 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriveMA: Driving Vision-Language-Action Models with verifiable Meta-Actions
May 29, 2026Driving Vision-Language-Action Models (Driving VLAs) aim to use language to improve end-to-end planning, but the language-action gap limits this promise. We propose DriveMA, a Driving VLA framework built on verifiable meta-actions, which summarize future ego motion into compact language-domain intentions and can be constructed from expert trajectories with a trajectory-grounded annotation pipeline and can be verified against generated trajectories through rule-based projection. DriveMA exploits this verifiability with action-centric supervised training and a data-efficient turn-level credit assignment reinforcement learning framework, explicitly aligning high-level decisions with low-level trajectory planning through dense rewards and precise credit assignment. DriveMA sets a new state of the art on the Waymo Open Dataset Vision-based E2E Driving, achieving a Rater Feedback Score of 8.060 with a 2B model and further improving it to 8.079 with a 4B model; it also obtains competitive closed-loop planning performance on NAVSIM. These results show that even a simple meta-action interface can achieve state-of-the-art planning when made verifiable and optimized for language-action alignment. Code, data, and models will be released to facilitate future research.
DriveMA: Rethinking Language Interfaces in Driving VLAs with One-Step Meta-Actions
May 21, 2026Driving Vision-Language-Action Models (Driving VLAs) commonly introduce natural-language reasoning as an intermediate interface for end-to-end planning, but reasoning-centric interfaces face three practical bottlenecks: obtaining high-quality reasoning annotations is difficult, generating and understanding long reasoning chains is challenging for compact models, and inference latency is substantially increased. In this paper, we rethink the design of language interfaces in Driving VLAs and show that concise one-step meta-actions are a simple yet effective alternative to verbose reasoning. Meta-actions provide semantic decision grounding while remaining low-entropy, and being automatically derivable from expert trajectories, enabling scalable supervision and reliable trajectory conditioning. Building on this interface, we propose DriveMA, which combines action-centric supervised training with a turn-level credit-assignment reinforcement learning framework that jointly optimizes meta-action correctness, trajectory quality, and trajectory--meta-action consistency. Experiments show that DriveMA already achieves a new state of the art on the Waymo End-to-End Driving Challenge with a 2B model, reaching a Rater Feedback Score (RFS) of 8.060, while its 4B version further improves the state of the art to 8.079; DriveMA also obtains competitive performance on NAVSIM. Ablations demonstrate that one-step meta-actions offer a better practical trade-off between expressiveness, predictability, and inference efficiency than natural-language reasoning or finer-grained action sequences. Code, data, and models will be released to facilitate future research.
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
Mar 13, 2025


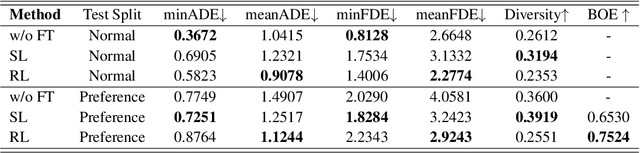
Generating human-like and adaptive trajectories is essential for autonomous driving in dynamic environments. While generative models have shown promise in synthesizing feasible trajectories, they often fail to capture the nuanced variability of human driving styles due to dataset biases and distributional shifts. To address this, we introduce TrajHF, a human feedback-driven finetuning framework for generative trajectory models, designed to align motion planning with diverse driving preferences. TrajHF incorporates multi-conditional denoiser and reinforcement learning with human feedback to refine multi-modal trajectory generation beyond conventional imitation learning. This enables better alignment with human driving preferences while maintaining safety and feasibility constraints. TrajHF achieves PDMS of 93.95 on NavSim benchmark, significantly exceeding other methods. TrajHF sets a new paradigm for personalized and adaptable trajectory generation in autonomous driving.
VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion
Feb 03, 2025


Recent success in legged robot locomotion is attributed to the integration of reinforcement learning and physical simulators. However, these policies often encounter challenges when deployed in real-world environments due to sim-to-real gaps, as simulators typically fail to replicate visual realism and complex real-world geometry. Moreover, the lack of realistic visual rendering limits the ability of these policies to support high-level tasks requiring RGB-based perception like ego-centric navigation. This paper presents a Real-to-Sim-to-Real framework that generates photorealistic and physically interactive "digital twin" simulation environments for visual navigation and locomotion learning. Our approach leverages 3D Gaussian Splatting (3DGS) based scene reconstruction from multi-view images and integrates these environments into simulations that support ego-centric visual perception and mesh-based physical interactions. To demonstrate its effectiveness, we train a reinforcement learning policy within the simulator to perform a visual goal-tracking task. Extensive experiments show that our framework achieves RGB-only sim-to-real policy transfer. Additionally, our framework facilitates the rapid adaptation of robot policies with effective exploration capability in complex new environments, highlighting its potential for applications in households and factories.
Cross Anything: General Quadruped Robot Navigation through Complex Terrains
Jul 23, 2024The application of vision-language models (VLMs) has achieved impressive success in various robotics tasks, but there are few explorations for foundation models used in quadruped robot navigation. We introduce Cross Anything System (CAS), an innovative system composed of a high-level reasoning module and a low-level control policy, enabling the robot to navigate across complex 3D terrains and reach the goal position. For high-level reasoning and motion planning, we propose a novel algorithmic system taking advantage of a VLM, with a design of task decomposition and a closed-loop sub-task execution mechanism. For low-level locomotion control, we utilize the Probability Annealing Selection (PAS) method to train a control policy by reinforcement learning. Numerous experiments show that our whole system can accurately and robustly navigate across complex 3D terrains, and its strong generalization ability ensures the applications in diverse indoor and outdoor scenarios and terrains. Project page: https://cross-anything.github.io/
AI-based Automatic Segmentation of Prostate on Multi-modality Images: A Review
Jul 09, 2024



Prostate cancer represents a major threat to health. Early detection is vital in reducing the mortality rate among prostate cancer patients. One approach involves using multi-modality (CT, MRI, US, etc.) computer-aided diagnosis (CAD) systems for the prostate region. However, prostate segmentation is challenging due to imperfections in the images and the prostate's complex tissue structure. The advent of precision medicine and a significant increase in clinical capacity have spurred the need for various data-driven tasks in the field of medical imaging. Recently, numerous machine learning and data mining tools have been integrated into various medical areas, including image segmentation. This article proposes a new classification method that differentiates supervision types, either in number or kind, during the training phase. Subsequently, we conducted a survey on artificial intelligence (AI)-based automatic prostate segmentation methods, examining the advantages and limitations of each. Additionally, we introduce variants of evaluation metrics for the verification and performance assessment of the segmentation method and summarize the current challenges. Finally, future research directions and development trends are discussed, reflecting the outcomes of our literature survey, suggesting high-precision detection and treatment of prostate cancer as a promising avenue.
Large Trajectory Models are Scalable Motion Predictors and Planners
Oct 30, 2023



Motion prediction and planning are vital tasks in autonomous driving, and recent efforts have shifted to machine learning-based approaches. The challenges include understanding diverse road topologies, reasoning traffic dynamics over a long time horizon, interpreting heterogeneous behaviors, and generating policies in a large continuous state space. Inspired by the success of large language models in addressing similar complexities through model scaling, we introduce a scalable trajectory model called State Transformer (STR). STR reformulates the motion prediction and motion planning problems by arranging observations, states, and actions into one unified sequence modeling task. With a simple model design, STR consistently outperforms baseline approaches in both problems. Remarkably, experimental results reveal that large trajectory models (LTMs), such as STR, adhere to the scaling laws by presenting outstanding adaptability and learning efficiency. Qualitative results further demonstrate that LTMs are capable of making plausible predictions in scenarios that diverge significantly from the training data distribution. LTMs also learn to make complex reasonings for long-term planning, without explicit loss designs or costly high-level annotations.