 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
Record-Remix-Replay: Hierarchical GPU Kernel Optimization using Evolutionary Search
Apr 13, 2026As high-performance computing and AI workloads become increasingly dependent on GPUs, maintaining high performance across rapidly evolving hardware generations has become a major challenge. Developers often spend months tuning scientific applications to fully exploit new architectures, navigating a complex optimization space that spans algorithm design, source implementation, compiler flags and pass sequences, and kernel launch parameters. Existing approaches can effectively search parts of this space in isolation, such as launch configurations or compiler settings, but optimizing across the full space still requires substantial human expertise and iterative manual effort. In this paper, we present Record-Remix-Replay (R^3), a hierarchical optimization framework that combines LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation techniques to efficiently explore GPU kernel optimizations from source-level implementation choices down to compiler pass ordering and runtime configuration. By making candidate evaluation fast and scalable, our approach enables practical end-to-end search over optimization dimensions that are typically treated separately. We show that Record-Remix-Replay can optimize full scientific applications better than traditional approaches over kernel parameters and compiler flags, while also being nearly an order of magnitude faster than modern evolutionary search approaches.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
Leveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
BOOM: Benchmarking Out-Of-distribution Molecular Property Predictions of Machine Learning Models
May 03, 2025Advances in deep learning and generative modeling have driven interest in data-driven molecule discovery pipelines, whereby machine learning (ML) models are used to filter and design novel molecules without requiring prohibitively expensive first-principles simulations. Although the discovery of novel molecules that extend the boundaries of known chemistry requires accurate out-of-distribution (OOD) predictions, ML models often struggle to generalize OOD. Furthermore, there are currently no systematic benchmarks for molecular OOD prediction tasks. We present BOOM, $\boldsymbol{b}$enchmarks for $\boldsymbol{o}$ut-$\boldsymbol{o}$f-distribution $\boldsymbol{m}$olecular property predictions -- a benchmark study of property-based out-of-distribution models for common molecular property prediction models. We evaluate more than 140 combinations of models and property prediction tasks to benchmark deep learning models on their OOD performance. Overall, we do not find any existing models that achieve strong OOD generalization across all tasks: even the top performing model exhibited an average OOD error 3x larger than in-distribution. We find that deep learning models with high inductive bias can perform well on OOD tasks with simple, specific properties. Although chemical foundation models with transfer and in-context learning offer a promising solution for limited training data scenarios, we find that current foundation models do not show strong OOD extrapolation capabilities. We perform extensive ablation experiments to highlight how OOD performance is impacted by data generation, pre-training, hyperparameter optimization, model architecture, and molecular representation. We propose that developing ML models with strong OOD generalization is a new frontier challenge in chemical ML model development. This open-source benchmark will be made available on Github.
Trajectory Balance with Asynchrony: Decoupling Exploration and Learning for Fast, Scalable LLM Post-Training
Mar 24, 2025Reinforcement learning (RL) is a critical component of large language model (LLM) post-training. However, existing on-policy algorithms used for post-training are inherently incompatible with the use of experience replay buffers, which can be populated scalably by distributed off-policy actors to enhance exploration as compute increases. We propose efficiently obtaining this benefit of replay buffers via Trajectory Balance with Asynchrony (TBA), a massively scalable LLM RL system. In contrast to existing approaches, TBA uses a larger fraction of compute on search, constantly generating off-policy data for a central replay buffer. A training node simultaneously samples data from this buffer based on reward or recency to update the policy using Trajectory Balance (TB), a diversity-seeking RL objective introduced for GFlowNets. TBA offers three key advantages: (1) decoupled training and search, speeding up training wall-clock time by 4x or more; (2) improved diversity through large-scale off-policy sampling; and (3) scalable search for sparse reward settings. On mathematical reasoning, preference-tuning, and automated red-teaming (diverse and representative post-training tasks), TBA produces speed and performance improvements over strong baselines.
Lion Cub: Minimizing Communication Overhead in Distributed Lion
Nov 25, 2024Communication overhead is a key challenge in distributed deep learning, especially on slower Ethernet interconnects, and given current hardware trends, communication is likely to become a major bottleneck. While gradient compression techniques have been explored for SGD and Adam, the Lion optimizer has the distinct advantage that its update vectors are the output of a sign operation, enabling straightforward quantization. However, simply compressing updates for communication and using techniques like majority voting fails to lead to end-to-end speedups due to inefficient communication algorithms and reduced convergence. We analyze three factors critical to distributed learning with Lion: optimizing communication methods, identifying effective quantization methods, and assessing the necessity of momentum synchronization. Our findings show that quantization techniques adapted to Lion and selective momentum synchronization can significantly reduce communication costs while maintaining convergence. We combine these into Lion Cub, which enables up to 5x speedups in end-to-end training compared to Lion. This highlights Lion's potential as a communication-efficient solution for distributed training.
VENOM: A Vectorized N:M Format for Unleashing the Power of Sparse Tensor Cores
Oct 03, 2023



The increasing success and scaling of Deep Learning models demands higher computational efficiency and power. Sparsification can lead to both smaller models as well as higher compute efficiency, and accelerated hardware is becoming available. However, exploiting it efficiently requires kernel implementations, pruning algorithms, and storage formats, to utilize hardware support of specialized sparse vector units. An example of those are the NVIDIA's Sparse Tensor Cores (SPTCs), which promise a 2x speedup. However, SPTCs only support the 2:4 format, limiting achievable sparsity ratios to 50%. We present the V:N:M format, which enables the execution of arbitrary N:M ratios on SPTCs. To efficiently exploit the resulting format, we propose Spatha, a high-performance sparse-library for DL routines. We show that Spatha achieves up to 37x speedup over cuBLAS. We also demonstrate a second-order pruning technique that enables sparsification to high sparsity ratios with V:N:M and little to no loss in accuracy in modern transformers.
Cached Operator Reordering: A Unified View for Fast GNN Training
Aug 23, 2023Graph Neural Networks (GNNs) are a powerful tool for handling structured graph data and addressing tasks such as node classification, graph classification, and clustering. However, the sparse nature of GNN computation poses new challenges for performance optimization compared to traditional deep neural networks. We address these challenges by providing a unified view of GNN computation, I/O, and memory. By analyzing the computational graphs of the Graph Convolutional Network (GCN) and Graph Attention (GAT) layers -- two widely used GNN layers -- we propose alternative computation strategies. We present adaptive operator reordering with caching, which achieves a speedup of up to 2.43x for GCN compared to the current state-of-the-art. Furthermore, an exploration of different caching schemes for GAT yields a speedup of up to 1.94x. The proposed optimizations save memory, are easily implemented across various hardware platforms, and have the potential to alleviate performance bottlenecks in training large-scale GNN models.
STen: Productive and Efficient Sparsity in PyTorch
Apr 15, 2023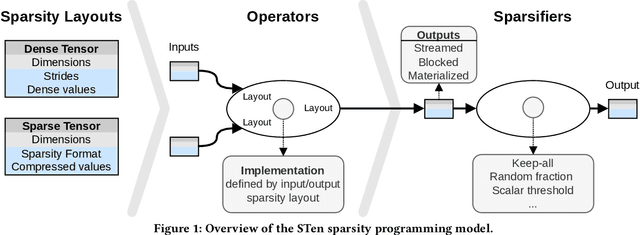
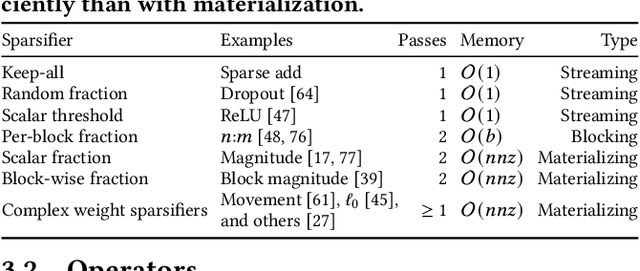
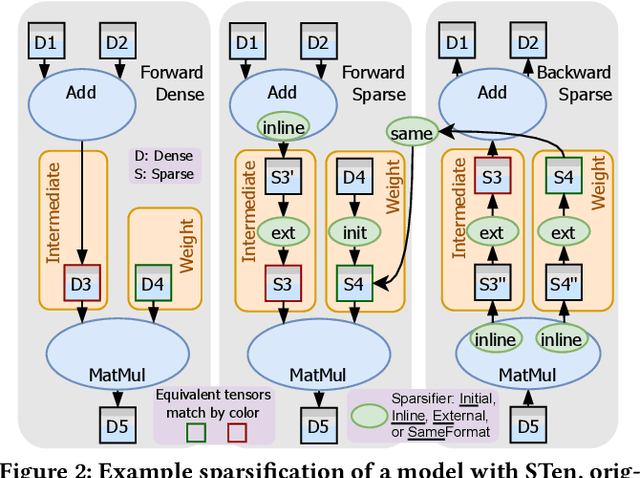
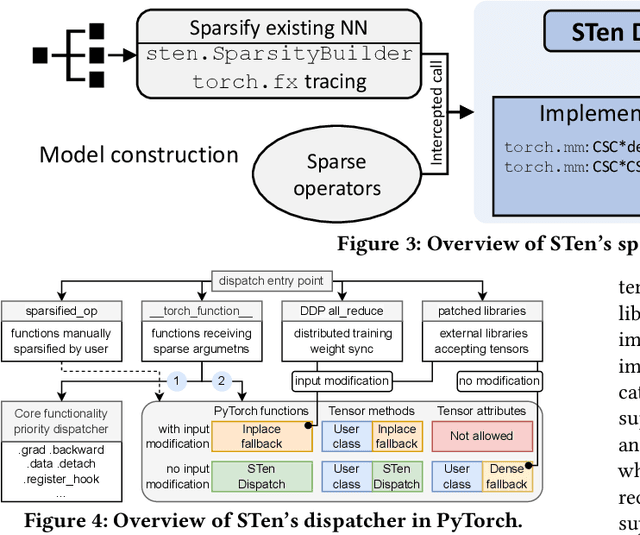
As deep learning models grow, sparsity is becoming an increasingly critical component of deep neural networks, enabling improved performance and reduced storage. However, existing frameworks offer poor support for sparsity. Specialized sparsity engines focus exclusively on sparse inference, while general frameworks primarily focus on sparse tensors in classical formats and neglect the broader sparsification pipeline necessary for using sparse models, especially during training. Further, existing frameworks are not easily extensible: adding a new sparse tensor format or operator is challenging and time-consuming. To address this, we propose STen, a sparsity programming model and interface for PyTorch, which incorporates sparsity layouts, operators, and sparsifiers, in an efficient, customizable, and extensible framework that supports virtually all sparsification methods. We demonstrate this by developing a high-performance grouped n:m sparsity layout for CPU inference at moderate sparsity. STen brings high performance and ease of use to the ML community, making sparsity easily accessible.