 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment
May 20, 2026Adapting Large Language Models (LLMs) to specialized domains typically incurs high data and computational overhead. While prior efficiency efforts have largely treated data selection and parameter-efficient fine-tuning as isolated processes, our empirical analysis suggests they may be intrinsically coupled. We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation, acting as keys that unlock specific data patterns. Building on this observation, we propose From Parameters to Data (P2D), a unified framework that leverages these task-sensitive attention heads as a dual compass for both sample mining and structural pruning. To rigorously quantify the total pipeline cost, we introduce the Alignment Efficiency Ratio (AER) metric for both selection latency and training time. Mechanistically, P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data, establishing a synergistic pipeline. Empirically, by updating merely 10% of attention heads on 10% of the data, P2D achieves an 8.3 pp performance gain over strong baselines and delivers a 7.0x end-to-end time speedup. These results validate that precise parameter-data synchronization eliminates redundancy, offering a new paradigm for efficient alignment.
TabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
May 06, 2026Foundation models have established unified representations for natural language processing, yet this paradigm remains largely unexplored for tabular data. Existing methods face fundamental limitations: LLM-based approaches lack retrieval-compatible vector outputs, whereas text embedding models often fail to capture tabular structure and numerical semantics. To bridge this gap, we first introduce the Tabular Embedding Benchmark (TabBench), a comprehensive suite designed to evaluate the tabular understanding capability of embedding models. We then propose TabEmbed, the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, TabEmbed leverages large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances. Experimental results on TabBench demonstrate that TabEmbed significantly outperforms state-of-the-art text embedding models, establishing a new baseline for universal tabular representation learning. Code and datasets are publicly available at https://github.com/qiangminjie27/TabEmbed and https://huggingface.co/datasets/qiangminjie27/TabBench.
KMLP: A Scalable Hybrid Architecture for Web-Scale Tabular Data Modeling
Feb 26, 2026Predictive modeling on web-scale tabular data with billions of instances and hundreds of heterogeneous numerical features faces significant scalability challenges. These features exhibit anisotropy, heavy-tailed distributions, and non-stationarity, creating bottlenecks for models like Gradient Boosting Decision Trees and requiring laborious manual feature engineering. We introduce KMLP, a hybrid deep architecture integrating a shallow Kolmogorov-Arnold Network (KAN) front-end with a Gated Multilayer Perceptron (gMLP) backbone. The KAN front-end uses learnable activation functions to automatically model complex non-linear transformations for each feature, while the gMLP backbone captures high-order interactions. Experiments on public benchmarks and an industrial dataset with billions of samples show KMLP achieves state-of-the-art performance, with advantages over baselines like GBDTs increasing at larger scales, validating KMLP as a scalable deep learning paradigm for large-scale web tabular data.
Improved Personalized Headline Generation via Denoising Fake Interests from Implicit Feedback
Aug 10, 2025Accurate personalized headline generation hinges on precisely capturing user interests from historical behaviors. However, existing methods neglect personalized-irrelevant click noise in entire historical clickstreams, which may lead to hallucinated headlines that deviate from genuine user preferences. In this paper, we reveal the detrimental impact of click noise on personalized generation quality through rigorous analysis in both user and news dimensions. Based on these insights, we propose a novel Personalized Headline Generation framework via Denoising Fake Interests from Implicit Feedback (PHG-DIF). PHG-DIF first employs dual-stage filtering to effectively remove clickstream noise, identified by short dwell times and abnormal click bursts, and then leverages multi-level temporal fusion to dynamically model users' evolving and multi-faceted interests for precise profiling. Moreover, we release DT-PENS, a new benchmark dataset comprising the click behavior of 1,000 carefully curated users and nearly 10,000 annotated personalized headlines with historical dwell time annotations. Extensive experiments demonstrate that PHG-DIF substantially mitigates the adverse effects of click noise and significantly improves headline quality, achieving state-of-the-art (SOTA) results on DT-PENS. Our framework implementation and dataset are available at https://github.com/liukejin-up/PHG-DIF.
* Accepted by the 34th ACM International Conference on Information and Knowledge Management (CIKM '25), Full Research Papers track
ALPS: Attention Localization and Pruning Strategy for Efficient Alignment of Large Language Models
May 24, 2025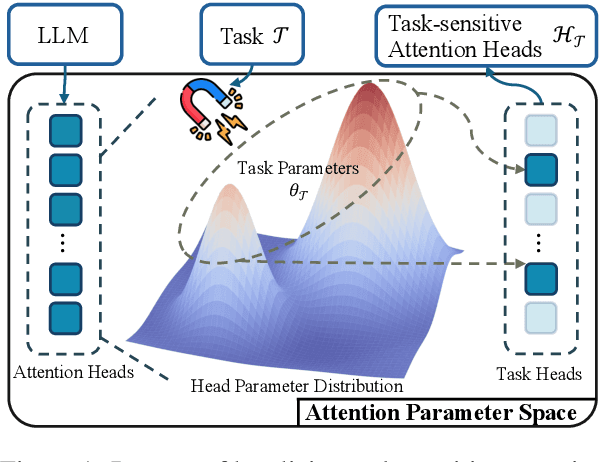
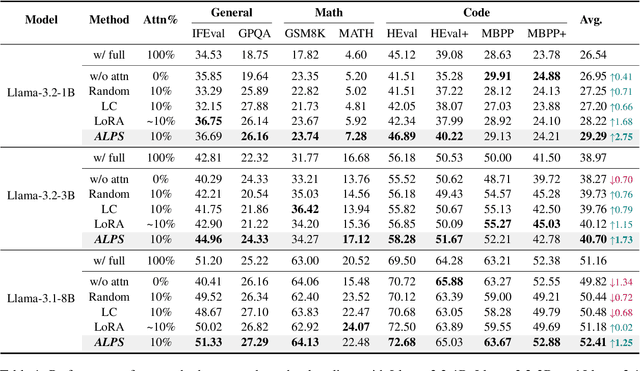

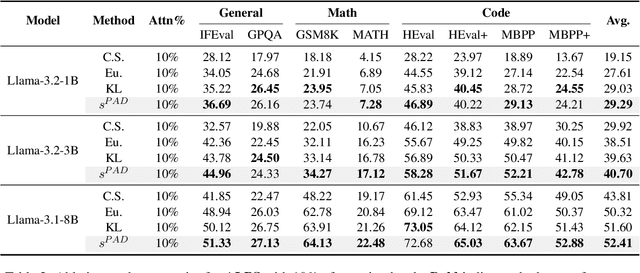
Aligning general-purpose large language models (LLMs) to downstream tasks often incurs significant costs, including constructing task-specific instruction pairs and extensive training adjustments. Prior research has explored various avenues to enhance alignment efficiency, primarily through minimal-data training or data-driven activations to identify key attention heads. However, these approaches inherently introduce data dependency, which hinders generalization and reusability. To address this issue and enhance model alignment efficiency, we propose the \textit{\textbf{A}ttention \textbf{L}ocalization and \textbf{P}runing \textbf{S}trategy (\textbf{ALPS})}, an efficient algorithm that localizes the most task-sensitive attention heads and prunes by restricting attention training updates to these heads, thereby reducing alignment costs. Experimental results demonstrate that our method activates only \textbf{10\%} of attention parameters during fine-tuning while achieving a \textbf{2\%} performance improvement over baselines on three tasks. Moreover, the identified task-specific heads are transferable across datasets and mitigate knowledge forgetting. Our work and findings provide a novel perspective on efficient LLM alignment.
Beyond Tree Models: A Hybrid Model of KAN and gMLP for Large-Scale Financial Tabular Data
Dec 03, 2024



Tabular data plays a critical role in real-world financial scenarios. Traditionally, tree models have dominated in handling tabular data. However, financial datasets in the industry often encounter some challenges, such as data heterogeneity, the predominance of numerical features and the large scale of the data, which can range from tens of millions to hundreds of millions of records. These challenges can lead to significant memory and computational issues when using tree-based models. Consequently, there is a growing need for neural network-based solutions that can outperform these models. In this paper, we introduce TKGMLP, an hybrid network for tabular data that combines shallow Kolmogorov Arnold Networks with Gated Multilayer Perceptron. This model leverages the strengths of both architectures to improve performance and scalability. We validate TKGMLP on a real-world credit scoring dataset, where it achieves state-of-the-art results and outperforms current benchmarks. Furthermore, our findings demonstrate that the model continues to improve as the dataset size increases, making it highly scalable. Additionally, we propose a novel feature encoding method for numerical data, specifically designed to address the predominance of numerical features in financial datasets. The integration of this feature encoding method within TKGMLP significantly improves prediction accuracy. This research not only advances table prediction technology but also offers a practical and effective solution for handling large-scale numerical tabular data in various industrial applications.
Ultra-imbalanced classification guided by statistical information
Sep 06, 2024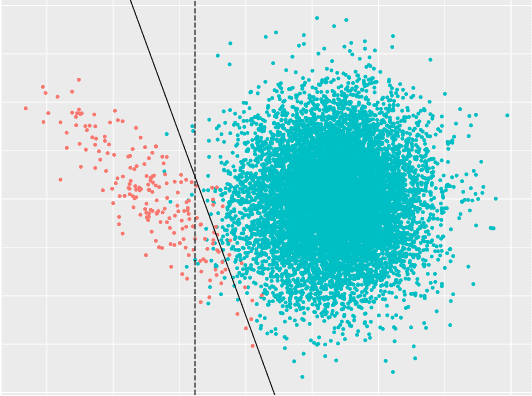
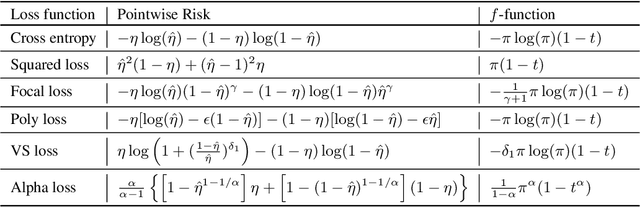
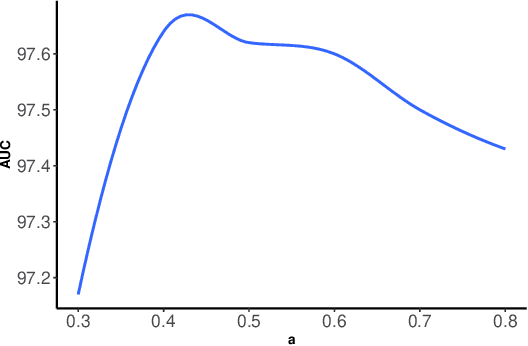
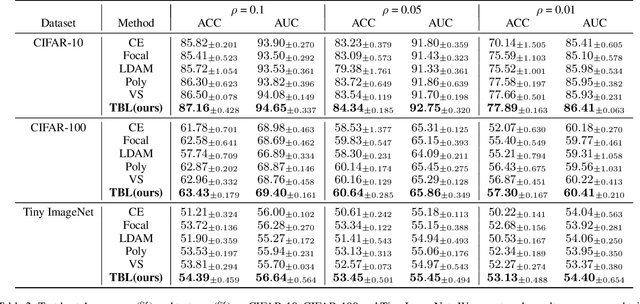
Imbalanced data are frequently encountered in real-world classification tasks. Previous works on imbalanced learning mostly focused on learning with a minority class of few samples. However, the notion of imbalance also applies to cases where the minority class contains abundant samples, which is usually the case for industrial applications like fraud detection in the area of financial risk management. In this paper, we take a population-level approach to imbalanced learning by proposing a new formulation called \emph{ultra-imbalanced classification} (UIC). Under UIC, loss functions behave differently even if infinite amount of training samples are available. To understand the intrinsic difficulty of UIC problems, we borrow ideas from information theory and establish a framework to compare different loss functions through the lens of statistical information. A novel learning objective termed Tunable Boosting Loss is developed which is provably resistant against data imbalance under UIC, as well as being empirically efficient verified by extensive experimental studies on both public and industrial datasets.
Self-supervision meets kernel graph neural models: From architecture to augmentations
Oct 17, 2023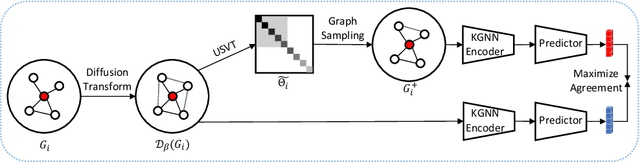
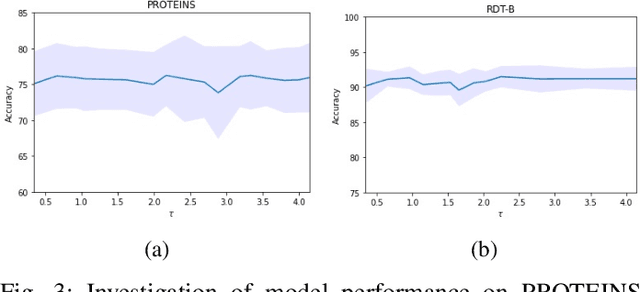
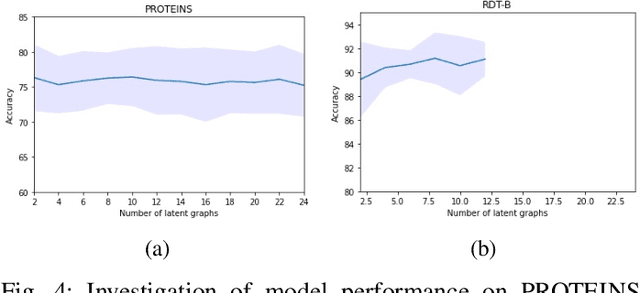
Graph representation learning has now become the de facto standard when handling graph-structured data, with the framework of message-passing graph neural networks (MPNN) being the most prevailing algorithmic tool. Despite its popularity, the family of MPNNs suffers from several drawbacks such as transparency and expressivity. Recently, the idea of designing neural models on graphs using the theory of graph kernels has emerged as a more transparent as well as sometimes more expressive alternative to MPNNs known as kernel graph neural networks (KGNNs). Developments on KGNNs are currently a nascent field of research, leaving several challenges from algorithmic design and adaptation to other learning paradigms such as self-supervised learning. In this paper, we improve the design and learning of KGNNs. Firstly, we extend the algorithmic formulation of KGNNs by allowing a more flexible graph-level similarity definition that encompasses former proposals like random walk graph kernel, as well as providing a smoother optimization objective that alleviates the need of introducing combinatorial learning procedures. Secondly, we enhance KGNNs through the lens of self-supervision via developing a novel structure-preserving graph data augmentation method called latent graph augmentation (LGA). Finally, we perform extensive empirical evaluations to demonstrate the efficacy of our proposed mechanisms. Experimental results over benchmark datasets suggest that our proposed model achieves competitive performance that is comparable to or sometimes outperforming state-of-the-art graph representation learning frameworks with or without self-supervision on graph classification tasks. Comparisons against other previously established graph data augmentation methods verify that the proposed LGA augmentation scheme captures better semantics of graph-level invariance.