 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Improves Self-Consistency in LLMs
Feb 10, 2025Self-consistency decoding enhances LLMs' performance on reasoning tasks by sampling diverse reasoning paths and selecting the most frequent answer. However, it is computationally expensive, as sampling many of these (lengthy) paths is required to increase the chances that the correct answer emerges as the most frequent one. To address this, we introduce Confidence-Informed Self-Consistency (CISC). CISC performs a weighted majority vote based on confidence scores obtained directly from the model. By prioritizing high-confidence paths, it can identify the correct answer with a significantly smaller sample size. When tested on nine models and four datasets, CISC outperforms self-consistency in nearly all configurations, reducing the required number of reasoning paths by over 40% on average. In addition, we introduce the notion of within-question confidence evaluation, after showing that standard evaluation methods are poor predictors of success in distinguishing correct and incorrect answers to the same question. In fact, the most calibrated confidence method proved to be the least effective for CISC. Lastly, beyond these practical implications, our results and analyses show that LLMs can effectively judge the correctness of their own outputs, contributing to the ongoing debate on this topic.
Multi-environment Topic Models
Oct 31, 2024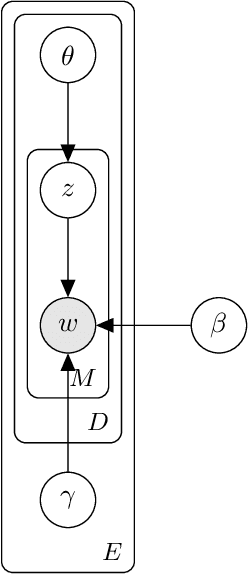
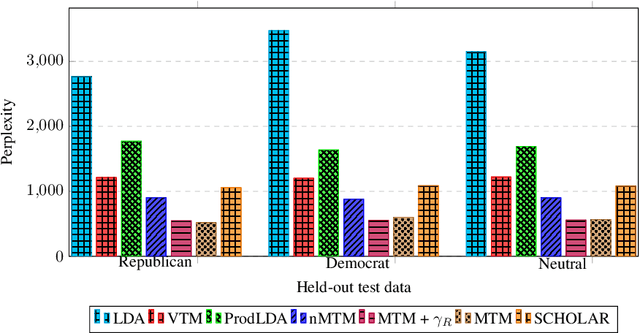

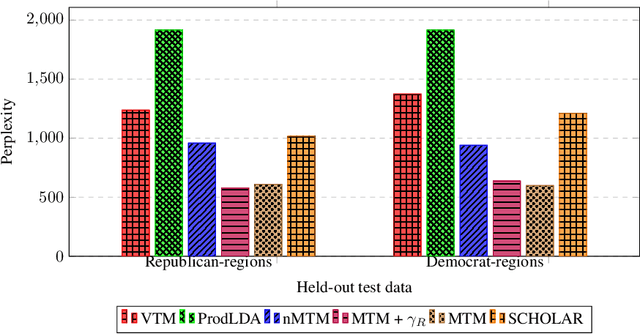
Probabilistic topic models are a powerful tool for extracting latent themes from large text datasets. In many text datasets, we also observe per-document covariates (e.g., source, style, political affiliation) that act as environments that modulate a "global" (environment-agnostic) topic representation. Accurately learning these representations is important for prediction on new documents in unseen environments and for estimating the causal effect of topics on real-world outcomes. To this end, we introduce the Multi-environment Topic Model (MTM), an unsupervised probabilistic model that separates global and environment-specific terms. Through experimentation on various political content, from ads to tweets and speeches, we show that the MTM produces interpretable global topics with distinct environment-specific words. On multi-environment data, the MTM outperforms strong baselines in and out-of-distribution. It also enables the discovery of accurate causal effects.
Exploring the Learning Capabilities of Language Models using LEVERWORLDS
Oct 01, 2024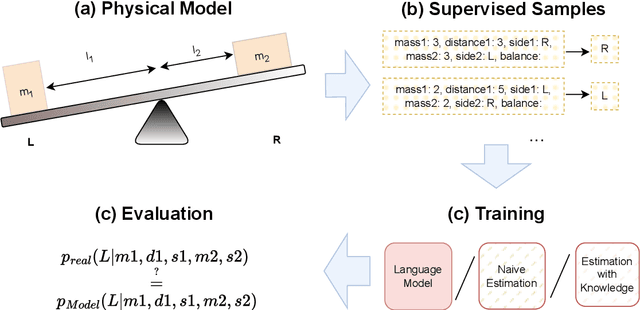
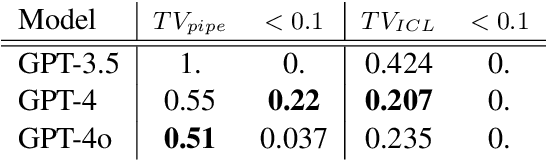
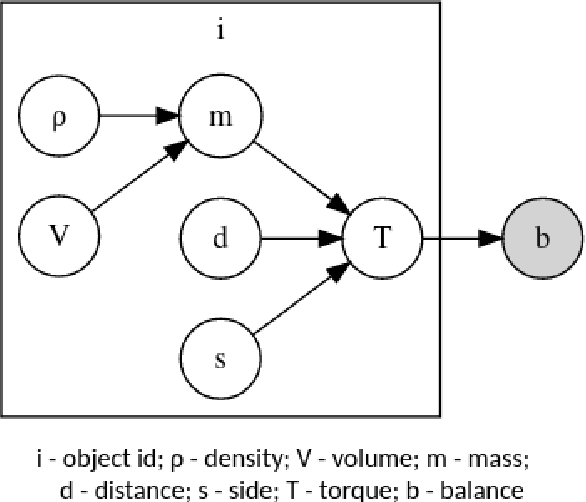
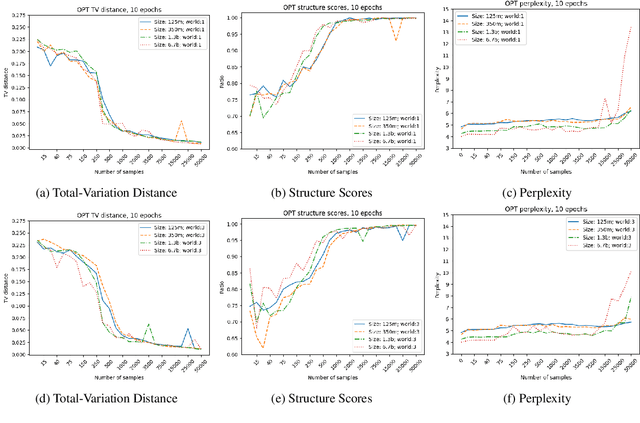
Learning a model of a stochastic setting often involves learning both general structure rules and specific properties of the instance. This paper investigates the interplay between learning the general and the specific in various learning methods, with emphasis on sample efficiency. We design a framework called {\sc LeverWorlds}, which allows the generation of simple physics-inspired worlds that follow a similar generative process with different distributions, and their instances can be expressed in natural language. These worlds allow for controlled experiments to assess the sample complexity of different learning methods. We experiment with classic learning algorithms as well as Transformer language models, both with fine-tuning and In-Context Learning (ICL). Our general finding is that (1) Transformers generally succeed in the task; but (2) they are considerably less sample efficient than classic methods that make stronger assumptions about the structure, such as Maximum Likelihood Estimation and Logistic Regression. This finding is in tension with the recent tendency to use Transformers as general-purpose estimators. We propose an approach that leverages the ICL capabilities of contemporary language models to apply simple algorithms for this type of data. Our experiments show that models currently struggle with the task but show promising potential.
CoverBench: A Challenging Benchmark for Complex Claim Verification
Aug 06, 2024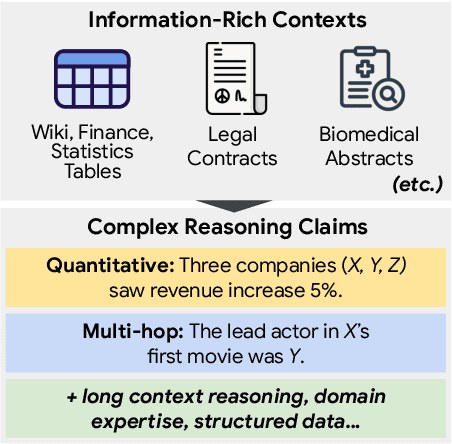
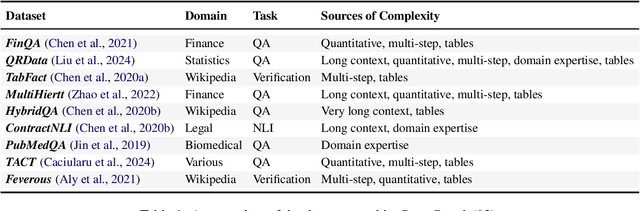
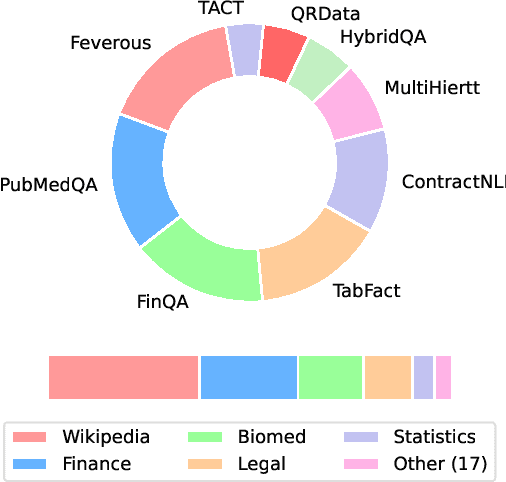
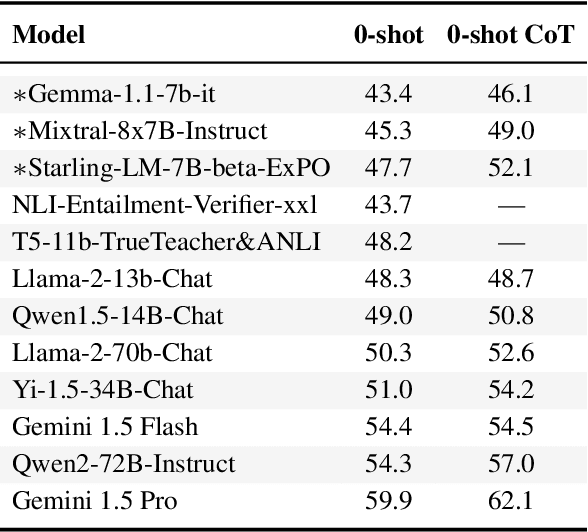
There is a growing line of research on verifying the correctness of language models' outputs. At the same time, LMs are being used to tackle complex queries that require reasoning. We introduce CoverBench, a challenging benchmark focused on verifying LM outputs in complex reasoning settings. Datasets that can be used for this purpose are often designed for other complex reasoning tasks (e.g., QA) targeting specific use-cases (e.g., financial tables), requiring transformations, negative sampling and selection of hard examples to collect such a benchmark. CoverBench provides a diversified evaluation for complex claim verification in a variety of domains, types of reasoning, relatively long inputs, and a variety of standardizations, such as multiple representations for tables where available, and a consistent schema. We manually vet the data for quality to ensure low levels of label noise. Finally, we report a variety of competitive baseline results to show CoverBench is challenging and has very significant headroom. The data is available at https://huggingface.co/datasets/google/coverbench .
Distributional reasoning in LLMs: Parallel reasoning processes in multi-hop reasoning
Jun 19, 2024



Large language models (LLMs) have shown an impressive ability to perform tasks believed to require thought processes. When the model does not document an explicit thought process, it becomes difficult to understand the processes occurring within its hidden layers and to determine if these processes can be referred to as reasoning. We introduce a novel and interpretable analysis of internal multi-hop reasoning processes in LLMs. We demonstrate that the prediction process for compositional reasoning questions can be modeled using a simple linear transformation between two semantic category spaces. We show that during inference, the middle layers of the network generate highly interpretable embeddings that represent a set of potential intermediate answers for the multi-hop question. We use statistical analyses to show that a corresponding subset of tokens is activated in the model's output, implying the existence of parallel reasoning paths. These observations hold true even when the model lacks the necessary knowledge to solve the task. Our findings can help uncover the strategies that LLMs use to solve reasoning tasks, offering insights into the types of thought processes that can emerge from artificial intelligence. Finally, we also discuss the implication of cognitive modeling of these results.
Can LLMs Learn Macroeconomic Narratives from Social Media?
Jun 17, 2024


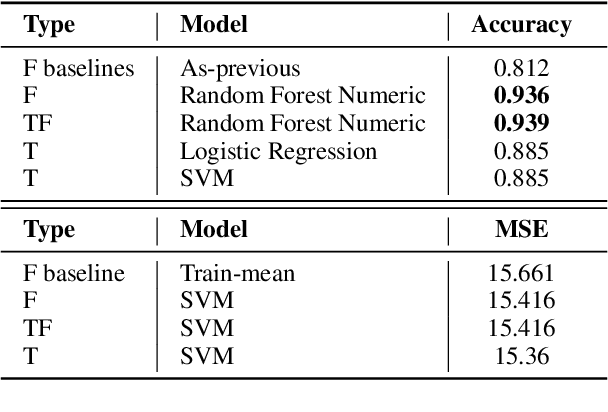
This study empirically tests the $\textit{Narrative Economics}$ hypothesis, which posits that narratives (ideas that are spread virally and affect public beliefs) can influence economic fluctuations. We introduce two curated datasets containing posts from X (formerly Twitter) which capture economy-related narratives (Data will be shared upon paper acceptance). Employing Natural Language Processing (NLP) methods, we extract and summarize narratives from the tweets. We test their predictive power for $\textit{macroeconomic}$ forecasting by incorporating the tweets' or the extracted narratives' representations in downstream financial prediction tasks. Our work highlights the challenges in improving macroeconomic models with narrative data, paving the way for the research community to realistically address this important challenge. From a scientific perspective, our investigation offers valuable insights and NLP tools for narrative extraction and summarization using Large Language Models (LLMs), contributing to future research on the role of narratives in economics.
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?
May 09, 2024

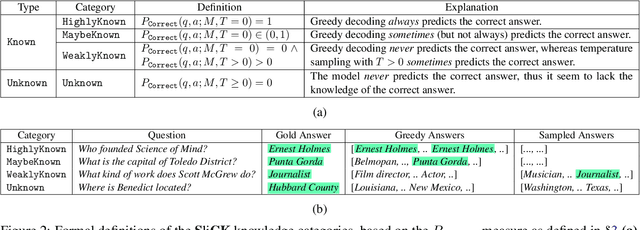
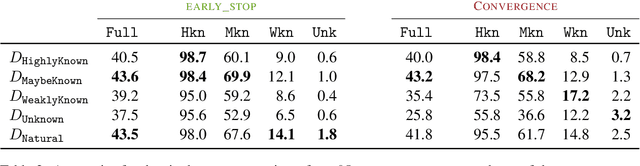
When large language models are aligned via supervised fine-tuning, they may encounter new factual information that was not acquired through pre-training. It is often conjectured that this can teach the model the behavior of hallucinating factually incorrect responses, as the model is trained to generate facts that are not grounded in its pre-existing knowledge. In this work, we study the impact of such exposure to new knowledge on the capability of the fine-tuned model to utilize its pre-existing knowledge. To this end, we design a controlled setup, focused on closed-book QA, where we vary the proportion of the fine-tuning examples that introduce new knowledge. We demonstrate that large language models struggle to acquire new factual knowledge through fine-tuning, as fine-tuning examples that introduce new knowledge are learned significantly slower than those consistent with the model's knowledge. However, we also find that as the examples with new knowledge are eventually learned, they linearly increase the model's tendency to hallucinate. Taken together, our results highlight the risk in introducing new factual knowledge through fine-tuning, and support the view that large language models mostly acquire factual knowledge through pre-training, whereas fine-tuning teaches them to use it more efficiently.
LLMs Accelerate Annotation for Medical Information Extraction
Dec 04, 2023



The unstructured nature of clinical notes within electronic health records often conceals vital patient-related information, making it challenging to access or interpret. To uncover this hidden information, specialized Natural Language Processing (NLP) models are required. However, training these models necessitates large amounts of labeled data, a process that is both time-consuming and costly when relying solely on human experts for annotation. In this paper, we propose an approach that combines Large Language Models (LLMs) with human expertise to create an efficient method for generating ground truth labels for medical text annotation. By utilizing LLMs in conjunction with human annotators, we significantly reduce the human annotation burden, enabling the rapid creation of labeled datasets. We rigorously evaluate our method on a medical information extraction task, demonstrating that our approach not only substantially cuts down on human intervention but also maintains high accuracy. The results highlight the potential of using LLMs to improve the utilization of unstructured clinical data, allowing for the swift deployment of tailored NLP solutions in healthcare.
Causal-structure Driven Augmentations for Text OOD Generalization
Oct 19, 2023



The reliance of text classifiers on spurious correlations can lead to poor generalization at deployment, raising concerns about their use in safety-critical domains such as healthcare. In this work, we propose to use counterfactual data augmentation, guided by knowledge of the causal structure of the data, to simulate interventions on spurious features and to learn more robust text classifiers. We show that this strategy is appropriate in prediction problems where the label is spuriously correlated with an attribute. Under the assumptions of such problems, we discuss the favorable sample complexity of counterfactual data augmentation, compared to importance re-weighting. Pragmatically, we match examples using auxiliary data, based on diff-in-diff methodology, and use a large language model (LLM) to represent a conditional probability of text. Through extensive experimentation on learning caregiver-invariant predictors of clinical diagnoses from medical narratives and on semi-synthetic data, we demonstrate that our method for simulating interventions improves out-of-distribution (OOD) accuracy compared to baseline invariant learning algorithms.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.