 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEE4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
Oct 30, 2025Immersive applications call for synthesizing spatiotemporal 4D content from casual videos without costly 3D supervision. Existing video-to-4D methods typically rely on manually annotated camera poses, which are labor-intensive and brittle for in-the-wild footage. Recent warp-then-inpaint approaches mitigate the need for pose labels by warping input frames along a novel camera trajectory and using an inpainting model to fill missing regions, thereby depicting the 4D scene from diverse viewpoints. However, this trajectory-to-trajectory formulation often entangles camera motion with scene dynamics and complicates both modeling and inference. We introduce SEE4D, a pose-free, trajectory-to-camera framework that replaces explicit trajectory prediction with rendering to a bank of fixed virtual cameras, thereby separating camera control from scene modeling. A view-conditional video inpainting model is trained to learn a robust geometry prior by denoising realistically synthesized warped images and to inpaint occluded or missing regions across virtual viewpoints, eliminating the need for explicit 3D annotations. Building on this inpainting core, we design a spatiotemporal autoregressive inference pipeline that traverses virtual-camera splines and extends videos with overlapping windows, enabling coherent generation at bounded per-step complexity. We validate See4D on cross-view video generation and sparse reconstruction benchmarks. Across quantitative metrics and qualitative assessments, our method achieves superior generalization and improved performance relative to pose- or trajectory-conditioned baselines, advancing practical 4D world modeling from casual videos.
Hyperbolic Binary Neural Network
Jan 07, 2025



Binary Neural Network (BNN) converts full-precision weights and activations into their extreme 1-bit counterparts, making it particularly suitable for deployment on lightweight mobile devices. While binary neural networks are typically formulated as a constrained optimization problem and optimized in the binarized space, general neural networks are formulated as an unconstrained optimization problem and optimized in the continuous space. This paper introduces the Hyperbolic Binary Neural Network (HBNN) by leveraging the framework of hyperbolic geometry to optimize the constrained problem. Specifically, we transform the constrained problem in hyperbolic space into an unconstrained one in Euclidean space using the Riemannian exponential map. On the other hand, we also propose the Exponential Parametrization Cluster (EPC) method, which, compared to the Riemannian exponential map, shrinks the segment domain based on a diffeomorphism. This approach increases the probability of weight flips, thereby maximizing the information gain in BNNs. Experimental results on CIFAR10, CIFAR100, and ImageNet classification datasets with VGGsmall, ResNet18, and ResNet34 models illustrate the superior performance of our HBNN over state-of-the-art methods.
GEAL: Generalizable 3D Affordance Learning with Cross-Modal Consistency
Dec 12, 2024



Identifying affordance regions on 3D objects from semantic cues is essential for robotics and human-machine interaction. However, existing 3D affordance learning methods struggle with generalization and robustness due to limited annotated data and a reliance on 3D backbones focused on geometric encoding, which often lack resilience to real-world noise and data corruption. We propose GEAL, a novel framework designed to enhance the generalization and robustness of 3D affordance learning by leveraging large-scale pre-trained 2D models. We employ a dual-branch architecture with Gaussian splatting to establish consistent mappings between 3D point clouds and 2D representations, enabling realistic 2D renderings from sparse point clouds. A granularity-adaptive fusion module and a 2D-3D consistency alignment module further strengthen cross-modal alignment and knowledge transfer, allowing the 3D branch to benefit from the rich semantics and generalization capacity of 2D models. To holistically assess the robustness, we introduce two new corruption-based benchmarks: PIAD-C and LASO-C. Extensive experiments on public datasets and our benchmarks show that GEAL consistently outperforms existing methods across seen and novel object categories, as well as corrupted data, demonstrating robust and adaptable affordance prediction under diverse conditions. Code and corruption datasets have been made publicly available.
Learning to Decouple the Lights for 3D Face Texture Modeling
Dec 11, 2024



Existing research has made impressive strides in reconstructing human facial shapes and textures from images with well-illuminated faces and minimal external occlusions. Nevertheless, it remains challenging to recover accurate facial textures from scenarios with complicated illumination affected by external occlusions, e.g. a face that is partially obscured by items such as a hat. Existing works based on the assumption of single and uniform illumination cannot correctly process these data. In this work, we introduce a novel approach to model 3D facial textures under such unnatural illumination. Instead of assuming single illumination, our framework learns to imitate the unnatural illumination as a composition of multiple separate light conditions combined with learned neural representations, named Light Decoupling. According to experiments on both single images and video sequences, we demonstrate the effectiveness of our approach in modeling facial textures under challenging illumination affected by occlusions. Please check https://tianxinhuang.github.io/projects/Deface for our videos and codes.
VCR-GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction
Jun 09, 2024
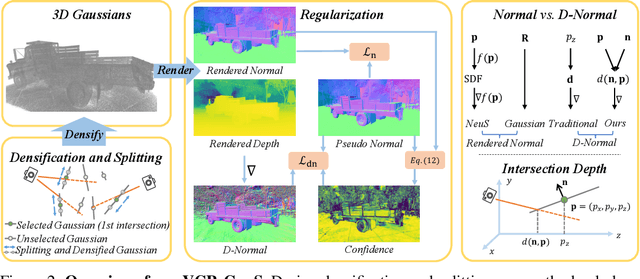


Although 3D Gaussian Splatting has been widely studied because of its realistic and efficient novel-view synthesis, it is still challenging to extract a high-quality surface from the point-based representation. Previous works improve the surface by incorporating geometric priors from the off-the-shelf normal estimator. However, there are two main limitations: 1) Supervising normal rendered from 3D Gaussians updates only the rotation parameter while neglecting other geometric parameters; 2) The inconsistency of predicted normal maps across multiple views may lead to severe reconstruction artifacts. In this paper, we propose a Depth-Normal regularizer that directly couples normal with other geometric parameters, leading to full updates of the geometric parameters from normal regularization. We further propose a confidence term to mitigate inconsistencies of normal predictions across multiple views. Moreover, we also introduce a densification and splitting strategy to regularize the size and distribution of 3D Gaussians for more accurate surface modeling. Compared with Gaussian-based baselines, experiments show that our approach obtains better reconstruction quality and maintains competitive appearance quality at faster training speed and 100+ FPS rendering. Our code will be made open-source upon paper acceptance.
FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes
May 28, 2024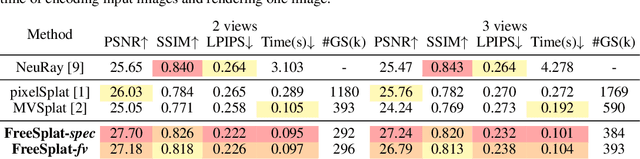
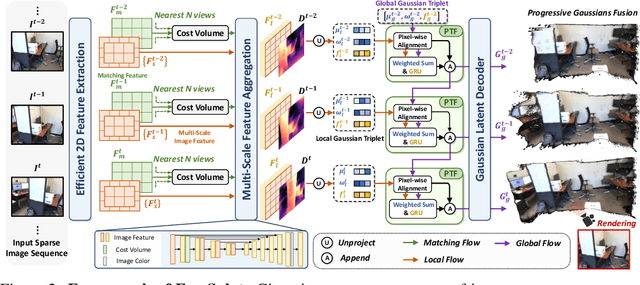

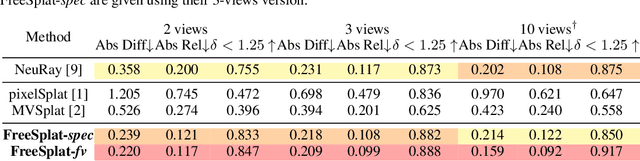
Empowering 3D Gaussian Splatting with generalization ability is appealing. However, existing generalizable 3D Gaussian Splatting methods are largely confined to narrow-range interpolation between stereo images due to their heavy backbones, thus lacking the ability to accurately localize 3D Gaussian and support free-view synthesis across wide view range. In this paper, we present a novel framework FreeSplat that is capable of reconstructing geometrically consistent 3D scenes from long sequence input towards free-view synthesis.Specifically, we firstly introduce Low-cost Cross-View Aggregation achieved by constructing adaptive cost volumes among nearby views and aggregating features using a multi-scale structure. Subsequently, we present the Pixel-wise Triplet Fusion to eliminate redundancy of 3D Gaussians in overlapping view regions and to aggregate features observed across multiple views. Additionally, we propose a simple but effective free-view training strategy that ensures robust view synthesis across broader view range regardless of the number of views. Our empirical results demonstrate state-of-the-art novel view synthesis peformances in both novel view rendered color maps quality and depth maps accuracy across different numbers of input views. We also show that FreeSplat performs inference more efficiently and can effectively reduce redundant Gaussians, offering the possibility of feed-forward large scene reconstruction without depth priors.
Zero-shot Point Cloud Completion Via 2D Priors
Apr 10, 20243D point cloud completion is designed to recover complete shapes from partially observed point clouds. Conventional completion methods typically depend on extensive point cloud data for training %, with their effectiveness often constrained to object categories similar to those seen during training. In contrast, we propose a zero-shot framework aimed at completing partially observed point clouds across any unseen categories. Leveraging point rendering via Gaussian Splatting, we develop techniques of Point Cloud Colorization and Zero-shot Fractal Completion that utilize 2D priors from pre-trained diffusion models to infer missing regions. Experimental results on both synthetic and real-world scanned point clouds demonstrate that our approach outperforms existing methods in completing a variety of objects without any requirement for specific training data.
FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Mar 04, 2024



In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
Learnable Chamfer Distance for Point Cloud Reconstruction
Dec 27, 2023



As point clouds are 3D signals with permutation invariance, most existing works train their reconstruction networks by measuring shape differences with the average point-to-point distance between point clouds matched with predefined rules. However, the static matching rules may deviate from actual shape differences. Although some works propose dynamically-updated learnable structures to replace matching rules, they need more iterations to converge well. In this work, we propose a simple but effective reconstruction loss, named Learnable Chamfer Distance (LCD) by dynamically paying attention to matching distances with different weight distributions controlled with a group of learnable networks. By training with adversarial strategy, LCD learns to search defects in reconstructed results and overcomes the weaknesses of static matching rules, while the performances at low iterations can also be guaranteed by the basic matching algorithm. Experiments on multiple reconstruction networks confirm that LCD can help achieve better reconstruction performances and extract more representative representations with faster convergence and comparable training efficiency. The source codes are provided in https://github.com/Tianxinhuang/LCDNet.git.
MaxQ: Multi-Axis Query for N:M Sparsity Network
Dec 12, 2023N:M sparsity has received increasing attention due to its remarkable performance and latency trade-off compared with structured and unstructured sparsity. However, existing N:M sparsity methods do not differentiate the relative importance of weights among blocks and leave important weights underappreciated. Besides, they directly apply N:M sparsity to the whole network, which will cause severe information loss. Thus, they are still sub-optimal. In this paper, we propose an efficient and effective Multi-Axis Query methodology, dubbed as MaxQ, to rectify these problems. During the training, MaxQ employs a dynamic approach to generate soft N:M masks, considering the weight importance across multiple axes. This method enhances the weights with more importance and ensures more effective updates. Meanwhile, a sparsity strategy that gradually increases the percentage of N:M weight blocks is applied, which allows the network to heal from the pruning-induced damage progressively. During the runtime, the N:M soft masks can be precomputed as constants and folded into weights without causing any distortion to the sparse pattern and incurring additional computational overhead. Comprehensive experiments demonstrate that MaxQ achieves consistent improvements across diverse CNN architectures in various computer vision tasks, including image classification, object detection and instance segmentation. For ResNet50 with 1:16 sparse pattern, MaxQ can achieve 74.6\% top-1 accuracy on ImageNet and improve by over 2.8\% over the state-of-the-art.