 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Robust Representation Learning with Empirical Bayes
Jun 03, 2026We consider multi-environment prediction problems. We assume the environments change the distribution of a latent variable, while the mechanisms generating observed covariates and targets remain stable conditional on that variable. For example, hospitals or clinical cohorts may differ in the prevalence of latent patient states, even though the relationships between those states, physiological measurements, and outcomes remain unchanged. Given a dataset from multiple environments, we formulate a Bayesian model for such problems and derive the corresponding variational objective. We show that this objective decomposes into per-environment terms and an additional cross-environment balancing term induced by the model's structure. We use an empirical Bayes method to set the prior and incorporate it into the objective. Based on this objective, we develop an amortized variational algorithm for posterior approximation, and use the resulting learned latent variables to form predictions in new environments.We study our approach through simulations and real-world studies of astronomical source identification, microbiome-based disease detection, and ICU sepsis prediction. Across these settings, our method outperforms previous approaches for prediction in new environments.
Neural Generalized Mixed-Effects Models
Apr 13, 2026Generalized linear mixed-effects models (GLMMs) are widely used to analyze grouped and hierarchical data. In a GLMM, each response is assumed to follow an exponential-family distribution where the natural parameter is given by a linear function of observed covariates and a latent group-specific random effect. Since exact marginalization over the random effects is typically intractable, model parameters are estimated by maximizing an approximate marginal likelihood. In this paper, we replace the linear function with neural networks. The result is a more flexible model, the neural generalized mixed-effects model (NGMM), which captures complex relationships between covariates and responses. To fit NGMM to data, we introduce an efficient optimization procedure that maximizes the approximate marginal likelihood and is differentiable with respect to network parameters. We show that the approximation error of our objective decays at a Gaussian-tail rate in a user-chosen parameter. On synthetic data, NGMM improves over GLMMs when covariate-response relationships are nonlinear, and on real-world datasets it outperforms prior methods. Finally, we analyze a large dataset of student proficiency to demonstrate how NGMM can be extended to more complex latent-variable models.
CONTESTS: a Framework for Consistency Testing of Span Probabilities in Language Models
Sep 30, 2024



Although language model scores are often treated as probabilities, their reliability as probability estimators has mainly been studied through calibration, overlooking other aspects. In particular, it is unclear whether language models produce the same value for different ways of assigning joint probabilities to word spans. Our work introduces a novel framework, ConTestS (Consistency Testing over Spans), involving statistical tests to assess score consistency across interchangeable completion and conditioning orders. We conduct experiments on post-release real and synthetic data to eliminate training effects. Our findings reveal that both Masked Language Models (MLMs) and autoregressive models exhibit inconsistent predictions, with autoregressive models showing larger discrepancies. Larger MLMs tend to produce more consistent predictions, while autoregressive models show the opposite trend. Moreover, for both model types, prediction entropies offer insights into the true word span likelihood and therefore can aid in selecting optimal decoding strategies. The inconsistencies revealed by our analysis, as well their connection to prediction entropies and differences between model types, can serve as useful guides for future research on addressing these limitations.
Class Distribution Shifts in Zero-Shot Learning: Learning Robust Representations
Nov 30, 2023Distribution shifts between training and deployment data often affect the performance of machine learning models. In this paper, we explore a setting where a hidden variable induces a shift in the distribution of classes. These distribution shifts are particularly challenging for zero-shot classifiers, as they rely on representations learned from training classes, but are deployed on new, unseen ones. We introduce an algorithm to learn data representations that are robust to such class distribution shifts in zero-shot verification tasks. We show that our approach, which combines hierarchical data sampling with out-of-distribution generalization techniques, improves generalization to diverse class distributions in both simulations and real-world datasets.
Predicting Classification Accuracy when Adding New Unobserved Classes
Oct 28, 2020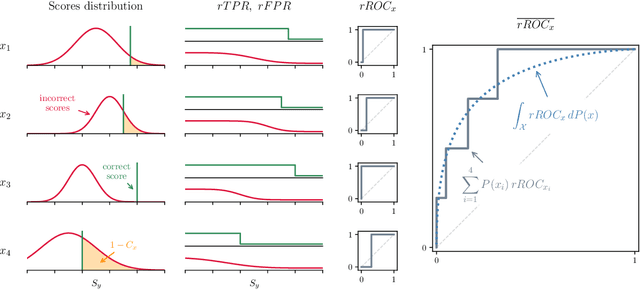
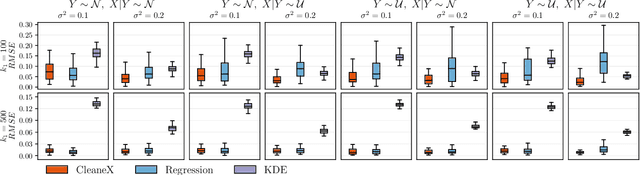
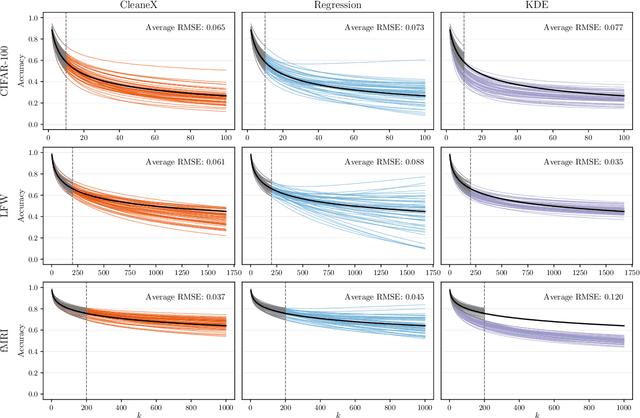
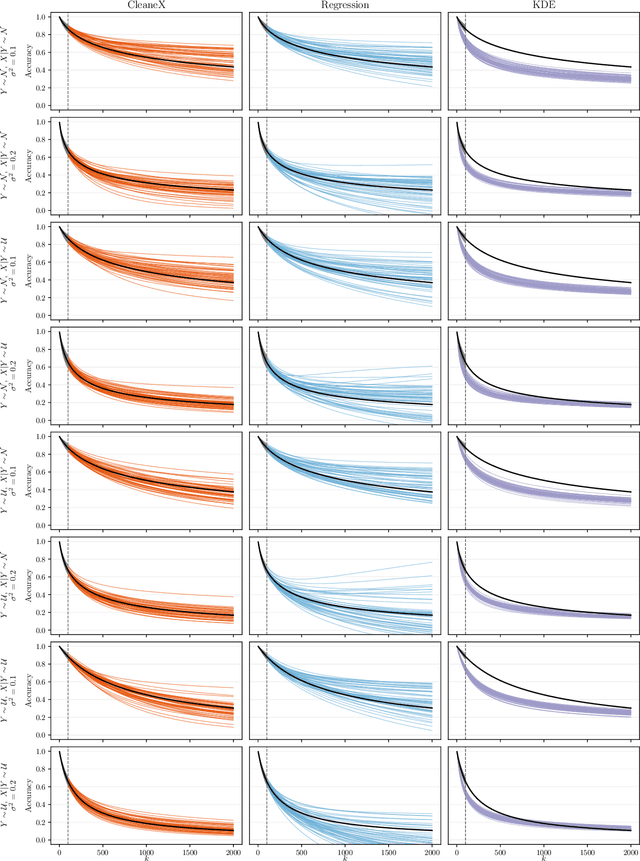
Multiclass classifiers are often designed and evaluated only on a sample from the classes on which they will eventually be applied. Hence, their final accuracy remains unknown. In this work we study how a classifier's performance over the initial class sample can be used to extrapolate its expected accuracy on a larger, unobserved set of classes. For this, we define a measure of separation between correct and incorrect classes that is independent of the number of classes: the reversed ROC (rROC), which is obtained by replacing the roles of classes and data-points in the common ROC. We show that the classification accuracy is a function of the rROC in multiclass classifiers, for which the learned representation of data from the initial class sample remains unchanged when new classes are added. Using these results we formulate a robust neural-network-based algorithm, CleaneX, which learns to estimate the accuracy of such classifiers on arbitrarily large sets of classes. Our method achieves remarkably better predictions than current state-of-the-art methods on both simulations and real datasets of object detection, face recognition, and brain decoding.