 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMediocrity is the key for LLM as a Judge Anchor Selection
Mar 17, 2026The ``LLM-as-a-judge'' paradigm has become a standard method for evaluating open-ended generation. To address the quadratic scalability costs of pairwise comparisons, popular benchmarks like Arena-Hard and AlpacaEval compare all models against a single anchor. However, despite its widespread use, the impact of anchor selection on the reliability of the results remains largely unexplored. In this work, we systematically investigate the effect of anchor selection by evaluating 22 different anchors on the Arena-Hard-v2.0 dataset. We find that the choice of anchor is critical: a poor anchor can dramatically reduce correlation with human rankings. We identify that common anchor choices (best-performing and worst-performing models) make poor anchors. Because these extreme anchors are consistently better or worse than all other models, they are seldom indicative of the relative ranking of the models. We further quantify the effect size of anchor selection, showing it is comparable to the selection of a judge model. We conclude with actionable recommendations. First, we conduct a power analysis, and compute sufficient benchmark sizes for anchor-based evaluation, finding that standard benchmark sizes are insufficient for pairwise evaluation and fail to distinguish between competitive models reliably. Second, we provide guidelines for selecting informative anchors to ensure reliable and efficient evaluation practices.
Discrete Diffusion Models Exploit Asymmetry to Solve Lookahead Planning Tasks
Feb 23, 2026While Autoregressive (AR) Transformer-based Generative Language Models are frequently employed for lookahead tasks, recent research suggests a potential discrepancy in their ability to perform planning tasks that require multi-step lookahead. In this work, we investigate the distinct emergent mechanisms that arise when training AR versus Non-Autoregressive (NAR) models, such as Discrete Diffusion Models (dLLMs), on lookahead tasks. By requiring the models to plan ahead to reach the correct conclusion, we analyze how these two paradigms fundamentally differ in their approach to the problem. We identify a critical asymmetry in planning problems: while forward generation requires complex lookahead at branching junctions, reverse generation is often deterministic. This asymmetry creates an opportunity for NAR models. Through mechanistic analysis of training and inference dynamics, we demonstrate that NAR models learn to solve planning tasks by utilizing future tokens to decode backwards, avoiding the need to learn complex traversal mechanisms entirely. Consequently, we report that both AR and NAR models are able to achieve perfect accuracy on the lookahead task. However, NAR models require exponentially fewer training examples and shallower architectures compared to AR models, which often fail to converge without specific curriculum adjustments.
QA-Noun: Representing Nominal Semantics via Natural Language Question-Answer Pairs
Nov 16, 2025
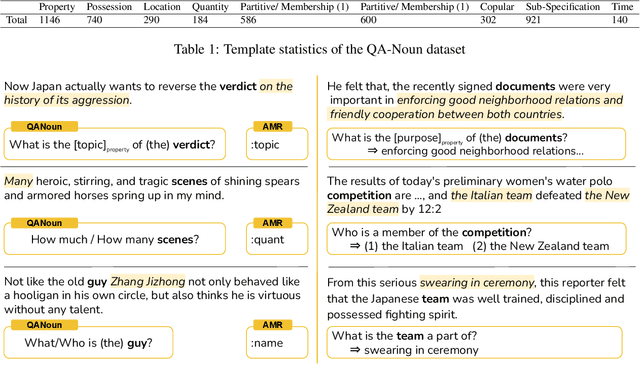
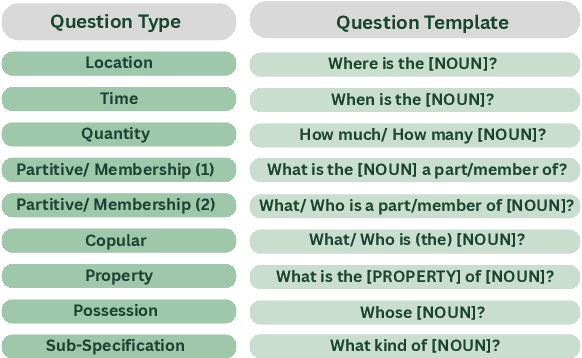
Decomposing sentences into fine-grained meaning units is increasingly used to model semantic alignment. While QA-based semantic approaches have shown effectiveness for representing predicate-argument relations, they have so far left noun-centered semantics largely unaddressed. We introduce QA-Noun, a QA-based framework for capturing noun-centered semantic relations. QA-Noun defines nine question templates that cover both explicit syntactical and implicit contextual roles for nouns, producing interpretable QA pairs that complement verbal QA-SRL. We release detailed guidelines, a dataset of over 2,000 annotated noun mentions, and a trained model integrated with QA-SRL to yield a unified decomposition of sentence meaning into individual, highly fine-grained, facts. Evaluation shows that QA-Noun achieves near-complete coverage of AMR's noun arguments while surfacing additional contextually implied relations, and that combining QA-Noun with QA-SRL yields over 130\% higher granularity than recent fact-based decomposition methods such as FactScore and DecompScore. QA-Noun thus complements the broader QA-based semantic framework, forming a comprehensive and scalable approach to fine-grained semantic decomposition for cross-text alignment.
What do Language Model Probabilities Represent? From Distribution Estimation to Response Prediction
May 04, 2025
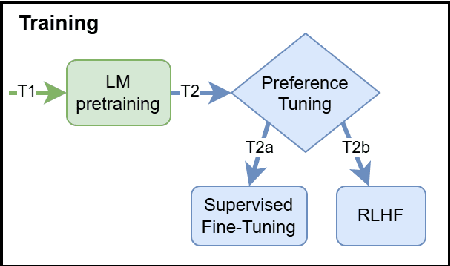
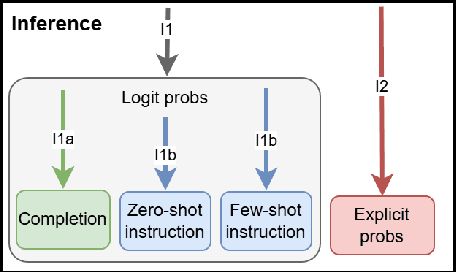
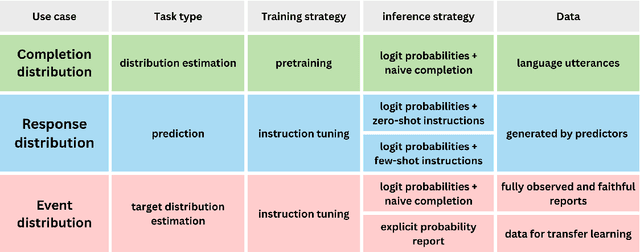
The notion of language modeling has gradually shifted in recent years from a distribution over finite-length strings to general-purpose prediction models for textual inputs and outputs, following appropriate alignment phases. This paper analyzes the distinction between distribution estimation and response prediction in the context of LLMs, and their often conflicting goals. We examine the training phases of LLMs, which include pretraining, in-context learning, and preference tuning, and also the common use cases for their output probabilities, which include completion probabilities and explicit probabilities as output. We argue that the different settings lead to three distinct intended output distributions. We demonstrate that NLP works often assume that these distributions should be similar, which leads to misinterpretations of their experimental findings. Our work sets firmer formal foundations for the interpretation of LLMs, which will inform ongoing work on the interpretation and use of LLMs' induced distributions.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Unsupervised Location Mapping for Narrative Corpora
Apr 08, 2025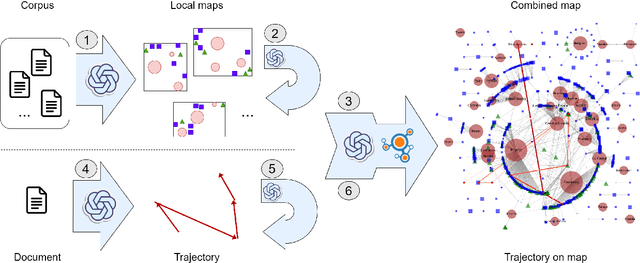
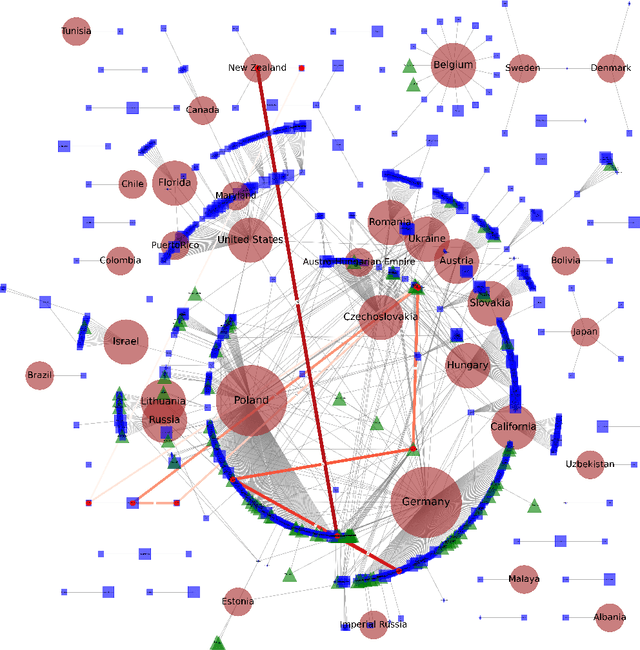
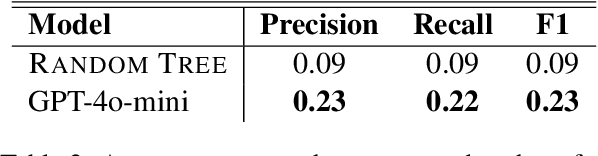
This work presents the task of unsupervised location mapping, which seeks to map the trajectory of an individual narrative on a spatial map of locations in which a large set of narratives take place. Despite the fundamentality and generality of the task, very little work addressed the spatial mapping of narrative texts. The task consists of two parts: (1) inducing a ``map'' with the locations mentioned in a set of texts, and (2) extracting a trajectory from a single narrative and positioning it on the map. Following recent advances in increasing the context length of large language models, we propose a pipeline for this task in a completely unsupervised manner without predefining the set of labels. We test our method on two different domains: (1) Holocaust testimonies and (2) Lake District writing, namely multi-century literature on travels in the English Lake District. We perform both intrinsic and extrinsic evaluations for the task, with encouraging results, thereby setting a benchmark and evaluation practices for the task, as well as highlighting challenges.
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models
Feb 21, 2025Large language models (LLMs) are increasingly deployed with hierarchical instruction schemes, where certain instructions (e.g., system-level directives) are expected to take precedence over others (e.g., user messages). Yet, we lack a systematic understanding of how effectively these hierarchical control mechanisms work. We introduce a systematic evaluation framework based on constraint prioritization to assess how well LLMs enforce instruction hierarchies. Our experiments across six state-of-the-art LLMs reveal that models struggle with consistent instruction prioritization, even for simple formatting conflicts. We find that the widely-adopted system/user prompt separation fails to establish a reliable instruction hierarchy, and models exhibit strong inherent biases toward certain constraint types regardless of their priority designation. While controlled prompt engineering and model fine-tuning show modest improvements, our results indicate that instruction hierarchy enforcement is not robustly realized, calling for deeper architectural innovations beyond surface-level modifications.
Improving Image Captioning by Mimicking Human Reformulation Feedback at Inference-time
Jan 08, 2025



Incorporating automatically predicted human feedback into the process of training generative models has attracted substantial recent interest, while feedback at inference time has received less attention. The typical feedback at training time, i.e., preferences of choice given two samples, does not naturally transfer to the inference phase. We introduce a novel type of feedback -- caption reformulations -- and train models to mimic reformulation feedback based on human annotations. Our method does not require training the image captioning model itself, thereby demanding substantially less computational effort. We experiment with two types of reformulation feedback: first, we collect a dataset of human reformulations that correct errors in the generated captions. We find that incorporating reformulation models trained on this data into the inference phase of existing image captioning models results in improved captions, especially when the original captions are of low quality. We apply our method to non-English image captioning, a domain where robust models are less prevalent, and gain substantial improvement. Second, we apply reformulations to style transfer. Quantitative evaluations reveal state-of-the-art performance on German image captioning and English style transfer, while human validation with a detailed comparative framework exposes the specific axes of improvement.
Unsupervised Speech Segmentation: A General Approach Using Speech Language Models
Jan 07, 2025



In this paper, we introduce an unsupervised approach for Speech Segmentation, which builds on previously researched approaches, e.g., Speaker Diarization, while being applicable to an inclusive set of acoustic-semantic distinctions, paving a path towards a general Unsupervised Speech Segmentation approach. Unlike traditional speech and audio segmentation, which mainly focuses on spectral changes in the input signal, e.g., phone segmentation, our approach tries to segment the spoken utterance into chunks with differing acoustic-semantic styles, focusing on acoustic-semantic information that does not translate well into text, e.g., emotion or speaker. While most Speech Segmentation tasks only handle one style change, e.g., emotion diarization, our approach tries to handle multiple acoustic-semantic style changes. Leveraging recent advances in Speech Language Models (SLMs), we propose a simple unsupervised method to segment a given speech utterance. We empirically demonstrate the effectiveness of the proposed approach by considering several setups. Results suggest that the proposed method is superior to the evaluated baselines on boundary detection, segment purity, and over-segmentation. Code is available at https://github.com/avishaiElmakies/unsupervised_speech_segmentation_using_slm.
Computational Analysis of Character Development in Holocaust Testimonies
Dec 22, 2024This work presents a computational approach to analyze character development along the narrative timeline. The analysis characterizes the inner and outer changes the protagonist undergoes within a narrative, and the interplay between them. We consider transcripts of Holocaust survivor testimonies as a test case, each telling the story of an individual in first-person terms. We focus on the survivor's religious trajectory, examining the evolution of their disposition toward religious belief and practice along the testimony. Clustering the resulting trajectories in the dataset, we identify common sequences in the data. Our findings highlight multiple common structures of religiosity across the narratives: in terms of belief, most present a constant disposition, while for practice, most present an oscillating structure, serving as valuable material for historical and sociological research. This work demonstrates the potential of natural language processing techniques for analyzing character evolution through thematic trajectories in narratives.