 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Spatio-temporal Fourier Transformer (StFT) for Long-term Dynamics Prediction
Mar 14, 2025Simulating the long-term dynamics of multi-scale and multi-physics systems poses a significant challenge in understanding complex phenomena across science and engineering. The complexity arises from the intricate interactions between scales and the interplay of diverse physical processes. Neural operators have emerged as promising models for predicting such dynamics due to their flexibility and computational efficiency. However, they often fail to effectively capture multi-scale interactions or quantify the uncertainties inherent in the predictions. These limitations lead to rapid error accumulation, particularly in long-term forecasting of systems characterized by complex and coupled dynamics. To address these challenges, we propose a spatio-temporal Fourier transformer (StFT), in which each transformer block is designed to learn dynamics at a specific scale. By leveraging a structured hierarchy of StFT blocks, the model explicitly captures dynamics across both macro- and micro- spatial scales. Furthermore, a generative residual correction mechanism is integrated to estimate and mitigate predictive uncertainties, enhancing both the accuracy and reliability of long-term forecasts. Evaluations conducted on three benchmark datasets (plasma, fluid, and atmospheric dynamics) demonstrate the advantages of our approach over state-of-the-art ML methods.
FTL: Transfer Learning Nonlinear Plasma Dynamic Transitions in Low Dimensional Embeddings via Deep Neural Networks
Apr 26, 2024Deep learning algorithms provide a new paradigm to study high-dimensional dynamical behaviors, such as those in fusion plasma systems. Development of novel model reduction methods, coupled with detection of abnormal modes with plasma physics, opens a unique opportunity for building efficient models to identify plasma instabilities for real-time control. Our Fusion Transfer Learning (FTL) model demonstrates success in reconstructing nonlinear kink mode structures by learning from a limited amount of nonlinear simulation data. The knowledge transfer process leverages a pre-trained neural encoder-decoder network, initially trained on linear simulations, to effectively capture nonlinear dynamics. The low-dimensional embeddings extract the coherent structures of interest, while preserving the inherent dynamics of the complex system. Experimental results highlight FTL's capacity to capture transitional behaviors and dynamical features in plasma dynamics -- a task often challenging for conventional methods. The model developed in this study is generalizable and can be extended broadly through transfer learning to address various magnetohydrodynamics (MHD) modes.
Hierarchical Roofline Performance Analysis for Deep Learning Applications
Sep 22, 2020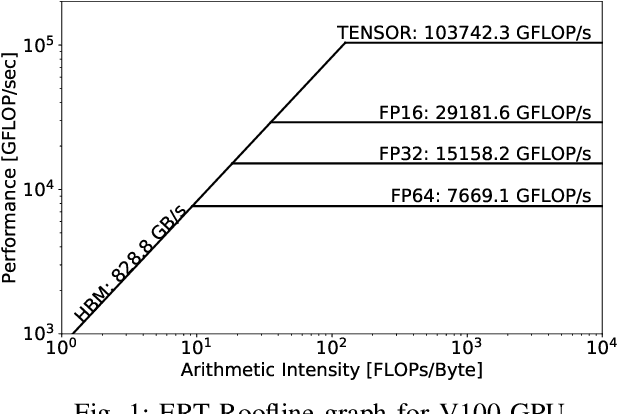
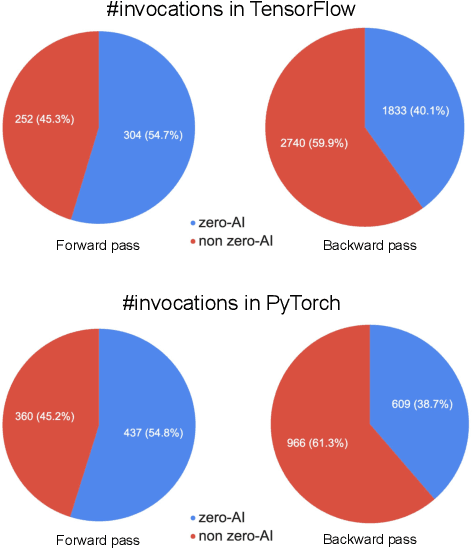
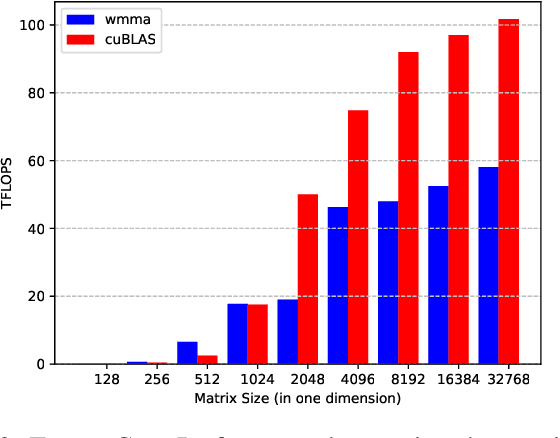
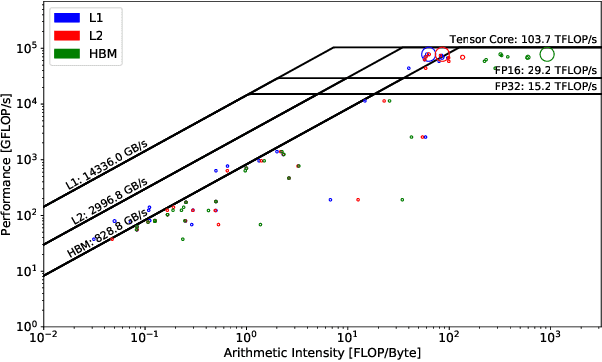
This paper presents a practical methodology for collecting performance data necessary to conduct hierarchical Roofline analysis on NVIDIA GPUs. It discusses the extension of the Empirical Roofline Toolkit for broader support of a range of data precisions and Tensor Core support and introduces a Nsight Compute based method to accurately collect application performance information. This methodology allows for automated machine characterization and application characterization for Roofline analysis across the entire memory hierarchy on NVIDIA GPUs, and it is validated by a complex deep learning application used for climate image segmentation. We use two versions of the code, in TensorFlow and PyTorch respectively, to demonstrate the use and effectiveness of this methodology. We highlight how the application utilizes the compute and memory capabilities on the GPU and how the implementation and performance differ in two deep learning frameworks.
Time-Based Roofline for Deep Learning Performance Analysis
Sep 22, 2020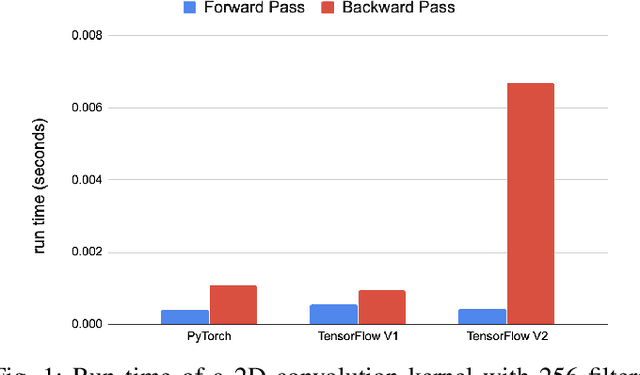
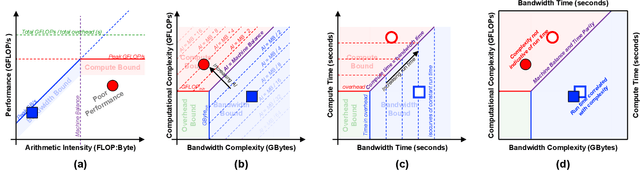
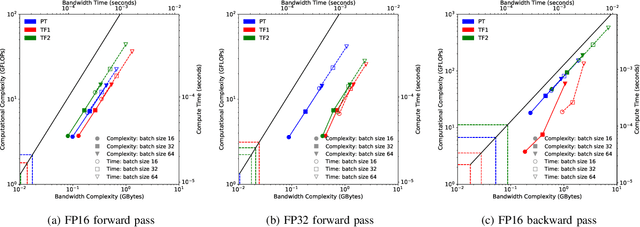
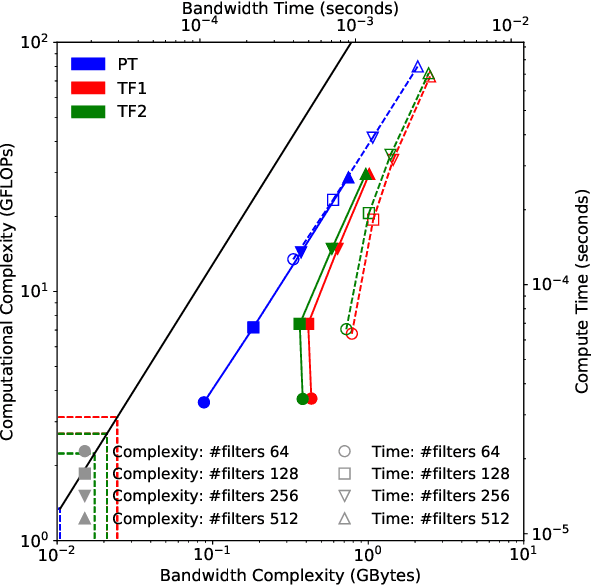
Deep learning applications are usually very compute-intensive and require a long run time for training and inference. This has been tackled by researchers from both hardware and software sides, and in this paper, we propose a Roofline-based approach to performance analysis to facilitate the optimization of these applications. This approach is an extension of the Roofline model widely used in traditional high-performance computing applications, and it incorporates both compute/bandwidth complexity and run time in its formulae to provide insights into deep learning-specific characteristics. We take two sets of representative kernels, 2D convolution and long short-term memory, to validate and demonstrate the use of this new approach, and investigate how arithmetic intensity, cache locality, auto-tuning, kernel launch overhead, and Tensor Core usage can affect performance. Compared to the common ad-hoc approach, this study helps form a more systematic way to analyze code performance and identify optimization opportunities for deep learning applications.