 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Language Model Probabilities Represent? From Distribution Estimation to Response Prediction
May 04, 2025
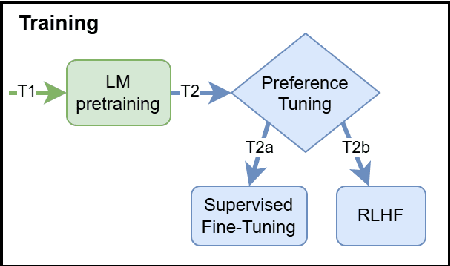
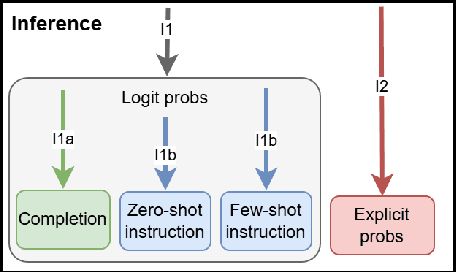
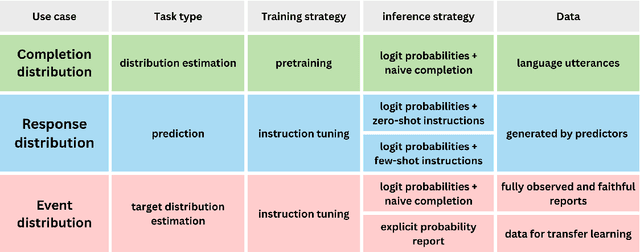
The notion of language modeling has gradually shifted in recent years from a distribution over finite-length strings to general-purpose prediction models for textual inputs and outputs, following appropriate alignment phases. This paper analyzes the distinction between distribution estimation and response prediction in the context of LLMs, and their often conflicting goals. We examine the training phases of LLMs, which include pretraining, in-context learning, and preference tuning, and also the common use cases for their output probabilities, which include completion probabilities and explicit probabilities as output. We argue that the different settings lead to three distinct intended output distributions. We demonstrate that NLP works often assume that these distributions should be similar, which leads to misinterpretations of their experimental findings. Our work sets firmer formal foundations for the interpretation of LLMs, which will inform ongoing work on the interpretation and use of LLMs' induced distributions.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Unsupervised Location Mapping for Narrative Corpora
Apr 08, 2025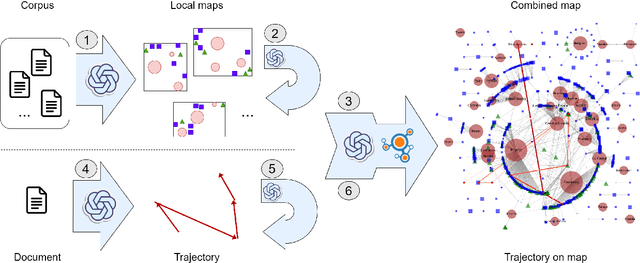
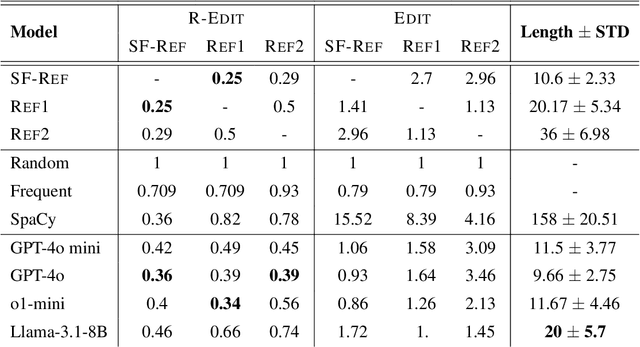
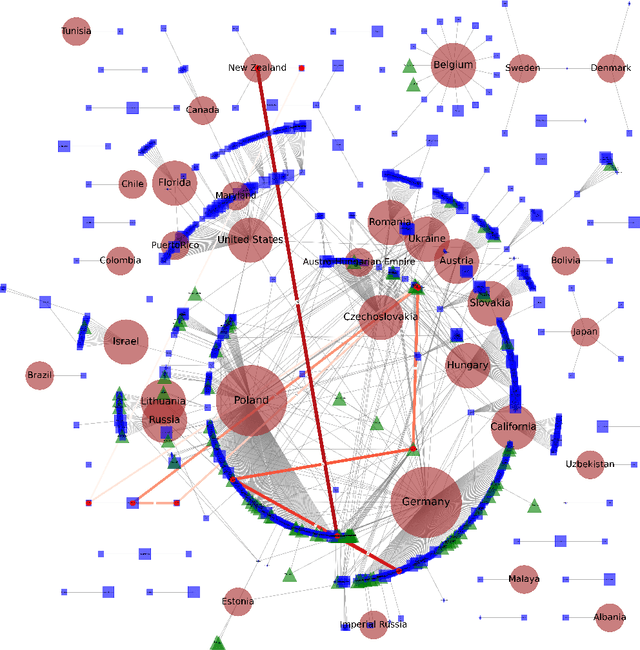
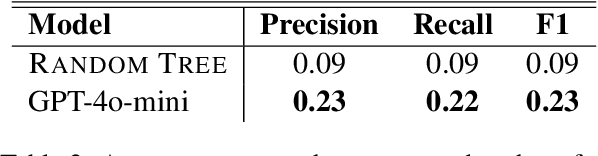
This work presents the task of unsupervised location mapping, which seeks to map the trajectory of an individual narrative on a spatial map of locations in which a large set of narratives take place. Despite the fundamentality and generality of the task, very little work addressed the spatial mapping of narrative texts. The task consists of two parts: (1) inducing a ``map'' with the locations mentioned in a set of texts, and (2) extracting a trajectory from a single narrative and positioning it on the map. Following recent advances in increasing the context length of large language models, we propose a pipeline for this task in a completely unsupervised manner without predefining the set of labels. We test our method on two different domains: (1) Holocaust testimonies and (2) Lake District writing, namely multi-century literature on travels in the English Lake District. We perform both intrinsic and extrinsic evaluations for the task, with encouraging results, thereby setting a benchmark and evaluation practices for the task, as well as highlighting challenges.
Computational Analysis of Character Development in Holocaust Testimonies
Dec 22, 2024This work presents a computational approach to analyze character development along the narrative timeline. The analysis characterizes the inner and outer changes the protagonist undergoes within a narrative, and the interplay between them. We consider transcripts of Holocaust survivor testimonies as a test case, each telling the story of an individual in first-person terms. We focus on the survivor's religious trajectory, examining the evolution of their disposition toward religious belief and practice along the testimony. Clustering the resulting trajectories in the dataset, we identify common sequences in the data. Our findings highlight multiple common structures of religiosity across the narratives: in terms of belief, most present a constant disposition, while for practice, most present an oscillating structure, serving as valuable material for historical and sociological research. This work demonstrates the potential of natural language processing techniques for analyzing character evolution through thematic trajectories in narratives.
Mind Your Theory: Theory of Mind Goes Deeper Than Reasoning
Dec 18, 2024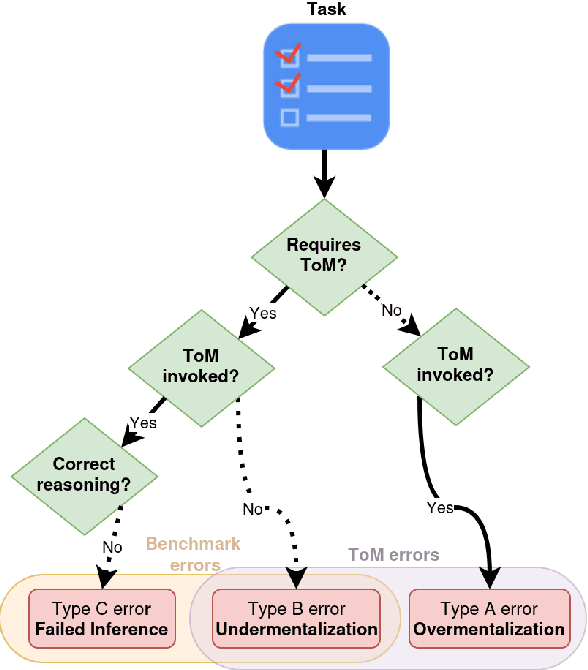
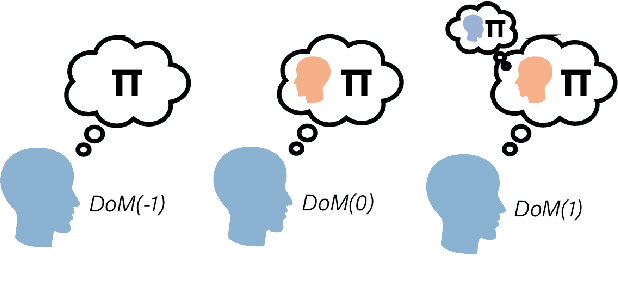
Theory of Mind (ToM) capabilities in LLMs have recently become a central object of investigation. Cognitive science distinguishes between two steps required for ToM tasks: 1) determine whether to invoke ToM, which includes the appropriate Depth of Mentalizing (DoM), or level of recursion required to complete a task; and 2) applying the correct inference given the DoM. In this position paper, we first identify several lines of work in different communities in AI, including LLM benchmarking, ToM add-ons, ToM probing, and formal models for ToM. We argue that recent work in AI tends to focus exclusively on the second step which are typically framed as static logic problems. We conclude with suggestions for improved evaluation of ToM capabilities inspired by dynamic environments used in cognitive tasks.
Exploring the Learning Capabilities of Language Models using LEVERWORLDS
Oct 01, 2024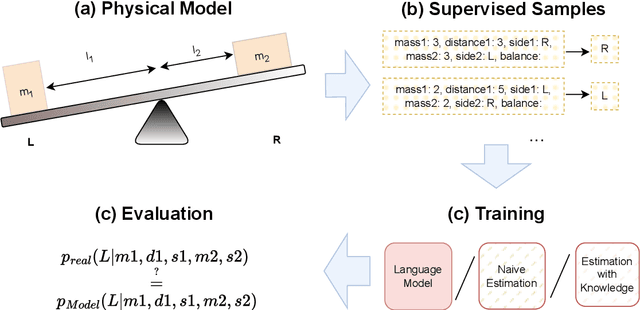
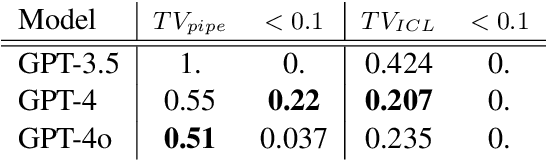
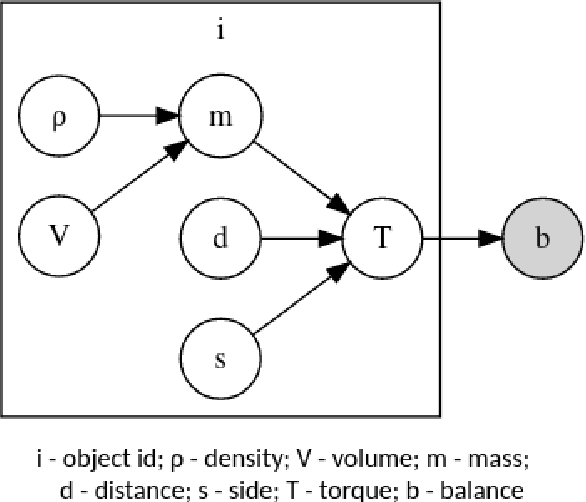
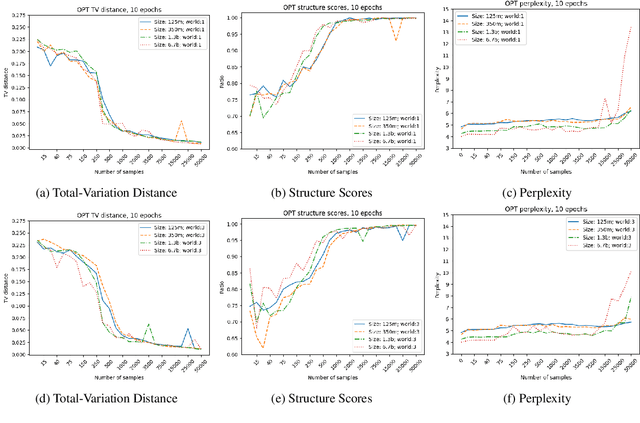
Learning a model of a stochastic setting often involves learning both general structure rules and specific properties of the instance. This paper investigates the interplay between learning the general and the specific in various learning methods, with emphasis on sample efficiency. We design a framework called {\sc LeverWorlds}, which allows the generation of simple physics-inspired worlds that follow a similar generative process with different distributions, and their instances can be expressed in natural language. These worlds allow for controlled experiments to assess the sample complexity of different learning methods. We experiment with classic learning algorithms as well as Transformer language models, both with fine-tuning and In-Context Learning (ICL). Our general finding is that (1) Transformers generally succeed in the task; but (2) they are considerably less sample efficient than classic methods that make stronger assumptions about the structure, such as Maximum Likelihood Estimation and Logistic Regression. This finding is in tension with the recent tendency to use Transformers as general-purpose estimators. We propose an approach that leverages the ICL capabilities of contemporary language models to apply simple algorithms for this type of data. Our experiments show that models currently struggle with the task but show promising potential.
CONTESTS: a Framework for Consistency Testing of Span Probabilities in Language Models
Sep 30, 2024



Although language model scores are often treated as probabilities, their reliability as probability estimators has mainly been studied through calibration, overlooking other aspects. In particular, it is unclear whether language models produce the same value for different ways of assigning joint probabilities to word spans. Our work introduces a novel framework, ConTestS (Consistency Testing over Spans), involving statistical tests to assess score consistency across interchangeable completion and conditioning orders. We conduct experiments on post-release real and synthetic data to eliminate training effects. Our findings reveal that both Masked Language Models (MLMs) and autoregressive models exhibit inconsistent predictions, with autoregressive models showing larger discrepancies. Larger MLMs tend to produce more consistent predictions, while autoregressive models show the opposite trend. Moreover, for both model types, prediction entropies offer insights into the true word span likelihood and therefore can aid in selecting optimal decoding strategies. The inconsistencies revealed by our analysis, as well their connection to prediction entropies and differences between model types, can serve as useful guides for future research on addressing these limitations.
Topical Segmentation of Spoken Narratives: A Test Case on Holocaust Survivor Testimonies
Oct 25, 2022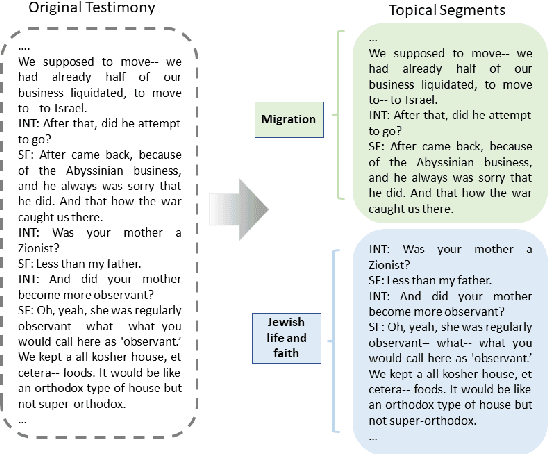
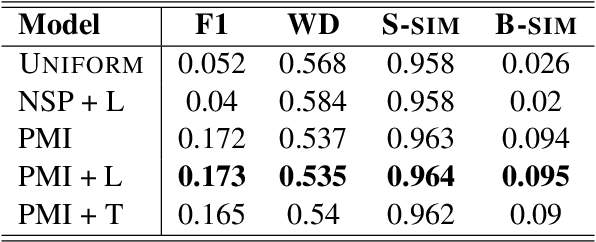
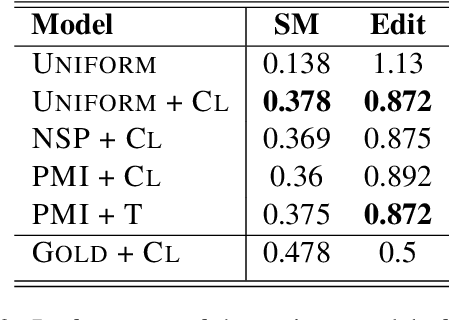
The task of topical segmentation is well studied, but previous work has mostly addressed it in the context of structured, well-defined segments, such as segmentation into paragraphs, chapters, or segmenting text that originated from multiple sources. We tackle the task of segmenting running (spoken) narratives, which poses hitherto unaddressed challenges. As a test case, we address Holocaust survivor testimonies, given in English. Other than the importance of studying these testimonies for Holocaust research, we argue that they provide an interesting test case for topical segmentation, due to their unstructured surface level, relative abundance (tens of thousands of such testimonies were collected), and the relatively confined domain that they cover. We hypothesize that boundary points between segments correspond to low mutual information between the sentences proceeding and following the boundary. Based on this hypothesis, we explore a range of algorithmic approaches to the task, building on previous work on segmentation that uses generative Bayesian modeling and state-of-the-art neural machinery. Compared to manually annotated references, we find that the developed approaches show considerable improvements over previous work.