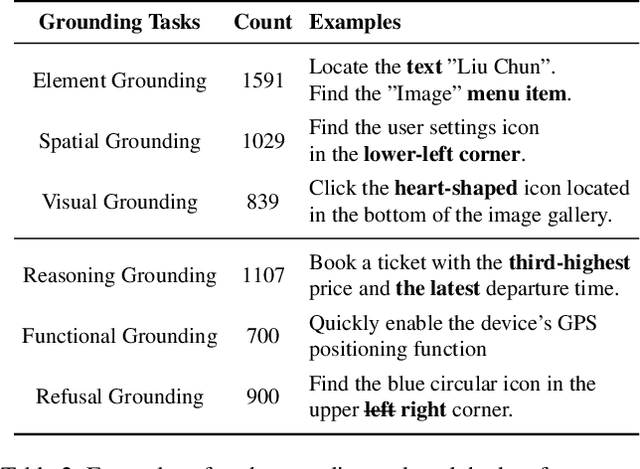
GUI grounding is a critical component in building capable GUI agents. However, existing grounding benchmarks suffer from significant limitations: they either provide insufficient data volume and narrow domain coverage, or focus excessively on a single platform and require highly specialized domain knowledge. In this work, we present VenusBench-GD, a comprehensive, bilingual benchmark for GUI grounding that spans multiple platforms, enabling hierarchical evaluation for real-word applications. VenusBench-GD contributes as follows: (i) we introduce a large-scale, cross-platform benchmark with extensive coverage of applications, diverse UI elements, and rich annotated data, (ii) we establish a high-quality data construction pipeline for grounding tasks, achieving higher annotation accuracy than existing benchmarks, and (iii) we extend the scope of element grounding by proposing a hierarchical task taxonomy that divides grounding into basic and advanced categories, encompassing six distinct subtasks designed to evaluate models from complementary perspectives. Our experimental findings reveal critical insights: general-purpose multimodal models now match or even surpass specialized GUI models on basic grounding tasks. In contrast, advanced tasks, still favor GUI-specialized models, though they exhibit significant overfitting and poor robustness. These results underscore the necessity of comprehensive, multi-tiered evaluation frameworks.
MVP: Multiple View Prediction Improves GUI Grounding
Dec 09, 2025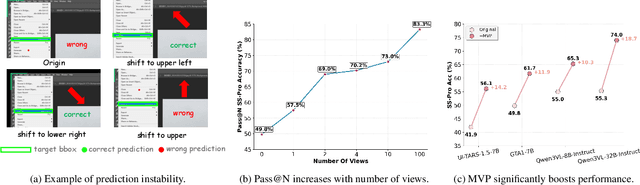
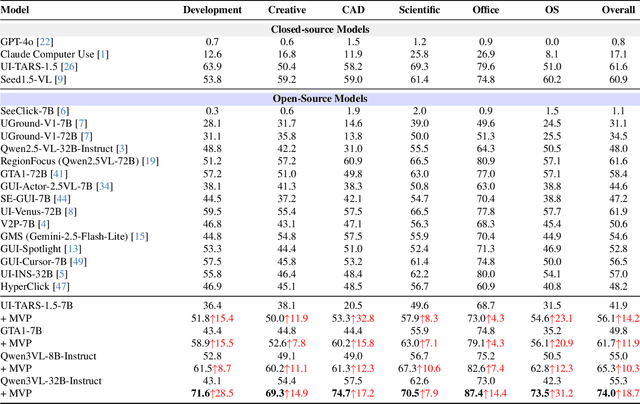
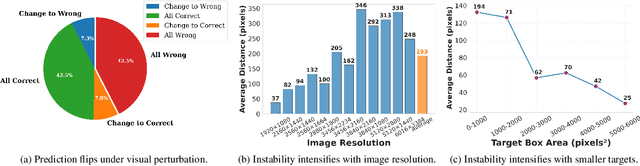
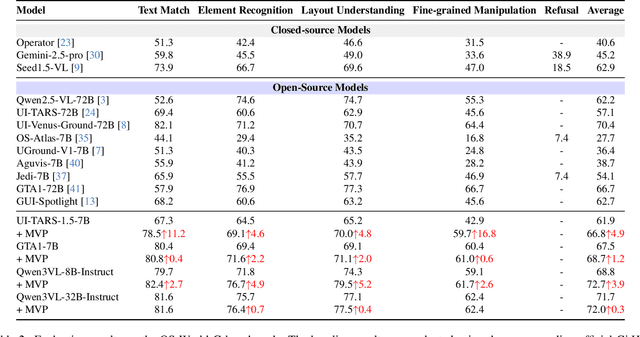
GUI grounding, which translates natural language instructions into precise pixel coordinates, is essential for developing practical GUI agents. However, we observe that existing grounding models exhibit significant coordinate prediction instability, minor visual perturbations (e.g. cropping a few pixels) can drastically alter predictions, flipping results between correct and incorrect. This instability severely undermines model performance, especially for samples with high-resolution and small UI elements. To address this issue, we propose Multi-View Prediction (MVP), a training-free framework that enhances grounding performance through multi-view inference. Our key insight is that while single-view predictions may be unstable, aggregating predictions from multiple carefully cropped views can effectively distinguish correct coordinates from outliers. MVP comprises two components: (1) Attention-Guided View Proposal, which derives diverse views guided by instruction-to-image attention scores, and (2) Multi-Coordinates Clustering, which ensembles predictions by selecting the centroid of the densest spatial cluster. Extensive experiments demonstrate MVP's effectiveness across various models and benchmarks. Notably, on ScreenSpot-Pro, MVP boosts UI-TARS-1.5-7B to 56.1%, GTA1-7B to 61.7%, Qwen3VL-8B-Instruct to 65.3%, and Qwen3VL-32B-Instruct to 74.0%. The code is available at https://github.com/ZJUSCL/MVP.
The Reasoning Trap: How Enhancing LLM Reasoning Amplifies Tool Hallucination
Oct 27, 2025Enhancing the reasoning capabilities of Large Language Models (LLMs) is a key strategy for building Agents that "think then act." However, recent observations, like OpenAI's o3, suggest a paradox: stronger reasoning often coincides with increased hallucination, yet no prior work has systematically examined whether reasoning enhancement itself causes tool hallucination. To address this gap, we pose the central question: Does strengthening reasoning increase tool hallucination? To answer this, we introduce SimpleToolHalluBench, a diagnostic benchmark measuring tool hallucination in two failure modes: (i) no tool available, and (ii) only distractor tools available. Through controlled experiments, we establish three key findings. First, we demonstrate a causal relationship: progressively enhancing reasoning through RL increases tool hallucination proportionally with task performance gains. Second, this effect transcends overfitting - training on non-tool tasks (e.g., mathematics) still amplifies subsequent tool hallucination. Third, the effect is method-agnostic, appearing when reasoning is instilled via supervised fine-tuning and when it is merely elicited at inference by switching from direct answers to step-by-step thinking. We also evaluate mitigation strategies including Prompt Engineering and Direct Preference Optimization (DPO), revealing a fundamental reliability-capability trade-off: reducing hallucination consistently degrades utility. Mechanistically, Reasoning RL disproportionately collapses tool-reliability-related representations, and hallucinations surface as amplified divergences concentrated in late-layer residual streams. These findings reveal that current reasoning enhancement methods inherently amplify tool hallucination, highlighting the need for new training objectives that jointly optimize for capability and reliability.
Careful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025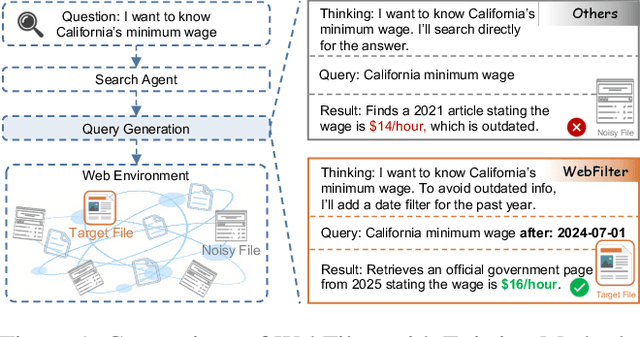
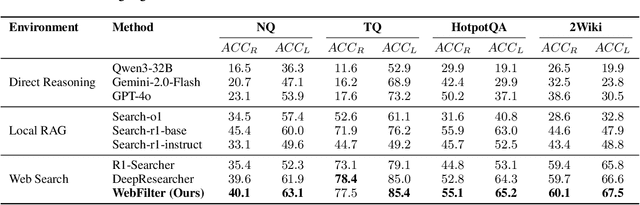
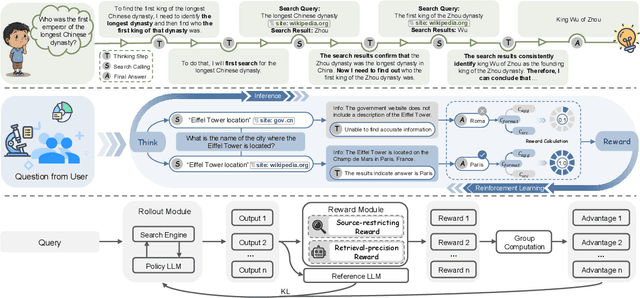
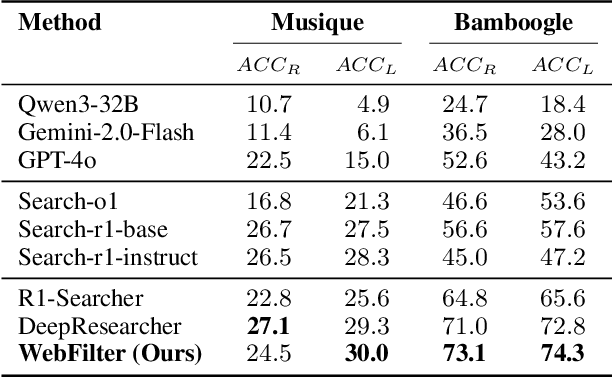
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.