 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhinoVLA Technical Report
Jun 05, 2026Vision-Language-Action (VLA) models have shown strong potential for robotic manipulation, but real-time deployment on edge hardware remains challenging. In this work, we identify VLM visual and context tokens as a major source of deployment latency: for GEMM-dominated projection operators, computation grows linearly with the number of input tokens when model dimensions are fixed. Motivated by this observation, we propose RhinoVLA, a deployment-oriented VLA model co-designed with the Huixi R1 edge SoC. RhinoVLA adopts a token-efficient Qwen3-VL backbone and a continuous Action Expert, reducing the VLM-side token and computation burden while preserving pretrained multimodal capability. To support cross-robot learning, RhinoVLA further introduces a unified interface that combines View Registry, 72D physical state-action slot space, and robotinstance LoRA, allowing heterogeneous robot observations and action schemas to be aligned under a shared policy. On the deployment side, RhinoVLA is optimized through hardware-aware compilation, mixed-precision execution, and parallel visual encoding. Experiments show that RhinoVLA achieves downstream performance comparable to π0.5 at a similar parameter scale, while reaching 11.69 Hz end-to-end inference on Huixi R1, meeting the 10 Hz real-time closedloop control target. The project will be open-sourced at https://github.com/HuixiAI/RhinoVLA.
STEP: Warm-Started Visuomotor Policies with Spatiotemporal Consistency Prediction
Feb 09, 2026Diffusion policies have recently emerged as a powerful paradigm for visuomotor control in robotic manipulation due to their ability to model the distribution of action sequences and capture multimodality. However, iterative denoising leads to substantial inference latency, limiting control frequency in real-time closed-loop systems. Existing acceleration methods either reduce sampling steps, bypass diffusion through direct prediction, or reuse past actions, but often struggle to jointly preserve action quality and achieve consistently low latency. In this work, we propose STEP, a lightweight spatiotemporal consistency prediction mechanism to construct high-quality warm-start actions that are both distributionally close to the target action and temporally consistent, without compromising the generative capability of the original diffusion policy. Then, we propose a velocity-aware perturbation injection mechanism that adaptively modulates actuation excitation based on temporal action variation to prevent execution stall especially for real-world tasks. We further provide a theoretical analysis showing that the proposed prediction induces a locally contractive mapping, ensuring convergence of action errors during diffusion refinement. We conduct extensive evaluations on nine simulated benchmarks and two real-world tasks. Notably, STEP with 2 steps can achieve an average 21.6% and 27.5% higher success rate than BRIDGER and DDIM on the RoboMimic benchmark and real-world tasks, respectively. These results demonstrate that STEP consistently advances the Pareto frontier of inference latency and success rate over existing methods.
DynSplit-KV: Dynamic Semantic Splitting for KVCache Compression in Efficient Long-Context LLM Inference
Feb 03, 2026Although Key-Value (KV) Cache is essential for efficient large language models (LLMs) inference, its growing memory footprint in long-context scenarios poses a significant bottleneck, making KVCache compression crucial. Current compression methods rely on rigid splitting strategies, such as fixed intervals or pre-defined delimiters. We observe that rigid splitting suffers from significant accuracy degradation (ranging from 5.5% to 55.1%) across different scenarios, owing to the scenario-dependent nature of the semantic boundaries. This highlights the necessity of dynamic semantic splitting to match semantics. To achieve this, we face two challenges. (1) Improper delimiter selection misaligns semantics with the KVCache, resulting in 28.6% accuracy loss. (2) Variable-length blocks after splitting introduce over 73.1% additional inference overhead. To address the above challenges, we propose DynSplit-KV, a KVCache compression method that dynamically identifies delimiters for splitting. We propose: (1) a dynamic importance-aware delimiter selection strategy, improving accuracy by 49.9%. (2) A uniform mapping strategy that transforms variable-length semantic blocks into a fixed-length format, reducing inference overhead by 4.9x. Experiments show that DynSplit-KV achieves the highest accuracy, 2.2x speedup compared with FlashAttention and 2.6x peak memory reduction in long-context scenarios.
Speculative Decoding for Verilog: Speed and Quality, All in One
Mar 18, 2025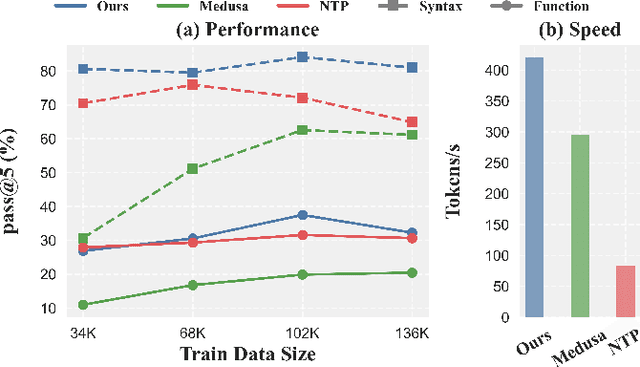
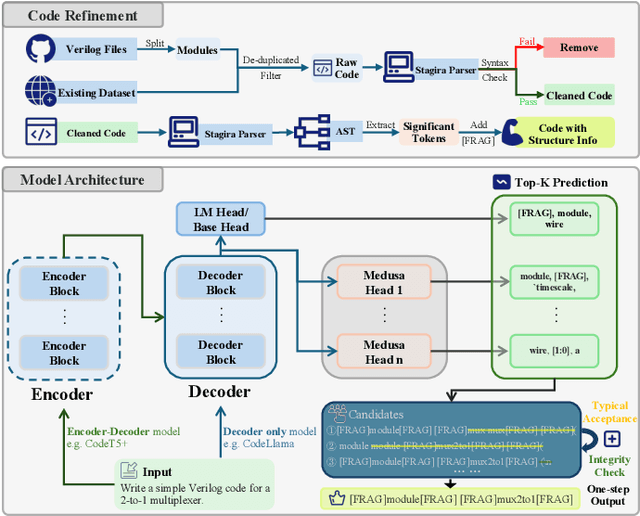
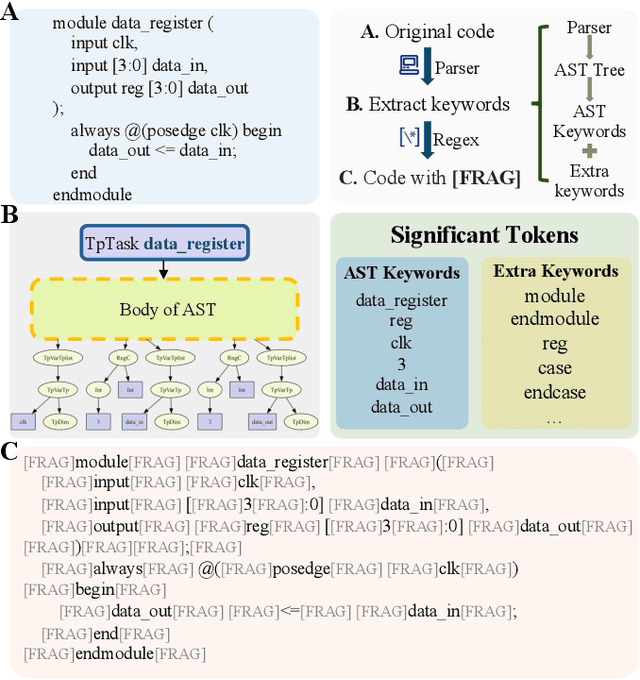
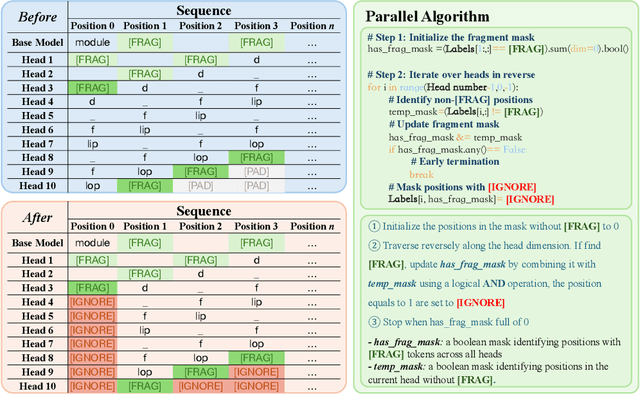
The rapid advancement of large language models (LLMs) has revolutionized code generation tasks across various programming languages. However, the unique characteristics of programming languages, particularly those like Verilog with specific syntax and lower representation in training datasets, pose significant challenges for conventional tokenization and decoding approaches. In this paper, we introduce a novel application of speculative decoding for Verilog code generation, showing that it can improve both inference speed and output quality, effectively achieving speed and quality all in one. Unlike standard LLM tokenization schemes, which often fragment meaningful code structures, our approach aligns decoding stops with syntactically significant tokens, making it easier for models to learn the token distribution. This refinement addresses inherent tokenization issues and enhances the model's ability to capture Verilog's logical constructs more effectively. Our experimental results show that our method achieves up to a 5.05x speedup in Verilog code generation and increases pass@10 functional accuracy on RTLLM by up to 17.19% compared to conventional training strategies. These findings highlight speculative decoding as a promising approach to bridge the quality gap in code generation for specialized programming languages.
ROMA: a Read-Only-Memory-based Accelerator for QLoRA-based On-Device LLM
Mar 17, 2025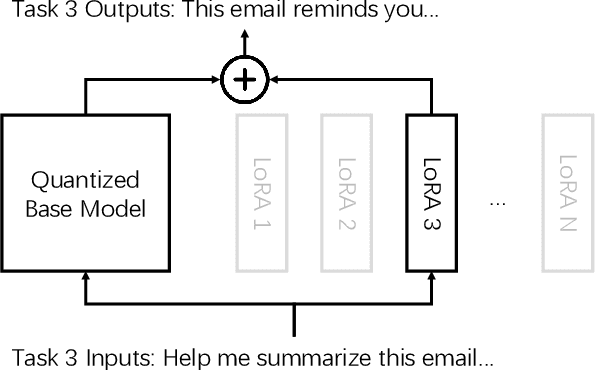
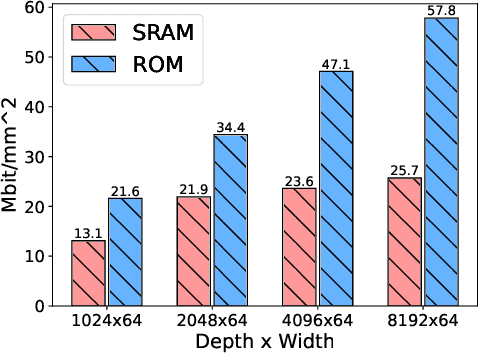
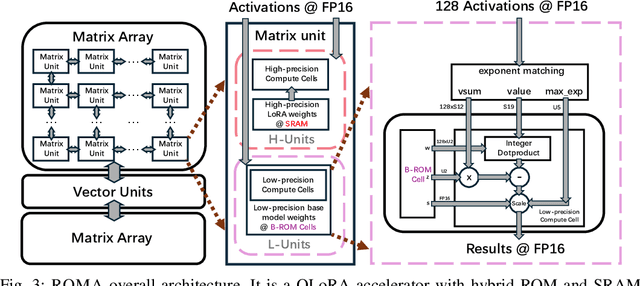
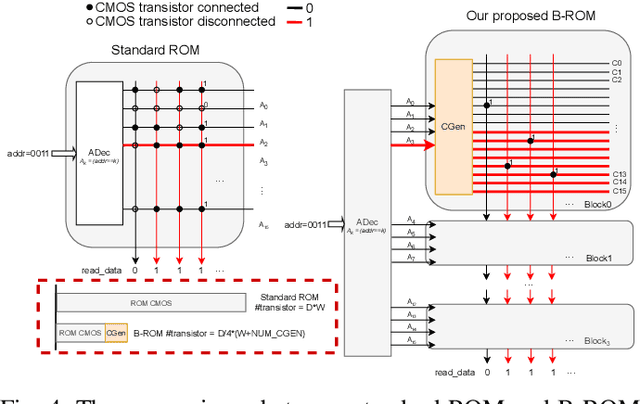
As large language models (LLMs) demonstrate powerful capabilities, deploying them on edge devices has become increasingly crucial, offering advantages in privacy and real-time interaction. QLoRA has emerged as the standard approach for on-device LLMs, leveraging quantized models to reduce memory and computational costs while utilizing LoRA for task-specific adaptability. In this work, we propose ROMA, a QLoRA accelerator with a hybrid storage architecture that uses ROM for quantized base models and SRAM for LoRA weights and KV cache. Our insight is that the quantized base model is stable and converged, making it well-suited for ROM storage. Meanwhile, LoRA modules offer the flexibility to adapt to new data without requiring updates to the base model. To further reduce the area cost of ROM, we introduce a novel B-ROM design and integrate it with the compute unit to form a fused cell for efficient use of chip resources. ROMA can effectively store both a 4-bit 3B and a 2-bit 8B LLaMA model entirely on-chip, achieving a notable generation speed exceeding 20,000 tokens/s without requiring external memory.
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
Mar 13, 2025


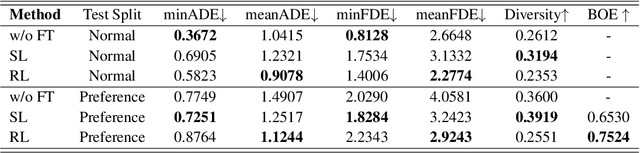
Generating human-like and adaptive trajectories is essential for autonomous driving in dynamic environments. While generative models have shown promise in synthesizing feasible trajectories, they often fail to capture the nuanced variability of human driving styles due to dataset biases and distributional shifts. To address this, we introduce TrajHF, a human feedback-driven finetuning framework for generative trajectory models, designed to align motion planning with diverse driving preferences. TrajHF incorporates multi-conditional denoiser and reinforcement learning with human feedback to refine multi-modal trajectory generation beyond conventional imitation learning. This enables better alignment with human driving preferences while maintaining safety and feasibility constraints. TrajHF achieves PDMS of 93.95 on NavSim benchmark, significantly exceeding other methods. TrajHF sets a new paradigm for personalized and adaptable trajectory generation in autonomous driving.
Hierarchical Balance Packing: Towards Efficient Supervised Fine-tuning for Long-Context LLM
Mar 10, 2025Training Long-Context Large Language Models (LLMs) is challenging, as hybrid training with long-context and short-context data often leads to workload imbalances. Existing works mainly use data packing to alleviate this issue but fail to consider imbalanced attention computation and wasted communication overhead. This paper proposes Hierarchical Balance Packing (HBP), which designs a novel batch-construction method and training recipe to address those inefficiencies. In particular, the HBP constructs multi-level data packing groups, each optimized with a distinct packing length. It assigns training samples to their optimal groups and configures each group with the most effective settings, including sequential parallelism degree and gradient checkpointing configuration. To effectively utilize multi-level groups of data, we design a dynamic training pipeline specifically tailored to HBP, including curriculum learning, adaptive sequential parallelism, and stable loss. Our extensive experiments demonstrate that our method significantly reduces training time over multiple datasets and open-source models while maintaining strong performance. For the largest DeepSeek-V2 (236B) MOE model, our method speeds up the training by 2.4$\times$ with competitive performance.
Automating Energy-Efficient GPU Kernel Generation: A Fast Search-Based Compilation Approach
Nov 28, 2024



Deep Neural Networks (DNNs) have revolutionized various fields, but their deployment on GPUs often leads to significant energy consumption. Unlike existing methods for reducing GPU energy consumption, which are either hardware-inflexible or limited by workload constraints, this paper addresses the problem at the GPU kernel level. We propose a novel search-based compilation method to generate energy-efficient GPU kernels by incorporating energy efficiency into the search process. To accelerate the energy evaluation process, we develop an accurate energy cost model based on high-level kernel features. Furthermore, we introduce a dynamic updating strategy for the energy cost model, reducing the need for on-device energy measurements and accelerating the search process. Our evaluation demonstrates that the proposed approach can generate GPU kernels with up to 21.69% reduced energy consumption while maintaining low latency.
MARCA: Mamba Accelerator with ReConfigurable Architecture
Sep 16, 2024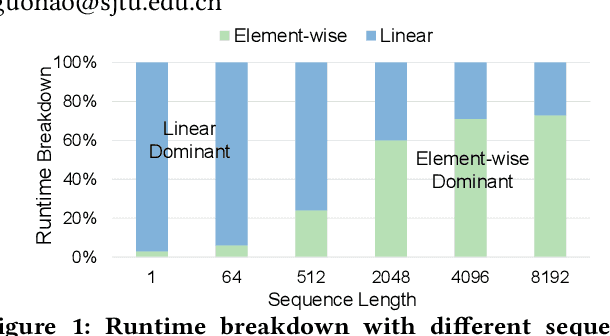
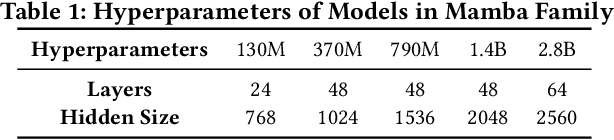

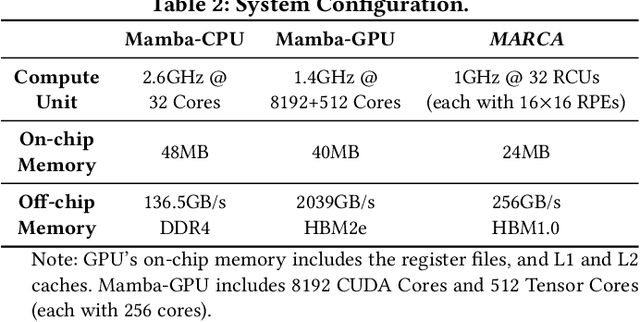
We propose a Mamba accelerator with reconfigurable architecture, MARCA.We propose three novel approaches in this paper. (1) Reduction alternative PE array architecture for both linear and element-wise operations. For linear operations, the reduction tree connected to PE arrays is enabled and executes the reduction operation. For element-wise operations, the reduction tree is disabled and the output bypasses. (2) Reusable nonlinear function unit based on the reconfigurable PE. We decompose the exponential function into element-wise operations and a shift operation by a fast biased exponential algorithm, and the activation function (SiLU) into a range detection and element-wise operations by a piecewise approximation algorithm. Thus, the reconfigurable PEs are reused to execute nonlinear functions with negligible accuracy loss.(3) Intra-operation and inter-operation buffer management strategy. We propose intra-operation buffer management strategy to maximize input data sharing for linear operations within operations, and inter-operation strategy for element-wise operations between operations. We conduct extensive experiments on Mamba model families with different sizes.MARCA achieves up to 463.22$\times$/11.66$\times$ speedup and up to 9761.42$\times$/242.52$\times$ energy efficiency compared to Intel Xeon 8358P CPU and NVIDIA Tesla A100 GPU implementations, respectively.
Enhancing Vectorized Map Perception with Historical Rasterized Maps
Sep 01, 2024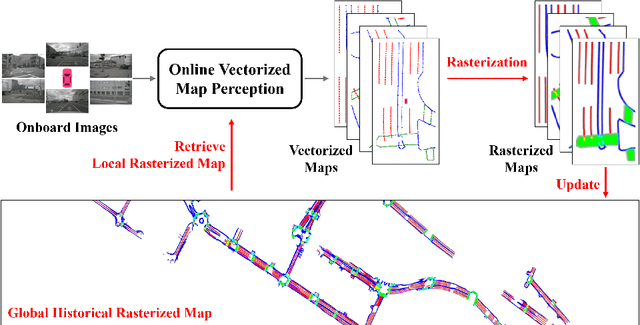
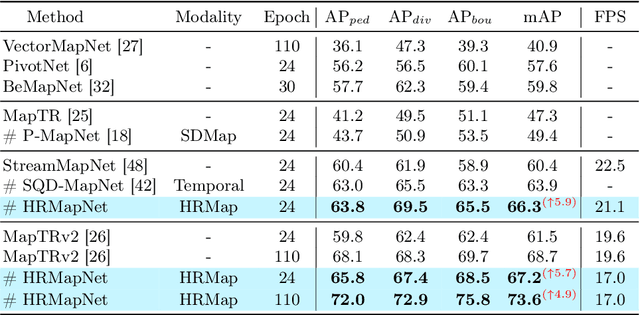
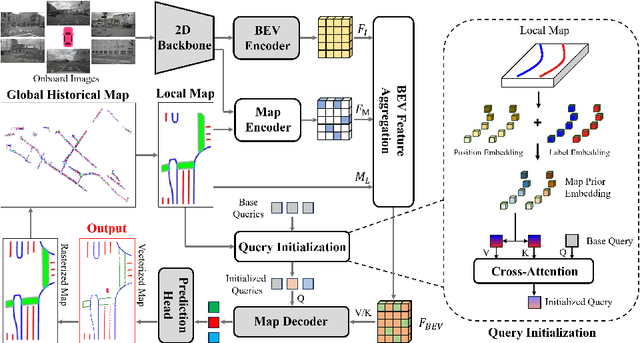
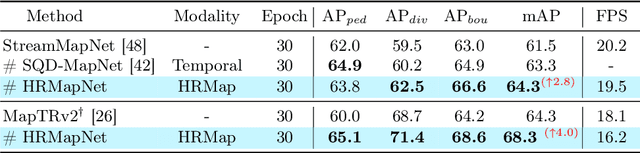
In autonomous driving, there is growing interest in end-to-end online vectorized map perception in bird's-eye-view (BEV) space, with an expectation that it could replace traditional high-cost offline high-definition (HD) maps. However, the accuracy and robustness of these methods can be easily compromised in challenging conditions, such as occlusion or adverse weather, when relying only on onboard sensors. In this paper, we propose HRMapNet, leveraging a low-cost Historical Rasterized Map to enhance online vectorized map perception. The historical rasterized map can be easily constructed from past predicted vectorized results and provides valuable complementary information. To fully exploit a historical map, we propose two novel modules to enhance BEV features and map element queries. For BEV features, we employ a feature aggregation module to encode features from both onboard images and the historical map. For map element queries, we design a query initialization module to endow queries with priors from the historical map. The two modules contribute to leveraging map information in online perception. Our HRMapNet can be integrated with most online vectorized map perception methods. We integrate it in two state-of-the-art methods, significantly improving their performance on both the nuScenes and Argoverse 2 datasets. The source code is released at https://github.com/HXMap/HRMapNet.