 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyn-to-Real Unsupervised Domain Adaptation for Indoor 3D Object Detection
Jun 17, 2024



The use of synthetic data in indoor 3D object detection offers the potential of greatly reducing the manual labor involved in 3D annotations and training effective zero-shot detectors. However, the complicated domain shifts across syn-to-real indoor datasets remains underexplored. In this paper, we propose a novel Object-wise Hierarchical Domain Alignment (OHDA) framework for syn-to-real unsupervised domain adaptation in indoor 3D object detection. Our approach includes an object-aware augmentation strategy to effectively diversify the source domain data, and we introduce a two-branch adaptation framework consisting of an adversarial training branch and a pseudo labeling branch, in order to simultaneously reach holistic-level and class-level domain alignment. The pseudo labeling is further refined through two proposed schemes specifically designed for indoor UDA. Our adaptation results from synthetic dataset 3D-FRONT to real-world datasets ScanNetV2 and SUN RGB-D demonstrate remarkable mAP25 improvements of 9.7% and 9.1% over Source-Only baselines, respectively, and consistently outperform the methods adapted from 2D and 3D outdoor scenarios. The code will be publicly available upon paper acceptance.
Enhancing Generalizability of Representation Learning for Data-Efficient 3D Scene Understanding
Jun 17, 2024



The field of self-supervised 3D representation learning has emerged as a promising solution to alleviate the challenge presented by the scarcity of extensive, well-annotated datasets. However, it continues to be hindered by the lack of diverse, large-scale, real-world 3D scene datasets for source data. To address this shortfall, we propose Generalizable Representation Learning (GRL), where we devise a generative Bayesian network to produce diverse synthetic scenes with real-world patterns, and conduct pre-training with a joint objective. By jointly learning a coarse-to-fine contrastive learning task and an occlusion-aware reconstruction task, the model is primed with transferable, geometry-informed representations. Post pre-training on synthetic data, the acquired knowledge of the model can be seamlessly transferred to two principal downstream tasks associated with 3D scene understanding, namely 3D object detection and 3D semantic segmentation, using real-world benchmark datasets. A thorough series of experiments robustly display our method's consistent superiority over existing state-of-the-art pre-training approaches.
VCR-GauS: View Consistent Depth-Normal Regularizer for Gaussian Surface Reconstruction
Jun 09, 2024Although 3D Gaussian Splatting has been widely studied because of its realistic and efficient novel-view synthesis, it is still challenging to extract a high-quality surface from the point-based representation. Previous works improve the surface by incorporating geometric priors from the off-the-shelf normal estimator. However, there are two main limitations: 1) Supervising normal rendered from 3D Gaussians updates only the rotation parameter while neglecting other geometric parameters; 2) The inconsistency of predicted normal maps across multiple views may lead to severe reconstruction artifacts. In this paper, we propose a Depth-Normal regularizer that directly couples normal with other geometric parameters, leading to full updates of the geometric parameters from normal regularization. We further propose a confidence term to mitigate inconsistencies of normal predictions across multiple views. Moreover, we also introduce a densification and splitting strategy to regularize the size and distribution of 3D Gaussians for more accurate surface modeling. Compared with Gaussian-based baselines, experiments show that our approach obtains better reconstruction quality and maintains competitive appearance quality at faster training speed and 100+ FPS rendering. Our code will be made open-source upon paper acceptance.
FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes
May 28, 2024Empowering 3D Gaussian Splatting with generalization ability is appealing. However, existing generalizable 3D Gaussian Splatting methods are largely confined to narrow-range interpolation between stereo images due to their heavy backbones, thus lacking the ability to accurately localize 3D Gaussian and support free-view synthesis across wide view range. In this paper, we present a novel framework FreeSplat that is capable of reconstructing geometrically consistent 3D scenes from long sequence input towards free-view synthesis.Specifically, we firstly introduce Low-cost Cross-View Aggregation achieved by constructing adaptive cost volumes among nearby views and aggregating features using a multi-scale structure. Subsequently, we present the Pixel-wise Triplet Fusion to eliminate redundancy of 3D Gaussians in overlapping view regions and to aggregate features observed across multiple views. Additionally, we propose a simple but effective free-view training strategy that ensures robust view synthesis across broader view range regardless of the number of views. Our empirical results demonstrate state-of-the-art novel view synthesis peformances in both novel view rendered color maps quality and depth maps accuracy across different numbers of input views. We also show that FreeSplat performs inference more efficiently and can effectively reduce redundant Gaussians, offering the possibility of feed-forward large scene reconstruction without depth priors.
GOV-NeSF: Generalizable Open-Vocabulary Neural Semantic Fields
Apr 01, 2024



Recent advancements in vision-language foundation models have significantly enhanced open-vocabulary 3D scene understanding. However, the generalizability of existing methods is constrained due to their framework designs and their reliance on 3D data. We address this limitation by introducing Generalizable Open-Vocabulary Neural Semantic Fields (GOV-NeSF), a novel approach offering a generalizable implicit representation of 3D scenes with open-vocabulary semantics. We aggregate the geometry-aware features using a cost volume, and propose a Multi-view Joint Fusion module to aggregate multi-view features through a cross-view attention mechanism, which effectively predicts view-specific blending weights for both colors and open-vocabulary features. Remarkably, our GOV-NeSF exhibits state-of-the-art performance in both 2D and 3D open-vocabulary semantic segmentation, eliminating the need for ground truth semantic labels or depth priors, and effectively generalize across scenes and datasets without fine-tuning.
Instance Similarity Learning for Unsupervised Feature Representation
Aug 05, 2021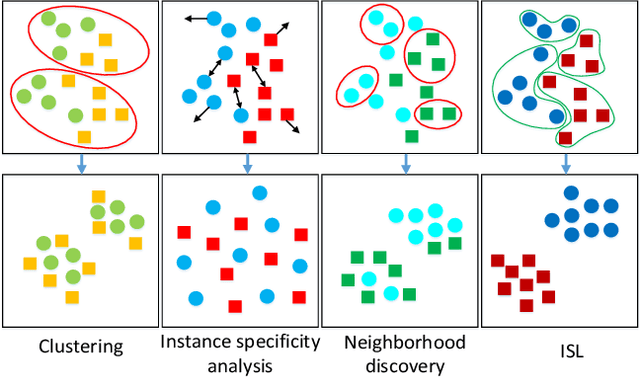

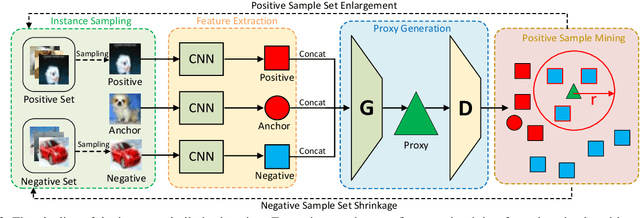
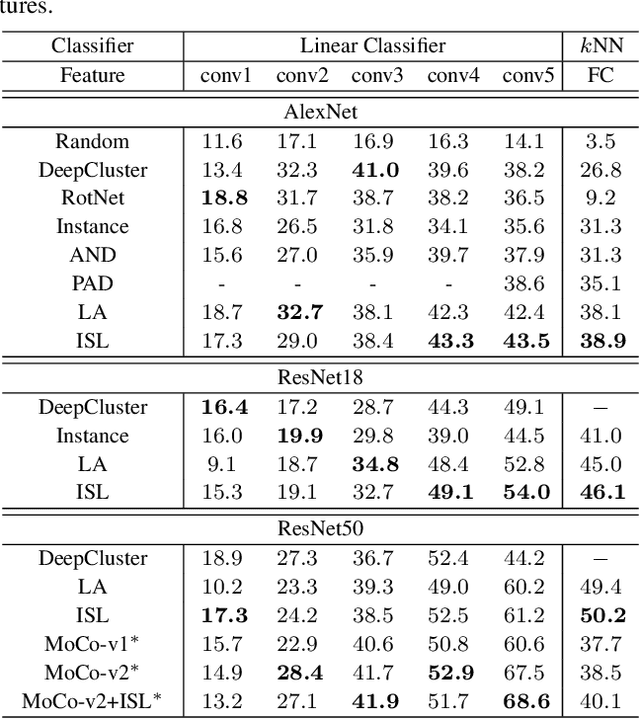
In this paper, we propose an instance similarity learning (ISL) method for unsupervised feature representation. Conventional methods assign close instance pairs in the feature space with high similarity, which usually leads to wrong pairwise relationship for large neighborhoods because the Euclidean distance fails to depict the true semantic similarity on the feature manifold. On the contrary, our method mines the feature manifold in an unsupervised manner, through which the semantic similarity among instances is learned in order to obtain discriminative representations. Specifically, we employ the Generative Adversarial Networks (GAN) to mine the underlying feature manifold, where the generated features are applied as the proxies to progressively explore the feature manifold so that the semantic similarity among instances is acquired as reliable pseudo supervision. Extensive experiments on image classification demonstrate the superiority of our method compared with the state-of-the-art methods. The code is available at https://github.com/ZiweiWangTHU/ISL.git.
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020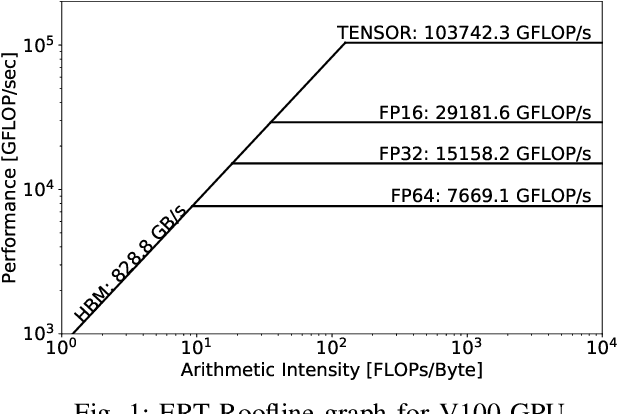
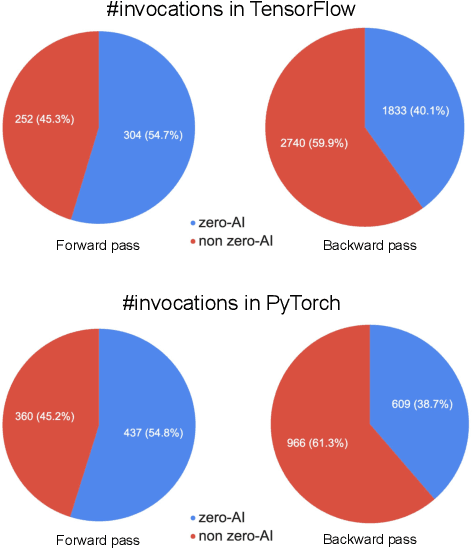
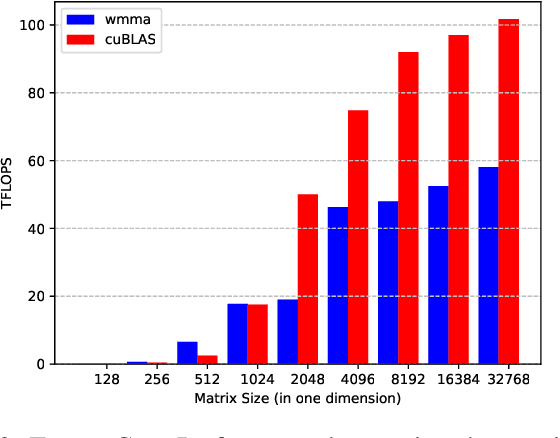
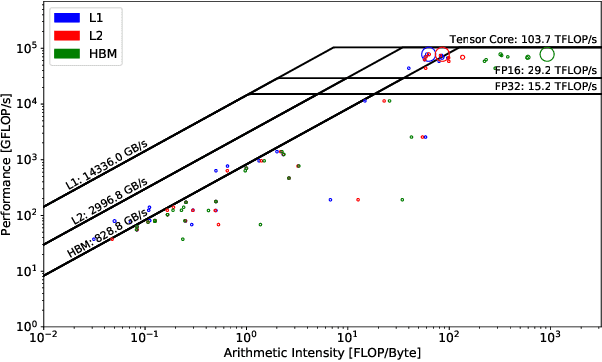
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
Time-Based Roofline for Deep Learning Performance Analysis
Sep 22, 2020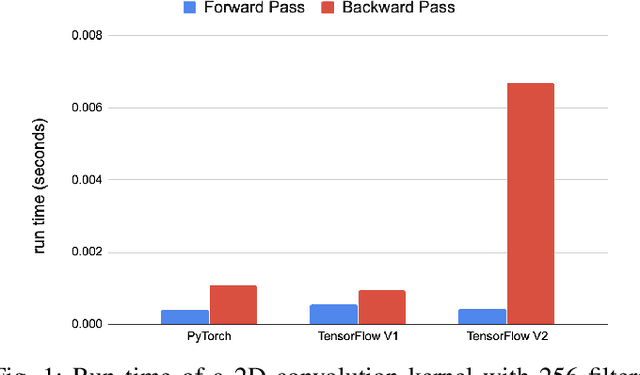
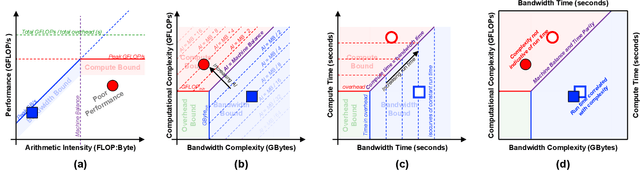
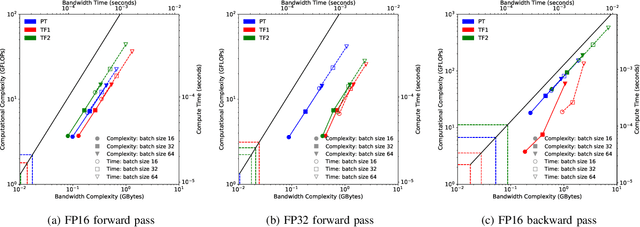
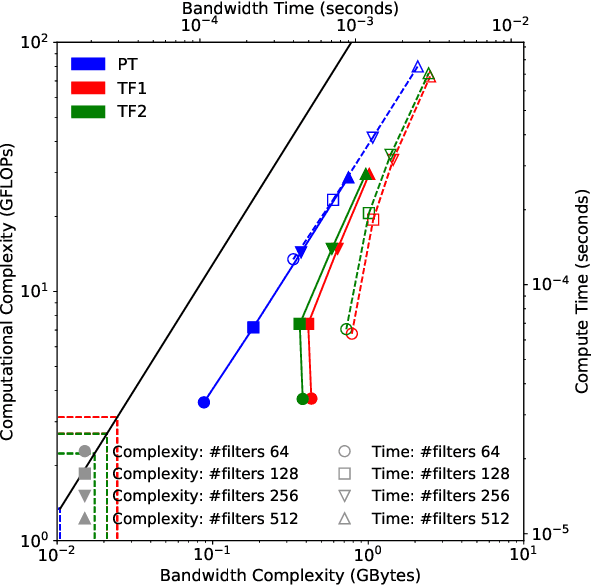
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.