 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Level Framework for Multi-Objective Hypergraph Partitioning: Combining Minimum Spanning Tree and Proximal Gradient
Sep 26, 2025
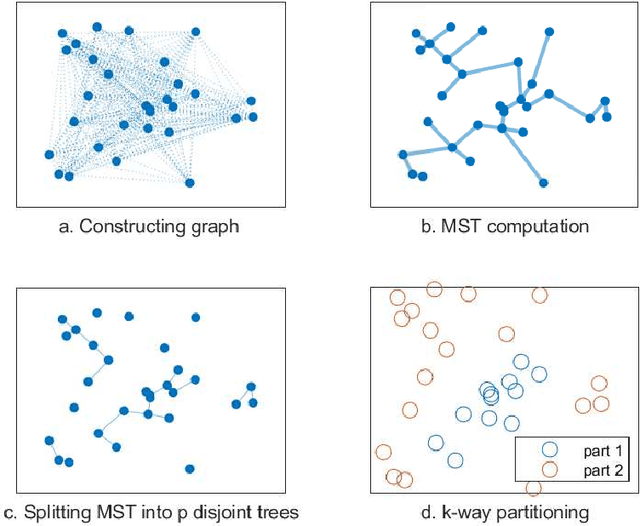

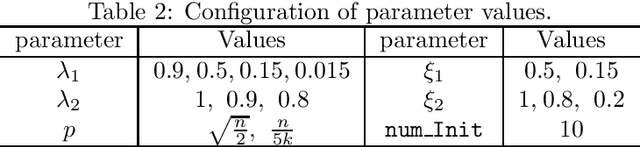
This paper proposes an efficient hypergraph partitioning framework based on a novel multi-objective non-convex constrained relaxation model. A modified accelerated proximal gradient algorithm is employed to generate diverse $k$-dimensional vertex features to avoid local optima and enhance partition quality. Two MST-based strategies are designed for different data scales: for small-scale data, the Prim algorithm constructs a minimum spanning tree followed by pruning and clustering; for large-scale data, a subset of representative nodes is selected to build a smaller MST, while the remaining nodes are assigned accordingly to reduce complexity. To further improve partitioning results, refinement strategies including greedy migration, swapping, and recursive MST-based clustering are introduced for partitions. Experimental results on public benchmark sets demonstrate that the proposed algorithm achieves reductions in cut size of approximately 2\%--5\% on average compared to KaHyPar in 2, 3, and 4-way partitioning, with improvements of up to 35\% on specific instances. Particularly on weighted vertex sets, our algorithm outperforms state-of-the-art partitioners including KaHyPar, hMetis, Mt-KaHyPar, and K-SpecPart, highlighting its superior partitioning quality and competitiveness. Furthermore, the proposed refinement strategy improves hMetis partitions by up to 16\%. A comprehensive evaluation based on virtual instance methodology and parameter sensitivity analysis validates the algorithm's competitiveness and characterizes its performance trade-offs.
Hierarchical Balance Packing: Towards Efficient Supervised Fine-tuning for Long-Context LLM
Mar 10, 2025Training Long-Context Large Language Models (LLMs) is challenging, as hybrid training with long-context and short-context data often leads to workload imbalances. Existing works mainly use data packing to alleviate this issue but fail to consider imbalanced attention computation and wasted communication overhead. This paper proposes Hierarchical Balance Packing (HBP), which designs a novel batch-construction method and training recipe to address those inefficiencies. In particular, the HBP constructs multi-level data packing groups, each optimized with a distinct packing length. It assigns training samples to their optimal groups and configures each group with the most effective settings, including sequential parallelism degree and gradient checkpointing configuration. To effectively utilize multi-level groups of data, we design a dynamic training pipeline specifically tailored to HBP, including curriculum learning, adaptive sequential parallelism, and stable loss. Our extensive experiments demonstrate that our method significantly reduces training time over multiple datasets and open-source models while maintaining strong performance. For the largest DeepSeek-V2 (236B) MOE model, our method speeds up the training by 2.4$\times$ with competitive performance.
OmniBal: Towards Fast Instruct-tuning for Vision-Language Models via Omniverse Computation Balance
Jul 30, 2024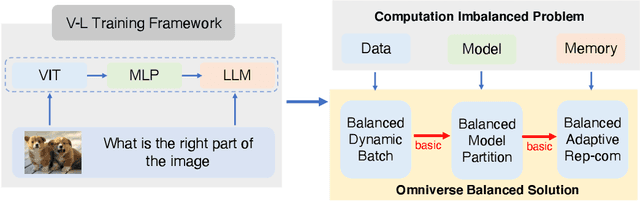

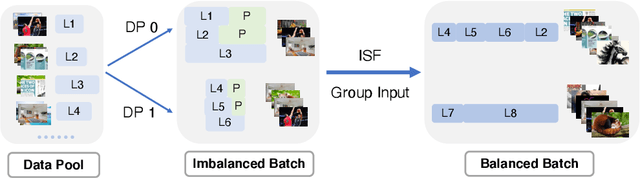

Recently, vision-language instruct-tuning models have made significant progress due to their more comprehensive understanding of the world. In this work, we discovered that large-scale 3D parallel training on those models leads to an imbalanced computation load across different devices. The vision and language parts are inherently heterogeneous: their data distribution and model architecture differ significantly, which affects distributed training efficiency. We rebalanced the computational loads from data, model, and memory perspectives to address this issue, achieving more balanced computation across devices. These three components are not independent but are closely connected, forming an omniverse balanced training framework. Specifically, for the data, we grouped instances into new balanced mini-batches within and across devices. For the model, we employed a search-based method to achieve a more balanced partitioning. For memory optimization, we adaptively adjusted the re-computation strategy for each partition to utilize the available memory fully. We conducted extensive experiments to validate the effectiveness of our method. Compared with the open-source training code of InternVL-Chat, we significantly reduced GPU days, achieving about 1.8x speed-up. Our method's efficacy and generalizability were further demonstrated across various models and datasets. Codes will be released at https://github.com/ModelTC/OmniBal.
Is Next Token Prediction Sufficient for GPT? Exploration on Code Logic Comprehension
Apr 13, 2024



Large language models (LLMs) has experienced exponential growth, they demonstrate remarkable performance across various tasks. Notwithstanding, contemporary research primarily centers on enhancing the size and quality of pretraining data, still utilizing the next token prediction task on autoregressive transformer model structure. The efficacy of this task in truly facilitating the model's comprehension of code logic remains questionable, we speculate that it still interprets code as mere text, while human emphasizes the underlying logical knowledge. In order to prove it, we introduce a new task, "Logically Equivalent Code Selection," which necessitates the selection of logically equivalent code from a candidate set, given a query code. Our experimental findings indicate that current LLMs underperform in this task, since they understand code by unordered bag of keywords. To ameliorate their performance, we propose an advanced pretraining task, "Next Token Prediction+". This task aims to modify the sentence embedding distribution of the LLM without sacrificing its generative capabilities. Our experimental results reveal that following this pretraining, both Code Llama and StarCoder, the prevalent code domain pretraining models, display significant improvements on our logically equivalent code selection task and the code completion task.
2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024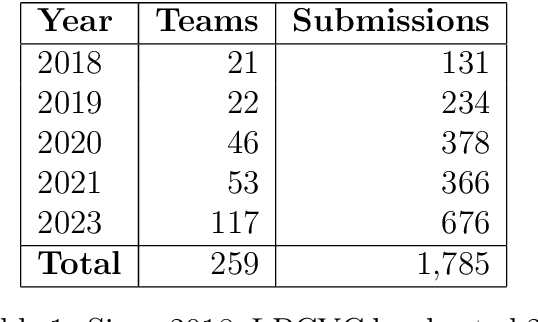
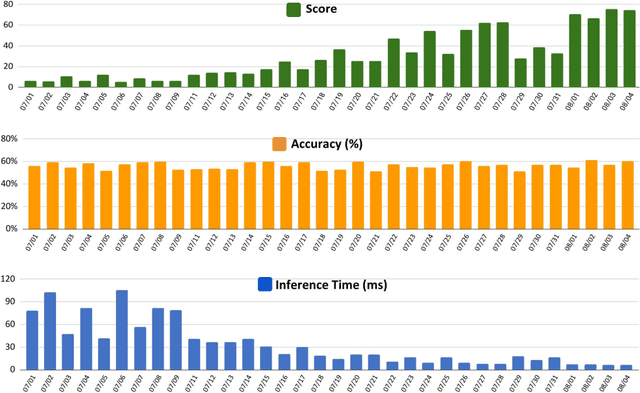

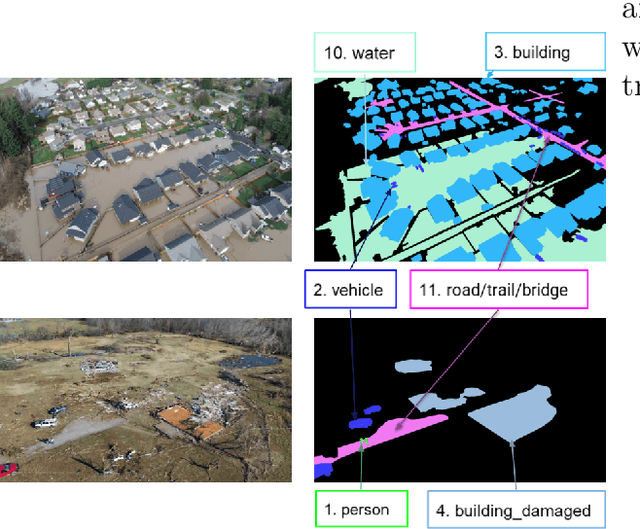
This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
Rethinking the Instruction Quality: LIFT is What You Need
Dec 27, 2023Instruction tuning, a specialized technique to enhance large language model (LLM) performance via instruction datasets, relies heavily on the quality of employed data. Existing quality improvement methods alter instruction data through dataset expansion or curation. However, the expansion method risks data redundancy, potentially compromising LLM performance, while the curation approach confines the LLM's potential to the original dataset. Our aim is to surpass the original data quality without encountering these shortcomings. To achieve this, we propose LIFT (LLM Instruction Fusion Transfer), a novel and versatile paradigm designed to elevate the instruction quality to new heights. LIFT strategically broadens data distribution to encompass more high-quality subspaces and eliminates redundancy, concentrating on high-quality segments across overall data subspaces. Experimental results demonstrate that, even with a limited quantity of high-quality instruction data selected by our paradigm, LLMs not only consistently uphold robust performance across various tasks but also surpass some state-of-the-art results, highlighting the significant improvement in instruction quality achieved by our paradigm.
SUT: Active Defects Probing for Transcompiler Models
Oct 22, 2023



Automatic Program translation has enormous application value and hence has been attracting significant interest from AI researchers. However, we observe that current program translation models still make elementary syntax errors, particularly, when the target language does not have syntax elements in the source language. Metrics like BLUE, CodeBLUE and computation accuracy may not expose these issues. In this paper we introduce a new metrics for programming language translation and these metrics address these basic syntax errors. We develop a novel active defects probing suite called Syntactic Unit Tests (SUT) which includes a highly interpretable evaluation harness for accuracy and test scoring. Experiments have shown that even powerful models like ChatGPT still make mistakes on these basic unit tests. Specifically, compared to previous program translation task evaluation dataset, its pass rate on our unit tests has decreased by 26.15%. Further our evaluation harness reveal syntactic element errors in which these models exhibit deficiencies.
Program Translation via Code Distillation
Oct 17, 2023



Software version migration and program translation are an important and costly part of the lifecycle of large codebases. Traditional machine translation relies on parallel corpora for supervised translation, which is not feasible for program translation due to a dearth of aligned data. Recent unsupervised neural machine translation techniques have overcome data limitations by included techniques such as back translation and low level compiler intermediate representations (IR). These methods face significant challenges due to the noise in code snippet alignment and the diversity of IRs respectively. In this paper we propose a novel model called Code Distillation (CoDist) whereby we capture the semantic and structural equivalence of code in a language agnostic intermediate representation. Distilled code serves as a translation pivot for any programming language, leading by construction to parallel corpora which scale to all available source code by simply applying the distillation compiler. We demonstrate that our approach achieves state-of-the-art performance on CodeXGLUE and TransCoder GeeksForGeeks translation benchmarks, with an average absolute increase of 12.7% on the TransCoder GeeksforGeeks translation benchmark compare to TransCoder-ST.
SysNoise: Exploring and Benchmarking Training-Deployment System Inconsistency
Jul 01, 2023Extensive studies have shown that deep learning models are vulnerable to adversarial and natural noises, yet little is known about model robustness on noises caused by different system implementations. In this paper, we for the first time introduce SysNoise, a frequently occurred but often overlooked noise in the deep learning training-deployment cycle. In particular, SysNoise happens when the source training system switches to a disparate target system in deployments, where various tiny system mismatch adds up to a non-negligible difference. We first identify and classify SysNoise into three categories based on the inference stage; we then build a holistic benchmark to quantitatively measure the impact of SysNoise on 20+ models, comprehending image classification, object detection, instance segmentation and natural language processing tasks. Our extensive experiments revealed that SysNoise could bring certain impacts on model robustness across different tasks and common mitigations like data augmentation and adversarial training show limited effects on it. Together, our findings open a new research topic and we hope this work will raise research attention to deep learning deployment systems accounting for model performance. We have open-sourced the benchmark and framework at https://modeltc.github.io/systemnoise_web.
* Proceedings of Machine Learning and Systems. 2023 Mar 18
The Equalization Losses: Gradient-Driven Training for Long-tailed Object Recognition
Oct 11, 2022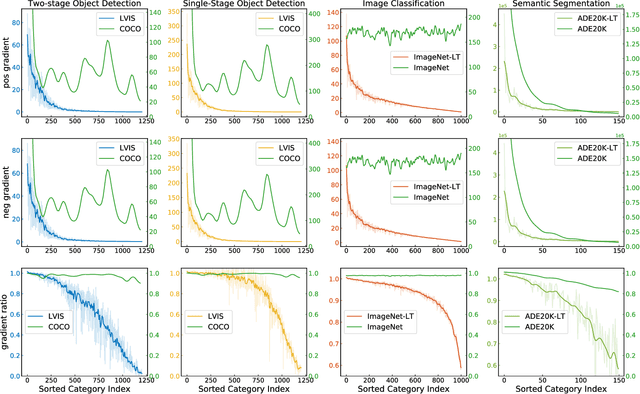
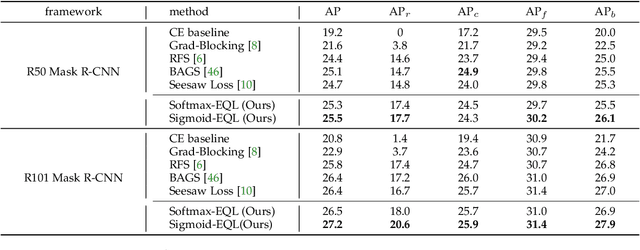

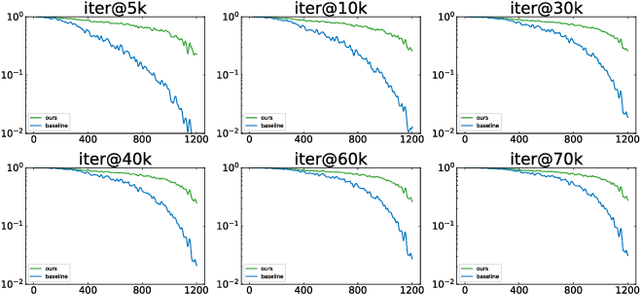
Long-tail distribution is widely spread in real-world applications. Due to the extremely small ratio of instances, tail categories often show inferior accuracy. In this paper, we find such performance bottleneck is mainly caused by the imbalanced gradients, which can be categorized into two parts: (1) positive part, deriving from the samples of the same category, and (2) negative part, contributed by other categories. Based on comprehensive experiments, it is also observed that the gradient ratio of accumulated positives to negatives is a good indicator to measure how balanced a category is trained. Inspired by this, we come up with a gradient-driven training mechanism to tackle the long-tail problem: re-balancing the positive/negative gradients dynamically according to current accumulative gradients, with a unified goal of achieving balance gradient ratios. Taking advantage of the simple and flexible gradient mechanism, we introduce a new family of gradient-driven loss functions, namely equalization losses. We conduct extensive experiments on a wide spectrum of visual tasks, including two-stage/single-stage long-tailed object detection (LVIS), long-tailed image classification (ImageNet-LT, Places-LT, iNaturalist), and long-tailed semantic segmentation (ADE20K). Our method consistently outperforms the baseline models, demonstrating the effectiveness and generalization ability of the proposed equalization losses. Codes will be released at https://github.com/ModelTC/United-Perception.