 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Based Roofline for Deep Learning Performance Analysis
Paper and Code
Sep 22, 2020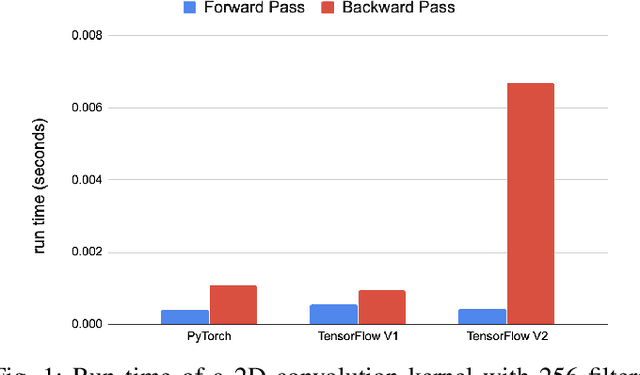
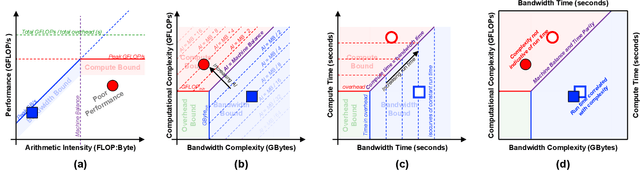
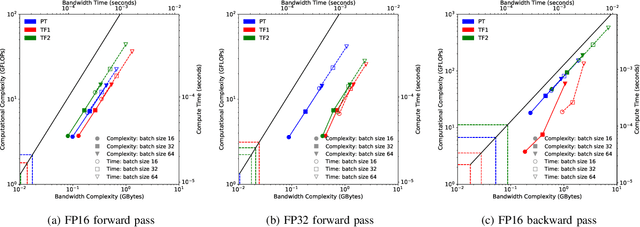
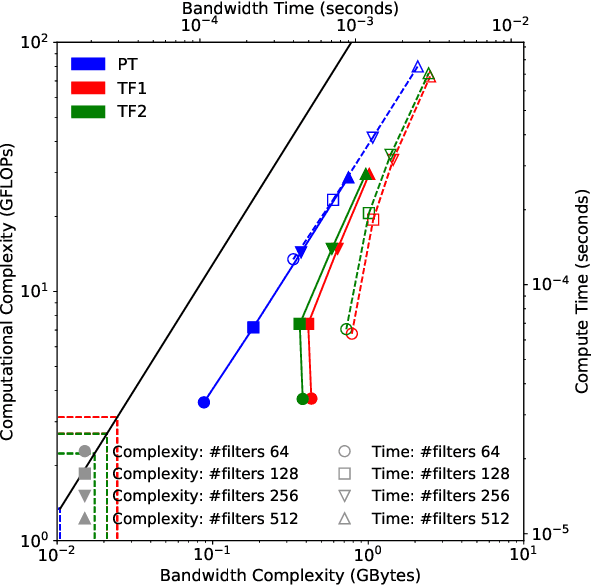
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.