 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
May 20, 2025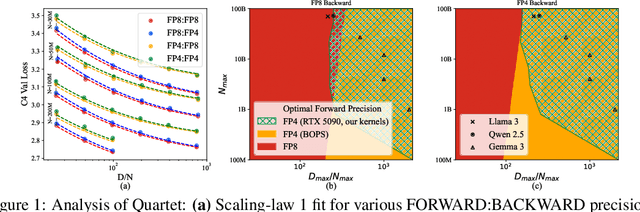


The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA's recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a "near-optimal" low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
DarwinLM: Evolutionary Structured Pruning of Large Language Models
Feb 11, 2025



Large Language Models (LLMs) have achieved significant success across various NLP tasks. However, their massive computational costs limit their widespread use, particularly in real-time applications. Structured pruning offers an effective solution by compressing models and directly providing end-to-end speed improvements, regardless of the hardware environment. Meanwhile, different components of the model exhibit varying sensitivities towards pruning, calling for \emph{non-uniform} model compression. However, a pruning method should not only identify a capable substructure, but also account for post-compression training. To this end, we propose \sysname, a method for \emph{training-aware} structured pruning. \sysname builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. To assess the effect of post-training, we incorporate a lightweight, multistep training process within the offspring population, progressively increasing the number of tokens and eliminating poorly performing models in each selection stage. We validate our method through extensive experiments on Llama-2-7B, Llama-3.1-8B and Qwen-2.5-14B-Instruct, achieving state-of-the-art performance for structured pruning. For instance, \sysname surpasses ShearedLlama while requiring $5\times$ less training data during post-compression training.
EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search
Oct 18, 2024



The high computational costs of large language models (LLMs) have led to a flurry of research on LLM compression, via methods such as quantization, sparsification, or structured pruning. A new frontier in this area is given by \emph{dynamic, non-uniform} compression methods, which adjust the compression levels (e.g., sparsity) per-block or even per-layer in order to minimize accuracy loss, while guaranteeing a global compression threshold. Yet, current methods rely on heuristics for identifying the "importance" of a given layer towards the loss, based on assumptions such as \emph{error monotonicity}, i.e. that the end-to-end model compression error is proportional to the sum of layer-wise errors. In this paper, we revisit this area, and propose a new and general approach for dynamic compression that is provably optimal in a given input range. We begin from the motivating observation that, in general, \emph{error monotonicity does not hold for LLMs}: compressed models with lower sum of per-layer errors can perform \emph{worse} than models with higher error sums. To address this, we propose a new general evolutionary framework for dynamic LLM compression called EvoPress, which has provable convergence, and low sample and evaluation complexity. We show that these theoretical guarantees lead to highly competitive practical performance for dynamic compression of Llama, Mistral and Phi models. Via EvoPress, we set new state-of-the-art results across all compression approaches: structural pruning (block/layer dropping), unstructured sparsity, as well as quantization with dynamic bitwidths. Our code is available at https://github.com/IST-DASLab/EvoPress.
Plus Strategies are Exponentially Slower for Planted Optima of Random Height
Apr 15, 2024



We compare the $(1,\lambda)$-EA and the $(1 + \lambda)$-EA on the recently introduced benchmark DisOM, which is the OneMax function with randomly planted local optima. Previous work showed that if all local optima have the same relative height, then the plus strategy never loses more than a factor $O(n\log n)$ compared to the comma strategy. Here we show that even small random fluctuations in the heights of the local optima have a devastating effect for the plus strategy and lead to super-polynomial runtimes. On the other hand, due to their ability to escape local optima, comma strategies are unaffected by the height of the local optima and remain efficient. Our results hold for a broad class of possible distortions and show that the plus strategy, but not the comma strategy, is generally deceived by sparse unstructured fluctuations of a smooth landscape.
Hardest Monotone Functions for Evolutionary Algorithms
Nov 13, 2023The study of hardest and easiest fitness landscapes is an active area of research. Recently, Kaufmann, Larcher, Lengler and Zou conjectured that for the self-adjusting $(1,\lambda)$-EA, Adversarial Dynamic BinVal (ADBV) is the hardest dynamic monotone function to optimize. We introduce the function Switching Dynamic BinVal (SDBV) which coincides with ADBV whenever the number of remaining zeros in the search point is strictly less than $n/2$, where $n$ denotes the dimension of the search space. We show, using a combinatorial argument, that for the $(1+1)$-EA with any mutation rate $p \in [0,1]$, SDBV is drift-minimizing among the class of dynamic monotone functions. Our construction provides the first explicit example of an instance of the partially-ordered evolutionary algorithm (PO-EA) model with parameterized pessimism introduced by Colin, Doerr and F\'erey, building on work of Jansen. We further show that the $(1+1)$-EA optimizes SDBV in $\Theta(n^{3/2})$ generations. Our simulations demonstrate matching runtimes for both static and self-adjusting $(1,\lambda)$ and $(1+\lambda)$-EA. We further show, using an example of fixed dimension, that drift-minimization does not equal maximal runtime.