 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-Aware Active Knowledge Acquisition for Emotional Support Dialogue
May 28, 2026Emotional support plays an important role in dialogue systems, and its success depends on adapting to a user's evolving and implicit needs across multi-turn interactions while leveraging the strong reasoning capacity of large language models. However, since signals about user needs are often weak, indirect, and can only be disambiguated through multi-turn interaction, existing emotional support methods often struggle to acquire and generalize relevant conversational knowledge efficiently. To bridge this gap, we introduce User-Aware Active Knowledge Acquisition (UKA), a gradient-free active dialogue learning framework that explicitly represents uncertainty about user needs and incorporates active learning into both knowledge acquisition and response selection.We propose a Theory-of-Mind uncertainty estimation mechanism that allows the model to prioritize responses, thereby eliciting more informative user feedback. UKA is capable of efficiently exploring user-aligned conversational knowledge during training while maintaining robustness at test time. Experiments across multiple dialogue benchmarks and model architectures demonstrate that our approach consistently outperforms strong baselines in dialogue quality and user alignment.
Safer Trajectory Planning with CBF-guided Diffusion Model for Unmanned Aerial Vehicles
Apr 19, 2026Safe and agile trajectory planning is essential for autonomous systems, especially during complex aerobatic maneuvers. Motivated by the recent success of diffusion models in generative tasks, this paper introduces AeroTrajGen, a novel framework for diffusion-based trajectory generation that incorporates control barrier function (CBF)-guided sampling during inference, specifically designed for unmanned aerial vehicles (UAVs). The proposed CBF-guided sampling addresses two critical challenges: (1) mitigating the inherent unpredictability and potential safety violations of diffusion models, and (2) reducing reliance on extensively safety-verified training data. During the reverse diffusion process, CBF-based guidance ensures collision-free trajectories by seamlessly integrating safety constraint gradients with the diffusion model's score function. The model features an obstacle-aware diffusion transformer architecture with multi-modal conditioning, including trajectory history, obstacles, maneuver styles, and goal, enabling the generation of smooth, highly agile trajectories across 14 distinct aerobatic maneuvers. Trained on a dataset of 2,000 expert demonstrations, AeroTrajGen is rigorously evaluated in simulation under multi-obstacle environments. Simulation results demonstrate that CBF-guided sampling reduces collision rates by 94.7% compared to unguided diffusion baselines, while preserving trajectory agility and diversity. Our code is open-sourced at https://github.com/RoboticsPolyu/CBF-DMP.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Integrated Planning and Control on Manifolds: Factor Graph Representation and Toolkit
Oct 05, 2025Model predictive control (MPC) faces significant limitations when applied to systems evolving on nonlinear manifolds, such as robotic attitude dynamics and constrained motion planning, where traditional Euclidean formulations struggle with singularities, over-parameterization, and poor convergence. To overcome these challenges, this paper introduces FactorMPC, a factor-graph based MPC toolkit that unifies system dynamics, constraints, and objectives into a modular, user-friendly, and efficient optimization structure. Our approach natively supports manifold-valued states with Gaussian uncertainties modeled in tangent spaces. By exploiting the sparsity and probabilistic structure of factor graphs, the toolkit achieves real-time performance even for high-dimensional systems with complex constraints. The velocity-extended on-manifold control barrier function (CBF)-based obstacle avoidance factors are designed for safety-critical applications. By bridging graphical models with safety-critical MPC, our work offers a scalable and geometrically consistent framework for integrated planning and control. The simulations and experimental results on the quadrotor demonstrate superior trajectory tracking and obstacle avoidance performance compared to baseline methods. To foster research reproducibility, we have provided open-source implementation offering plug-and-play factors.
Hierarchical Balance Packing: Towards Efficient Supervised Fine-tuning for Long-Context LLM
Mar 10, 2025Training Long-Context Large Language Models (LLMs) is challenging, as hybrid training with long-context and short-context data often leads to workload imbalances. Existing works mainly use data packing to alleviate this issue but fail to consider imbalanced attention computation and wasted communication overhead. This paper proposes Hierarchical Balance Packing (HBP), which designs a novel batch-construction method and training recipe to address those inefficiencies. In particular, the HBP constructs multi-level data packing groups, each optimized with a distinct packing length. It assigns training samples to their optimal groups and configures each group with the most effective settings, including sequential parallelism degree and gradient checkpointing configuration. To effectively utilize multi-level groups of data, we design a dynamic training pipeline specifically tailored to HBP, including curriculum learning, adaptive sequential parallelism, and stable loss. Our extensive experiments demonstrate that our method significantly reduces training time over multiple datasets and open-source models while maintaining strong performance. For the largest DeepSeek-V2 (236B) MOE model, our method speeds up the training by 2.4$\times$ with competitive performance.
Beyond Tree Models: A Hybrid Model of KAN and gMLP for Large-Scale Financial Tabular Data
Dec 03, 2024



Tabular data plays a critical role in real-world financial scenarios. Traditionally, tree models have dominated in handling tabular data. However, financial datasets in the industry often encounter some challenges, such as data heterogeneity, the predominance of numerical features and the large scale of the data, which can range from tens of millions to hundreds of millions of records. These challenges can lead to significant memory and computational issues when using tree-based models. Consequently, there is a growing need for neural network-based solutions that can outperform these models. In this paper, we introduce TKGMLP, an hybrid network for tabular data that combines shallow Kolmogorov Arnold Networks with Gated Multilayer Perceptron. This model leverages the strengths of both architectures to improve performance and scalability. We validate TKGMLP on a real-world credit scoring dataset, where it achieves state-of-the-art results and outperforms current benchmarks. Furthermore, our findings demonstrate that the model continues to improve as the dataset size increases, making it highly scalable. Additionally, we propose a novel feature encoding method for numerical data, specifically designed to address the predominance of numerical features in financial datasets. The integration of this feature encoding method within TKGMLP significantly improves prediction accuracy. This research not only advances table prediction technology but also offers a practical and effective solution for handling large-scale numerical tabular data in various industrial applications.
VIVID-10M: A Dataset and Baseline for Versatile and Interactive Video Local Editing
Nov 22, 2024



Diffusion-based image editing models have made remarkable progress in recent years. However, achieving high-quality video editing remains a significant challenge. One major hurdle is the absence of open-source, large-scale video editing datasets based on real-world data, as constructing such datasets is both time-consuming and costly. Moreover, video data requires a significantly larger number of tokens for representation, which substantially increases the training costs for video editing models. Lastly, current video editing models offer limited interactivity, often making it difficult for users to express their editing requirements effectively in a single attempt. To address these challenges, this paper introduces a dataset VIVID-10M and a baseline model VIVID. VIVID-10M is the first large-scale hybrid image-video local editing dataset aimed at reducing data construction and model training costs, which comprises 9.7M samples that encompass a wide range of video editing tasks. VIVID is a Versatile and Interactive VIdeo local eDiting model trained on VIVID-10M, which supports entity addition, modification, and deletion. At its core, a keyframe-guided interactive video editing mechanism is proposed, enabling users to iteratively edit keyframes and propagate it to other frames, thereby reducing latency in achieving desired outcomes. Extensive experimental evaluations show that our approach achieves state-of-the-art performance in video local editing, surpassing baseline methods in both automated metrics and user studies. The VIVID-10M dataset and the VIVID editing model will be available at \url{https://inkosizhong.github.io/VIVID/}.
OmniBal: Towards Fast Instruct-tuning for Vision-Language Models via Omniverse Computation Balance
Jul 30, 2024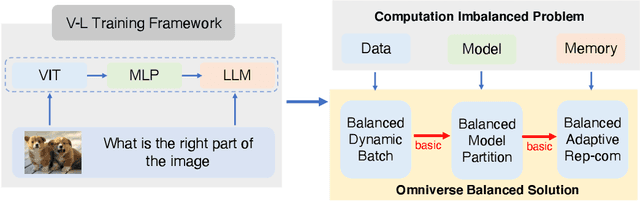

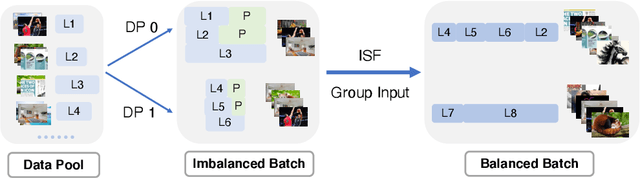

Recently, vision-language instruct-tuning models have made significant progress due to their more comprehensive understanding of the world. In this work, we discovered that large-scale 3D parallel training on those models leads to an imbalanced computation load across different devices. The vision and language parts are inherently heterogeneous: their data distribution and model architecture differ significantly, which affects distributed training efficiency. We rebalanced the computational loads from data, model, and memory perspectives to address this issue, achieving more balanced computation across devices. These three components are not independent but are closely connected, forming an omniverse balanced training framework. Specifically, for the data, we grouped instances into new balanced mini-batches within and across devices. For the model, we employed a search-based method to achieve a more balanced partitioning. For memory optimization, we adaptively adjusted the re-computation strategy for each partition to utilize the available memory fully. We conducted extensive experiments to validate the effectiveness of our method. Compared with the open-source training code of InternVL-Chat, we significantly reduced GPU days, achieving about 1.8x speed-up. Our method's efficacy and generalizability were further demonstrated across various models and datasets. Codes will be released at https://github.com/ModelTC/OmniBal.
Enhancing Few-Shot Stock Trend Prediction with Large Language Models
Jul 12, 2024



The goal of stock trend prediction is to forecast future market movements for informed investment decisions. Existing methods mostly focus on predicting stock trends with supervised models trained on extensive annotated data. However, human annotation can be resource-intensive and the annotated data are not readily available. Inspired by the impressive few-shot capability of Large Language Models (LLMs), we propose using LLMs in a few-shot setting to overcome the scarcity of labeled data and make prediction more feasible to investors. Previous works typically merge multiple financial news for predicting stock trends, causing two significant problems when using LLMs: (1) Merged news contains noise, and (2) it may exceed LLMs' input limits, leading to performance degradation. To overcome these issues, we propose a two-step method 'denoising-then-voting'. Specifically, we introduce an `Irrelevant' category, and predict stock trends for individual news instead of merged news. Then we aggregate these predictions using majority voting. The proposed method offers two advantages: (1) Classifying noisy news as irrelevant removes its impact on the final prediction. (2) Predicting for individual news mitigates LLMs' input length limits. Our method achieves 66.59% accuracy in S&P 500, 62.17% in CSI-100, and 61.17% in HK stock prediction, outperforming the standard few-shot counterparts by around 7%, 4%, and 4%. Furthermore, our proposed method performs on par with state-of-the-art supervised methods.
DMAT: A Dynamic Mask-Aware Transformer for Human De-occlusion
Feb 07, 2024Human de-occlusion, which aims to infer the appearance of invisible human parts from an occluded image, has great value in many human-related tasks, such as person re-id, and intention inference. To address this task, this paper proposes a dynamic mask-aware transformer (DMAT), which dynamically augments information from human regions and weakens that from occlusion. First, to enhance token representation, we design an expanded convolution head with enlarged kernels, which captures more local valid context and mitigates the influence of surrounding occlusion. To concentrate on the visible human parts, we propose a novel dynamic multi-head human-mask guided attention mechanism through integrating multiple masks, which can prevent the de-occluded regions from assimilating to the background. Besides, a region upsampling strategy is utilized to alleviate the impact of occlusion on interpolated images. During model learning, an amodal loss is developed to further emphasize the recovery effect of human regions, which also refines the model's convergence. Extensive experiments on the AHP dataset demonstrate its superior performance compared to recent state-of-the-art methods.