 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuartet: Native FP4 Training Can Be Optimal for Large Language Models
May 20, 2025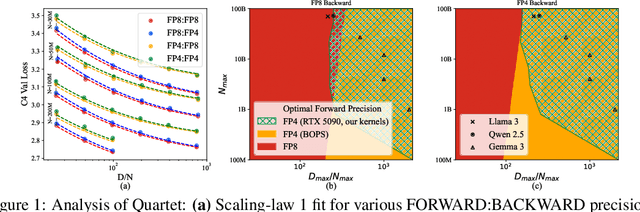


The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA's recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a "near-optimal" low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
HALO: Hadamard-Assisted Lossless Optimization for Efficient Low-Precision LLM Training and Fine-Tuning
Jan 05, 2025



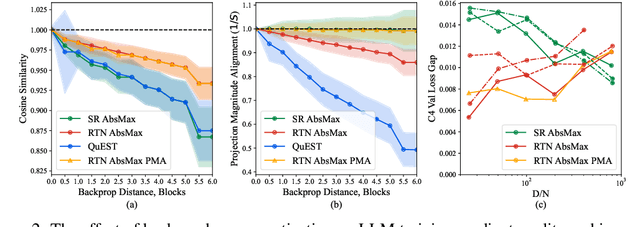
Quantized training of Large Language Models (LLMs) remains an open challenge, as maintaining accuracy while performing all matrix multiplications in low precision has proven difficult. This is particularly the case when fine-tuning pre-trained models, which often already have large weight and activation outlier values that render quantized optimization difficult. We present HALO, a novel quantization-aware training approach for Transformers that enables accurate and efficient low-precision training by combining 1) strategic placement of Hadamard rotations in both forward and backward passes, to mitigate outliers during the low-precision computation, 2) FSDP integration for low-precision communication, and 3) high-performance kernel support. Our approach ensures that all large matrix multiplications during the forward and backward passes are executed in lower precision. Applied to LLAMA-family models, HALO achieves near-full-precision-equivalent results during fine-tuning on various tasks, while delivering up to 1.31x end-to-end speedup for full fine-tuning on RTX 4090 GPUs. Our method supports both standard and parameter-efficient fine-tuning (PEFT) methods, both backed by efficient kernel implementations. Our results demonstrate the first practical approach to fully quantized LLM fine-tuning that maintains accuracy in FP8 precision, while delivering performance benefits.
EfQAT: An Efficient Framework for Quantization-Aware Training
Nov 17, 2024



Quantization-aware training (QAT) schemes have been shown to achieve near-full precision accuracy. They accomplish this by training a quantized model for multiple epochs. This is computationally expensive, mainly because of the full precision backward pass. On the other hand, post-training quantization (PTQ) schemes do not involve training and are therefore computationally cheap, but they usually result in a significant accuracy drop. We address these challenges by proposing EfQAT, which generalizes both schemes by optimizing only a subset of the parameters of a quantized model. EfQAT starts by applying a PTQ scheme to a pre-trained model and only updates the most critical network parameters while freezing the rest, accelerating the backward pass. We demonstrate the effectiveness of EfQAT on various CNNs and Transformer-based models using different GPUs. Specifically, we show that EfQAT is significantly more accurate than PTQ with little extra compute. Furthermore, EfQAT can accelerate the QAT backward pass between 1.44-1.64x while retaining most accuracy.
Computational Bottlenecks of Training Small-scale Large Language Models
Oct 25, 2024



While large language models (LLMs) dominate the AI landscape, Small-scale large Language Models (SLMs) are gaining attention due to cost and efficiency demands from consumers. However, there is limited research on the training behavior and computational requirements of SLMs. In this study, we explore the computational bottlenecks of training SLMs (up to 2B parameters) by examining the effects of various hyperparameters and configurations, including GPU type, batch size, model size, communication protocol, attention type, and the number of GPUs. We assess these factors on popular cloud services using metrics such as loss per dollar and tokens per second. Our findings aim to support the broader adoption and optimization of language model training for low-resource AI research institutes.
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Mar 30, 2024



We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way that removes outliers from the hidden state without changing the output, making quantization easier. This computational invariance is applied to the hidden state (residual) of the LLM, as well as to the activations of the feed-forward components, aspects of the attention mechanism and to the KV cache. The result is a quantized model where all matrix multiplications are performed in 4-bits, without any channels identified for retention in higher precision. Our quantized LLaMa2-70B model has losses of at most 0.29 WikiText-2 perplexity and retains 99% of the zero-shot performance. Code is available at: https://github.com/spcl/QuaRot.
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
Jan 26, 2024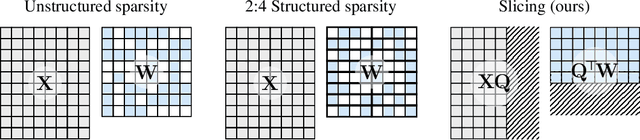
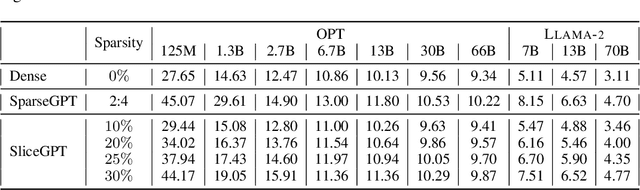

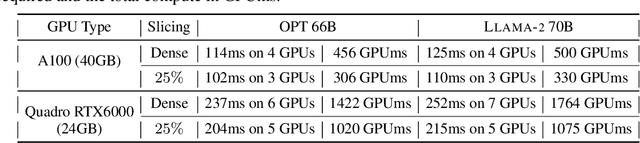
Large language models have become the cornerstone of natural language processing, but their use comes with substantial costs in terms of compute and memory resources. Sparsification provides a solution to alleviate these resource constraints, and recent works have shown that trained models can be sparsified post-hoc. Existing sparsification techniques face challenges as they need additional data structures and offer constrained speedup with current hardware. In this paper we present SliceGPT, a new post-training sparsification scheme which replaces each weight matrix with a smaller (dense) matrix, reducing the embedding dimension of the network. Through extensive experimentation, we show that SliceGPT can remove up to 25% of the model parameters (including embeddings) for LLAMA2-70B, OPT 66B and Phi-2 models while maintaining 99%, 99% and 90% zero-shot task performance of the dense model respectively. Our sliced models run on fewer GPUs and run faster without any additional code optimization: on 24GB consumer GPUs we reduce the total compute for inference on LLAMA2-70B to 64% of that of the dense model; on 40GB A100 GPUs we reduce it to 66%. We offer a new insight, computational invariance in transformer networks, which enables SliceGPT and we hope it will inspire and enable future avenues to reduce memory and computation demands for pre-trained models. Code is available at: https://github.com/microsoft/TransformerCompression
Towards End-to-end 4-Bit Inference on Generative Large Language Models
Oct 13, 2023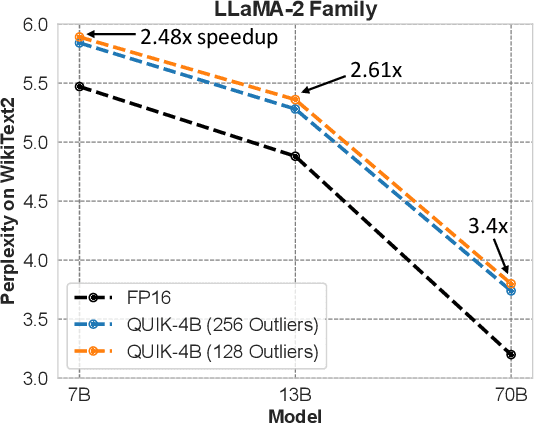
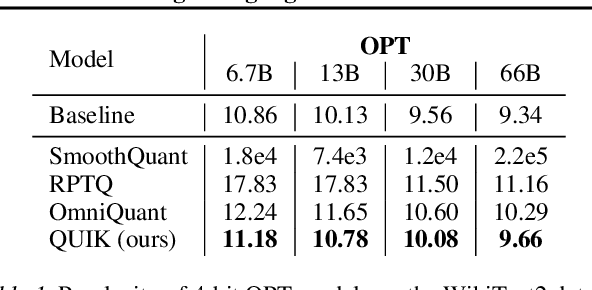
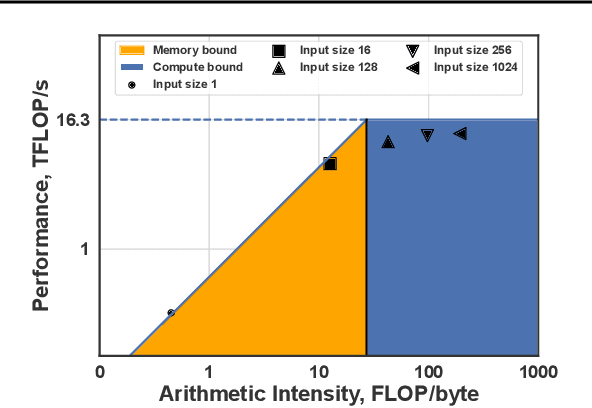
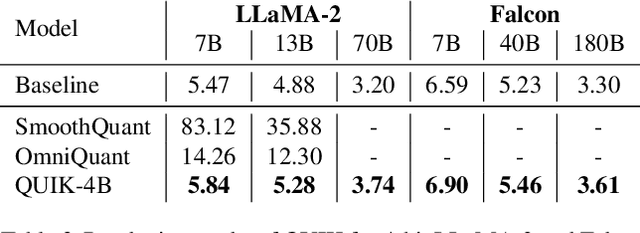
We show that the majority of the inference computations for large generative models such as LLaMA and OPT can be performed with both weights and activations being cast to 4 bits, in a way that leads to practical speedups while at the same time maintaining good accuracy. We achieve this via a hybrid quantization strategy called QUIK, which compresses most of the weights and activations to 4-bit, while keeping some outlier weights and activations in higher-precision. Crucially, our scheme is designed with computational efficiency in mind: we provide GPU kernels with highly-efficient layer-wise runtimes, which lead to practical end-to-end throughput improvements of up to 3.1x relative to FP16 execution. Code and models are provided at https://github.com/IST-DASLab/QUIK.
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
Jun 05, 2023

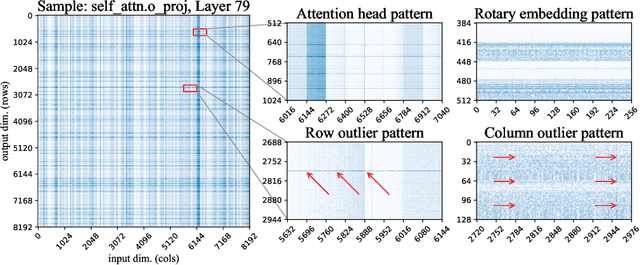

Recent advances in large language model (LLM) pretraining have led to high-quality LLMs with impressive abilities. By compressing such LLMs via quantization to 3-4 bits per parameter, they can fit into memory-limited devices such as laptops and mobile phones, enabling personalized use. However, quantization down to 3-4 bits per parameter usually leads to moderate-to-high accuracy losses, especially for smaller models in the 1-10B parameter range, which are well-suited for edge deployments. To address this accuracy issue, we introduce the Sparse-Quantized Representation (SpQR), a new compressed format and quantization technique which enables for the first time near-lossless compression of LLMs across model scales, while reaching similar compression levels to previous methods. SpQR works by identifying and isolating outlier weights, which cause particularly-large quantization errors, and storing them in higher precision, while compressing all other weights to 3-4 bits, and achieves relative accuracy losses of less than 1% in perplexity for highly-accurate LLaMA and Falcon LLMs. This makes it possible to run 33B parameter LLM on a single 24 GB consumer GPU without any performance degradation at 15% speedup thus making powerful LLMs available to consumer without any downsides. SpQR comes with efficient algorithms for both encoding weights into its format, as well as decoding them efficiently at runtime. Specifically, we provide an efficient GPU inference algorithm for SpQR which yields faster inference than 16-bit baselines at similar accuracy, while enabling memory compression gains of more than 4x.
STen: Productive and Efficient Sparsity in PyTorch
Apr 15, 2023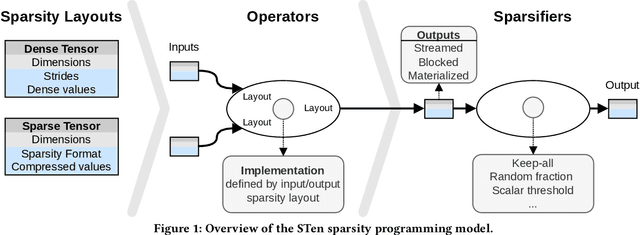
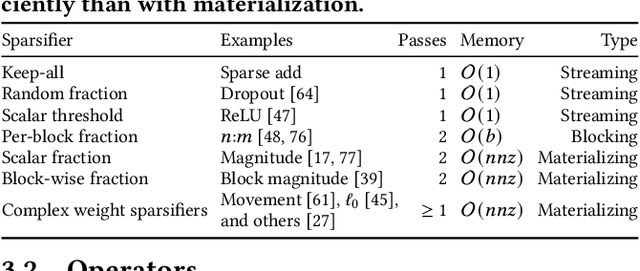
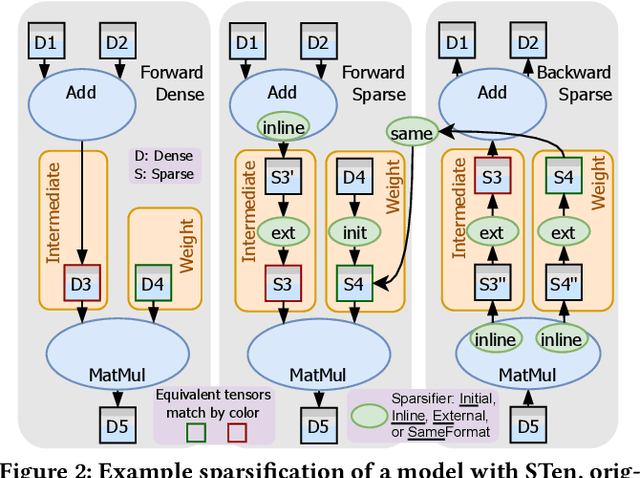
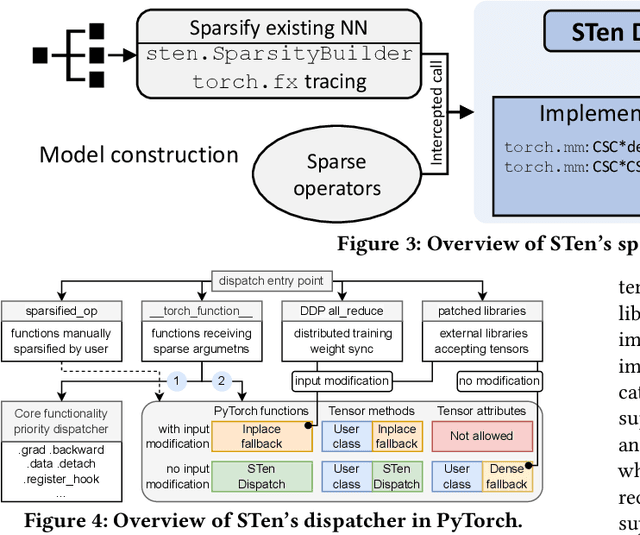
As deep learning models grow, sparsity is becoming an increasingly critical component of deep neural networks, enabling improved performance and reduced storage. However, existing frameworks offer poor support for sparsity. Specialized sparsity engines focus exclusively on sparse inference, while general frameworks primarily focus on sparse tensors in classical formats and neglect the broader sparsification pipeline necessary for using sparse models, especially during training. Further, existing frameworks are not easily extensible: adding a new sparse tensor format or operator is challenging and time-consuming. To address this, we propose STen, a sparsity programming model and interface for PyTorch, which incorporates sparsity layouts, operators, and sparsifiers, in an efficient, customizable, and extensible framework that supports virtually all sparsification methods. We demonstrate this by developing a high-performance grouped n:m sparsity layout for CPU inference at moderate sparsity. STen brings high performance and ease of use to the ML community, making sparsity easily accessible.
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Oct 31, 2022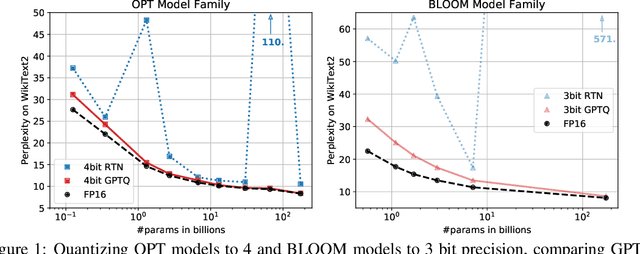
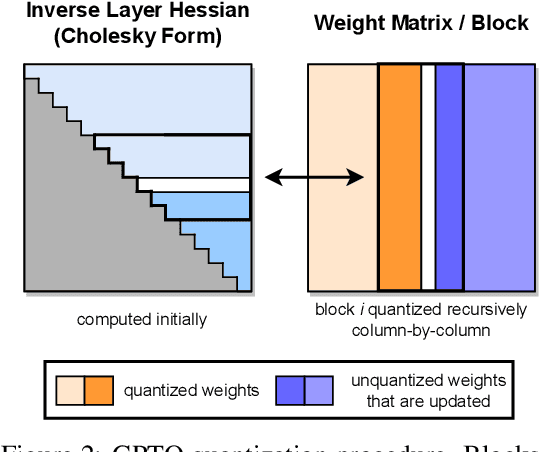

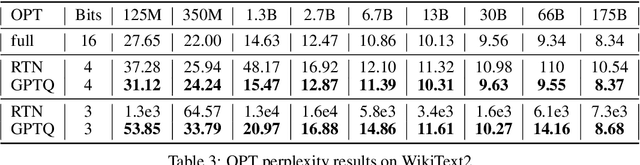
Generative Pre-trained Transformer (GPT) models set themselves apart through breakthrough performance across complex language modelling tasks, but also by their extremely high computational and storage costs. Specifically, due to their massive size, even inference for large, highly-accurate GPT models may require multiple performant GPUs to execute, which limits the usability of such models. While there is emerging work on relieving this pressure via model compression, the applicability and performance of existing compression techniques is limited by the scale and complexity of GPT models. In this paper, we address this challenge, and propose GPTQ, a new one-shot weight quantization method based on approximate second-order information, that is both highly-accurate and highly-efficient. Specifically, GPTQ can quantize GPT models with 175 billion parameters in approximately four GPU hours, reducing the bitwidth down to 3 or 4 bits per weight, with negligible accuracy degradation relative to the uncompressed baseline. Our method more than doubles the compression gains relative to previously-proposed one-shot quantization methods, preserving accuracy, allowing us for the first time to execute an 175 billion-parameter model inside a single GPU. We show experimentally that these improvements can be leveraged for end-to-end inference speedups over FP16, of around 2x when using high-end GPUs (NVIDIA A100) and 4x when using more cost-effective ones (NVIDIA A6000). The implementation is available at https://github.com/IST-DASLab/gptq.