 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Models Generate Societies of Thought
Jan 15, 2026Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive. Recent reasoning models outperform comparable instruction-tuned models on complex cognitive tasks, attributed to extended computation through longer chains of thought. Here we show that enhanced reasoning emerges not from extended computation alone, but from simulating multi-agent-like interactions -- a society of thought -- which enables diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis and mechanistic interpretability methods applied to reasoning traces, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviors, including question-answering, perspective shifts, and the reconciliation of conflicting views, and in socio-emotional roles that characterize sharp back-and-forth conversations, together accounting for the accuracy advantage in reasoning tasks. Controlled reinforcement learning experiments reveal that base models increase conversational behaviors when rewarded solely for reasoning accuracy, and fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups, where diversity enables superior problem-solving when systematically structured, which suggests new opportunities for agent organization to harness the wisdom of crowds.
Emergent temporal abstractions in autoregressive models enable hierarchical reinforcement learning
Dec 24, 2025Large-scale autoregressive models pretrained on next-token prediction and finetuned with reinforcement learning (RL) have achieved unprecedented success on many problem domains. During RL, these models explore by generating new outputs, one token at a time. However, sampling actions token-by-token can result in highly inefficient learning, particularly when rewards are sparse. Here, we show that it is possible to overcome this problem by acting and exploring within the internal representations of an autoregressive model. Specifically, to discover temporally-abstract actions, we introduce a higher-order, non-causal sequence model whose outputs control the residual stream activations of a base autoregressive model. On grid world and MuJoCo-based tasks with hierarchical structure, we find that the higher-order model learns to compress long activation sequence chunks onto internal controllers. Critically, each controller executes a sequence of behaviorally meaningful actions that unfold over long timescales and are accompanied with a learned termination condition, such that composing multiple controllers over time leads to efficient exploration on novel tasks. We show that direct internal controller reinforcement, a process we term "internal RL", enables learning from sparse rewards in cases where standard RL finetuning fails. Our results demonstrate the benefits of latent action generation and reinforcement in autoregressive models, suggesting internal RL as a promising avenue for realizing hierarchical RL within foundation models.
Do Depth-Grown Models Overcome the Curse of Depth? An In-Depth Analysis
Dec 09, 2025Gradually growing the depth of Transformers during training can not only reduce training cost but also lead to improved reasoning performance, as shown by MIDAS (Saunshi et al., 2024). Thus far, however, a mechanistic understanding of these gains has been missing. In this work, we establish a connection to recent work showing that layers in the second half of non-grown, pre-layernorm Transformers contribute much less to the final output distribution than those in the first half - also known as the Curse of Depth (Sun et al., 2025, Csordás et al., 2025). Using depth-wise analyses, we demonstrate that growth via gradual middle stacking yields more effective utilization of model depth, alters the residual stream structure, and facilitates the formation of permutable computational blocks. In addition, we propose a lightweight modification of MIDAS that yields further improvements in downstream reasoning benchmarks. Overall, this work highlights how the gradual growth of model depth can lead to the formation of distinct computational circuits and overcome the limited depth utilization seen in standard non-grown models.
No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
Sep 09, 2025Large language models (LLMs) are increasingly integrated into our daily lives and personalized. However, LLM personalization might also increase unintended side effects. Recent work suggests that persona prompting can lead models to falsely refuse user requests. However, no work has fully quantified the extent of this issue. To address this gap, we measure the impact of 15 sociodemographic personas (based on gender, race, religion, and disability) on false refusal. To control for other factors, we also test 16 different models, 3 tasks (Natural Language Inference, politeness, and offensiveness classification), and nine prompt paraphrases. We propose a Monte Carlo-based method to quantify this issue in a sample-efficient manner. Our results show that as models become more capable, personas impact the refusal rate less and less. Certain sociodemographic personas increase false refusal in some models, which suggests underlying biases in the alignment strategies or safety mechanisms. However, we find that the model choice and task significantly influence false refusals, especially in sensitive content tasks. Our findings suggest that persona effects have been overestimated, and might be due to other factors.
MesaNet: Sequence Modeling by Locally Optimal Test-Time Training
Jun 05, 2025Sequence modeling is currently dominated by causal transformer architectures that use softmax self-attention. Although widely adopted, transformers require scaling memory and compute linearly during inference. A recent stream of work linearized the softmax operation, resulting in powerful recurrent neural network (RNN) models with constant memory and compute costs such as DeltaNet, Mamba or xLSTM. These models can be unified by noting that their recurrent layer dynamics can all be derived from an in-context regression objective, approximately optimized through an online learning rule. Here, we join this line of work and introduce a numerically stable, chunkwise parallelizable version of the recently proposed Mesa layer (von Oswald et al., 2024), and study it in language modeling at the billion-parameter scale. This layer again stems from an in-context loss, but which is now minimized to optimality at every time point using a fast conjugate gradient solver. Through an extensive suite of experiments, we show that optimal test-time training enables reaching lower language modeling perplexity and higher downstream benchmark performance than previous RNNs, especially on tasks requiring long context understanding. This performance gain comes at the cost of additional flops spent during inference time. Our results are therefore intriguingly related to recent trends of increasing test-time compute to improve performance -- here by spending compute to solve sequential optimization problems within the neural network itself.
Review, Refine, Repeat: Understanding Iterative Decoding of AI Agents with Dynamic Evaluation and Selection
Apr 02, 2025While AI agents have shown remarkable performance at various tasks, they still struggle with complex multi-modal applications, structured generation and strategic planning. Improvements via standard fine-tuning is often impractical, as solving agentic tasks usually relies on black box API access without control over model parameters. Inference-time methods such as Best-of-N (BON) sampling offer a simple yet effective alternative to improve performance. However, BON lacks iterative feedback integration mechanism. Hence, we propose Iterative Agent Decoding (IAD) which combines iterative refinement with dynamic candidate evaluation and selection guided by a verifier. IAD differs in how feedback is designed and integrated, specifically optimized to extract maximal signal from reward scores. We conduct a detailed comparison of baselines across key metrics on Sketch2Code, Text2SQL, and Webshop where IAD consistently outperforms baselines, achieving 3--6% absolute gains on Sketch2Code and Text2SQL (with and without LLM judges) and 8--10% gains on Webshop across multiple metrics. To better understand the source of IAD's gains, we perform controlled experiments to disentangle the effect of adaptive feedback from stochastic sampling, and find that IAD's improvements are primarily driven by verifier-guided refinement, not merely sampling diversity. We also show that both IAD and BON exhibit inference-time scaling with increased compute when guided by an optimal verifier. Our analysis highlights the critical role of verifier quality in effective inference-time optimization and examines the impact of noisy and sparse rewards on scaling behavior. Together, these findings offer key insights into the trade-offs and principles of effective inference-time optimization.
Not Every AI Problem is a Data Problem: We Should Be Intentional About Data Scaling
Jan 23, 2025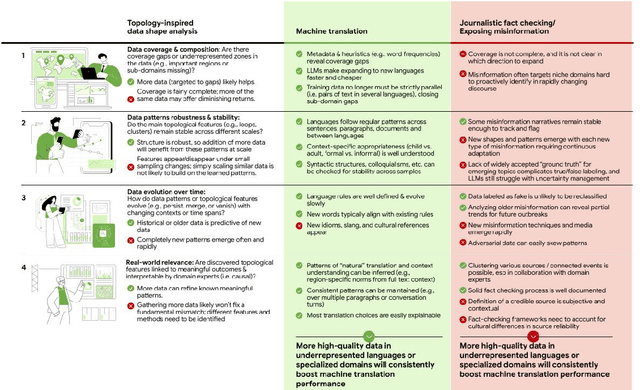
While Large Language Models require more and more data to train and scale, rather than looking for any data to acquire, we should consider what types of tasks are more likely to benefit from data scaling. We should be intentional in our data acquisition. We argue that the topology of data itself informs which tasks to prioritize in data scaling, and shapes the development of the next generation of compute paradigms for tasks where data scaling is inefficient, or even insufficient.
Multi-agent cooperation through learning-aware policy gradients
Oct 24, 2024
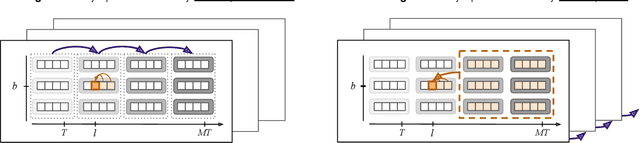

Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
FinanceBench: A New Benchmark for Financial Question Answering
Nov 20, 2023
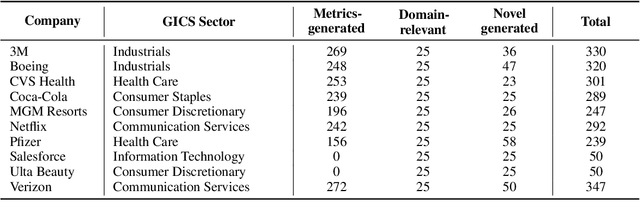
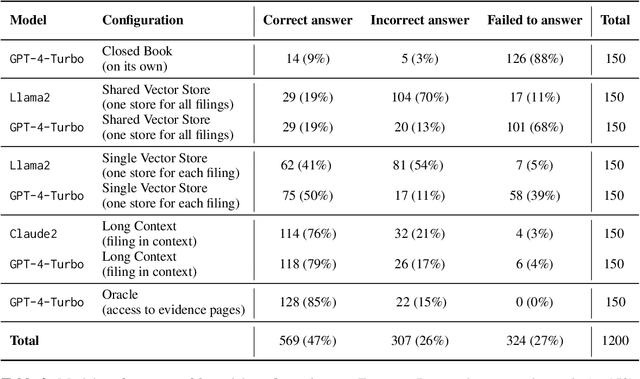

FinanceBench is a first-of-its-kind test suite for evaluating the performance of LLMs on open book financial question answering (QA). It comprises 10,231 questions about publicly traded companies, with corresponding answers and evidence strings. The questions in FinanceBench are ecologically valid and cover a diverse set of scenarios. They are intended to be clear-cut and straightforward to answer to serve as a minimum performance standard. We test 16 state of the art model configurations (including GPT-4-Turbo, Llama2 and Claude2, with vector stores and long context prompts) on a sample of 150 cases from FinanceBench, and manually review their answers (n=2,400). The cases are available open-source. We show that existing LLMs have clear limitations for financial QA. Notably, GPT-4-Turbo used with a retrieval system incorrectly answered or refused to answer 81% of questions. While augmentation techniques such as using longer context window to feed in relevant evidence improve performance, they are unrealistic for enterprise settings due to increased latency and cannot support larger financial documents. We find that all models examined exhibit weaknesses, such as hallucinations, that limit their suitability for use by enterprises.