 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMG: Omni-Modal Motion Generation for Generalist Humanoid Control
Jun 09, 2026Humanoid whole-body control has made significant progress in recent years, yet existing approaches remain limited to few-skill policies with heavy reward engineering, or motion trackers that are difficult to extend to new input modalities. We argue that the key to general-purpose humanoid control is to build a scalable brain, a module capable of reasoning with diverse conditioning modalities, atop a reactive motion tracking cerebellum, mirroring the hierarchical structure of biological motor systems. Two challenges arise in realizing this vision: acquiring a vast amount of high-quality data to achieve general purpose control, and equipping the generator with the capability to condition on compositional, extensible multi-modal inputs. We present OMG, which addresses these challenges with a meticulous data curation, filtering and labeling pipeline, as well as a diffusion-based motion generation backbone that conditions on language, audio, and human reference motions. Extensive experiments validate OMG as an omni-modal whole-body controller exhibiting state-of-the-art performance, model scaling behavior and efficient adaptation to new distributions and modalities, marking a concrete step toward foundation models for humanoid robots.
Generative Control as Optimization: Time Unconditional Flow Matching for Adaptive and Robust Robotic Control
Mar 18, 2026Diffusion models and flow matching have become a cornerstone of robotic imitation learning, yet they suffer from a structural inefficiency where inference is often bound to a fixed integration schedule that is agnostic to state complexity. This paradigm forces the policy to expend the same computational budget on trivial motions as it does on complex tasks. We introduce Generative Control as Optimization (GeCO), a time-unconditional framework that transforms action synthesis from trajectory integration into iterative optimization. GeCO learns a stationary velocity field in the action-sequence space where expert behaviors form stable attractors. Consequently, test-time inference becomes an adaptive process that allocates computation based on convergence--exiting early for simple states while refining longer for difficult ones. Furthermore, this stationary geometry yields an intrinsic, training-free safety signal, as the field norm at the optimized action serves as a robust out-of-distribution (OOD) detector, remaining low for in-distribution states while significantly increasing for anomalies. We validate GeCO on standard simulation benchmarks and demonstrate seamless scaling to pi0-series Vision-Language-Action (VLA) models. As a plug-and-play replacement for standard flow-matching heads, GeCO improves success rates and efficiency with an optimization-native mechanism for safe deployment. Video and code can be found at https://hrh6666.github.io/GeCO/
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
Feb 02, 2026Achieving highly dynamic humanoid parkour on unseen, complex terrains remains a challenge in robotics. Although general locomotion policies demonstrate capabilities across broad terrain distributions, they often struggle with arbitrary and highly challenging environments. To overcome this limitation, we propose a real-to-sim-to-real framework that leverages rapid test-time training (TTT) on novel terrains, significantly enhancing the robot's capability to traverse extremely difficult geometries. We adopt a two-stage end-to-end learning paradigm: a policy is first pre-trained on diverse procedurally generated terrains, followed by rapid fine-tuning on high-fidelity meshes reconstructed from real-world captures. Specifically, we develop a feed-forward, efficient, and high-fidelity geometry reconstruction pipeline using RGB-D inputs, ensuring both speed and quality during test-time training. We demonstrate that TTT-Parkour empowers humanoid robots to master complex obstacles, including wedges, stakes, boxes, trapezoids, and narrow beams. The whole pipeline of capturing, reconstructing, and test-time training requires less than 10 minutes on most tested terrains. Extensive experiments show that the policy after test-time training exhibits robust zero-shot sim-to-real transfer capability.
Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids
Jan 12, 2026Achieving robust humanoid hiking in complex, unstructured environments requires transitioning from reactive proprioception to proactive perception. However, integrating exteroception remains a significant challenge: mapping-based methods suffer from state estimation drift; for instance, LiDAR-based methods do not handle torso jitter well. Existing end-to-end approaches often struggle with scalability and training complexity; specifically, some previous works using virtual obstacles are implemented case-by-case. In this work, we present \textit{Hiking in the Wild}, a scalable, end-to-end parkour perceptive framework designed for robust humanoid hiking. To ensure safety and training stability, we introduce two key mechanisms: a foothold safety mechanism combining scalable \textit{Terrain Edge Detection} with \textit{Foot Volume Points} to prevent catastrophic slippage on edges, and a \textit{Flat Patch Sampling} strategy that mitigates reward hacking by generating feasible navigation targets. Our approach utilizes a single-stage reinforcement learning scheme, mapping raw depth inputs and proprioception directly to joint actions, without relying on external state estimation. Extensive field experiments on a full-size humanoid demonstrate that our policy enables robust traversal of complex terrains at speeds up to 2.5 m/s. The training and deployment code is open-sourced to facilitate reproducible research and deployment on real robots with minimal hardware modifications.
Deep Whole-body Parkour
Jan 12, 2026Current approaches to humanoid control generally fall into two paradigms: perceptive locomotion, which handles terrain well but is limited to pedal gaits, and general motion tracking, which reproduces complex skills but ignores environmental capabilities. This work unites these paradigms to achieve perceptive general motion control. We present a framework where exteroceptive sensing is integrated into whole-body motion tracking, permitting a humanoid to perform highly dynamic, non-locomotion tasks on uneven terrain. By training a single policy to perform multiple distinct motions across varied terrestrial features, we demonstrate the non-trivial benefit of integrating perception into the control loop. Our results show that this framework enables robust, highly dynamic multi-contact motions, such as vaulting and dive-rolling, on unstructured terrain, significantly expanding the robot's traversability beyond simple walking or running. https://project-instinct.github.io/deep-whole-body-parkour
RoboEngine: Plug-and-Play Robot Data Augmentation with Semantic Robot Segmentation and Background Generation
Mar 24, 2025



Visual augmentation has become a crucial technique for enhancing the visual robustness of imitation learning. However, existing methods are often limited by prerequisites such as camera calibration or the need for controlled environments (e.g., green screen setups). In this work, we introduce RoboEngine, the first plug-and-play visual robot data augmentation toolkit. For the first time, users can effortlessly generate physics- and task-aware robot scenes with just a few lines of code. To achieve this, we present a novel robot scene segmentation dataset, a generalizable high-quality robot segmentation model, and a fine-tuned background generation model, which together form the core components of the out-of-the-box toolkit. Using RoboEngine, we demonstrate the ability to generalize robot manipulation tasks across six entirely new scenes, based solely on demonstrations collected from a single scene, achieving a more than 200% performance improvement compared to the no-augmentation baseline. All datasets, model weights, and the toolkit will be publicly released.
MoE-Loco: Mixture of Experts for Multitask Locomotion
Mar 11, 2025

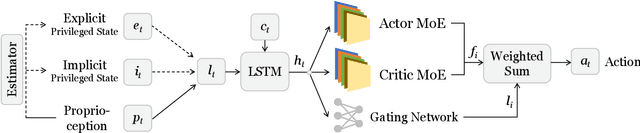
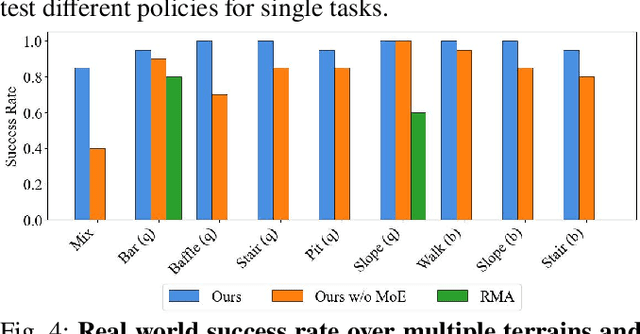
We present MoE-Loco, a Mixture of Experts (MoE) framework for multitask locomotion for legged robots. Our method enables a single policy to handle diverse terrains, including bars, pits, stairs, slopes, and baffles, while supporting quadrupedal and bipedal gaits. Using MoE, we mitigate the gradient conflicts that typically arise in multitask reinforcement learning, improving both training efficiency and performance. Our experiments demonstrate that different experts naturally specialize in distinct locomotion behaviors, which can be leveraged for task migration and skill composition. We further validate our approach in both simulation and real-world deployment, showcasing its robustness and adaptability.
VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion
Feb 03, 2025


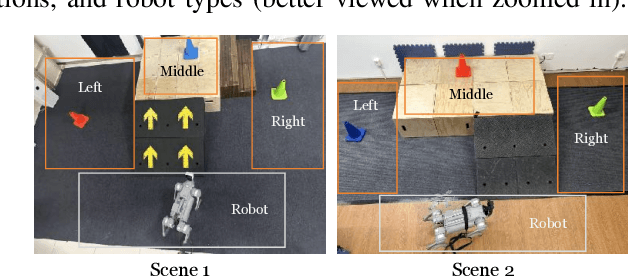
Recent success in legged robot locomotion is attributed to the integration of reinforcement learning and physical simulators. However, these policies often encounter challenges when deployed in real-world environments due to sim-to-real gaps, as simulators typically fail to replicate visual realism and complex real-world geometry. Moreover, the lack of realistic visual rendering limits the ability of these policies to support high-level tasks requiring RGB-based perception like ego-centric navigation. This paper presents a Real-to-Sim-to-Real framework that generates photorealistic and physically interactive "digital twin" simulation environments for visual navigation and locomotion learning. Our approach leverages 3D Gaussian Splatting (3DGS) based scene reconstruction from multi-view images and integrates these environments into simulations that support ego-centric visual perception and mesh-based physical interactions. To demonstrate its effectiveness, we train a reinforcement learning policy within the simulator to perform a visual goal-tracking task. Extensive experiments show that our framework achieves RGB-only sim-to-real policy transfer. Additionally, our framework facilitates the rapid adaptation of robot policies with effective exploration capability in complex new environments, highlighting its potential for applications in households and factories.
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps
Sep 12, 2024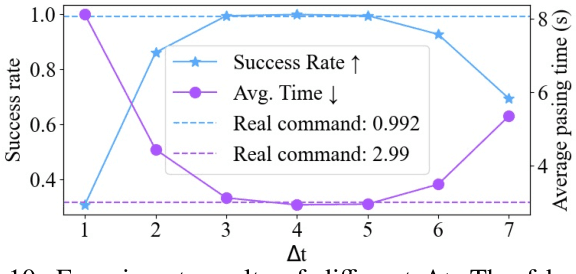
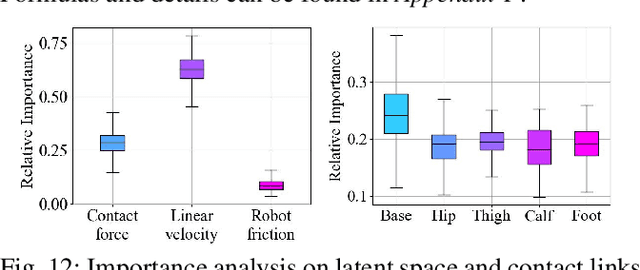


Quadruped robots must exhibit robust walking capabilities in practical applications. In this work, we propose a novel approach that enables quadruped robots to pass various small obstacles, or "tiny traps". Existing methods often rely on exteroceptive sensors, which can be unreliable for detecting such tiny traps. To overcome this limitation, our approach focuses solely on proprioceptive inputs. We introduce a two-stage training framework incorporating a contact encoder and a classification head to learn implicit representations of different traps. Additionally, we design a set of tailored reward functions to improve both the stability of training and the ease of deployment for goal-tracking tasks. To benefit further research, we design a new benchmark for tiny trap task. Extensive experiments in both simulation and real-world settings demonstrate the effectiveness and robustness of our method. Project Page: https://robust-robot-walker.github.io/
Cross Anything: General Quadruped Robot Navigation through Complex Terrains
Jul 23, 2024The application of vision-language models (VLMs) has achieved impressive success in various robotics tasks, but there are few explorations for foundation models used in quadruped robot navigation. We introduce Cross Anything System (CAS), an innovative system composed of a high-level reasoning module and a low-level control policy, enabling the robot to navigate across complex 3D terrains and reach the goal position. For high-level reasoning and motion planning, we propose a novel algorithmic system taking advantage of a VLM, with a design of task decomposition and a closed-loop sub-task execution mechanism. For low-level locomotion control, we utilize the Probability Annealing Selection (PAS) method to train a control policy by reinforcement learning. Numerous experiments show that our whole system can accurately and robustly navigate across complex 3D terrains, and its strong generalization ability ensures the applications in diverse indoor and outdoor scenarios and terrains. Project page: https://cross-anything.github.io/