 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Testimony: A Scalable Framework for Oral History Archive Comparison
May 20, 2026Researchers in Holocaust studies have often distinguished between two styles of oral survivor testimony: the USC Shoah Foundation's interviews tend to follow a structured, interviewer-guided format, whereas the Yale Fortunoff Video Archive generally favors a more free-form, open-ended style. This distinction has influenced both scholarly research and the development of later archives. In this study, we critically examine that claim by conducting a large-scale computational analysis of more than 1,600 testimonies from both collections. Leveraging discourse segmentation, topic modeling, and large language model (LLM) based analysis, we quantify the "structuredness" level of testimonies through topic coherence, interviewer-survivor dynamics, and the distribution of question types. Our results generally corroborate the structural differences identified in earlier research, while also revealing significant overlaps between the collections, both within individual interviews and across common narrative patterns. This complicates the simple "structured vs. free-form" dichotomy often applied to these oral histories. Beyond revisiting a foundational claim in Holocaust studies, our work provides a scalable, replicable framework for comparative corpus analysis. As a proof of concept, it suggests broader applications for digital oral history, narrative analysis, and the design of citizen-science annotation platforms.
ScheMatiQ: From Research Question to Structured Data through Interactive Schema Discovery
Apr 10, 2026Many disciplines pose natural-language research questions over large document collections whose answers typically require structured evidence, traditionally obtained by manually designing an annotation schema and exhaustively labeling the corpus, a slow and error-prone process. We introduce ScheMatiQ, which leverages calls to a backbone LLM to take a question and a corpus to produce a schema and a grounded database, with a web interface that lets steer and revise the extraction. In collaboration with domain experts, we show that ScheMatiQ yields outputs that support real-world analysis in law and computational biology. We release ScheMatiQ as open source with a public web interface, and invite experts across disciplines to use it with their own data. All resources, including the website, source code, and demonstration video, are available at: www.ScheMatiQ-ai.com
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Unsupervised Location Mapping for Narrative Corpora
Apr 08, 2025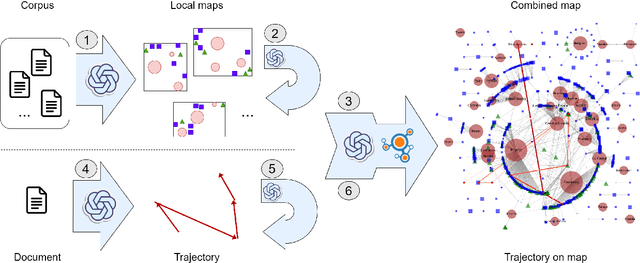
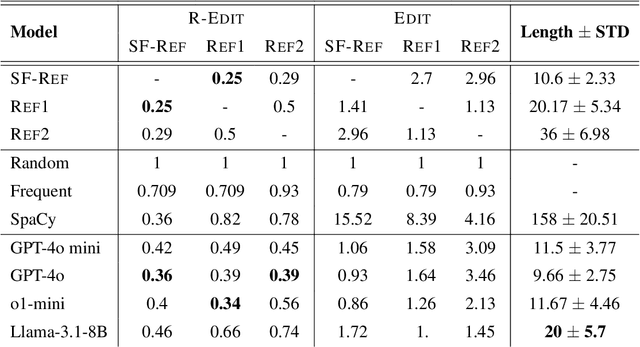
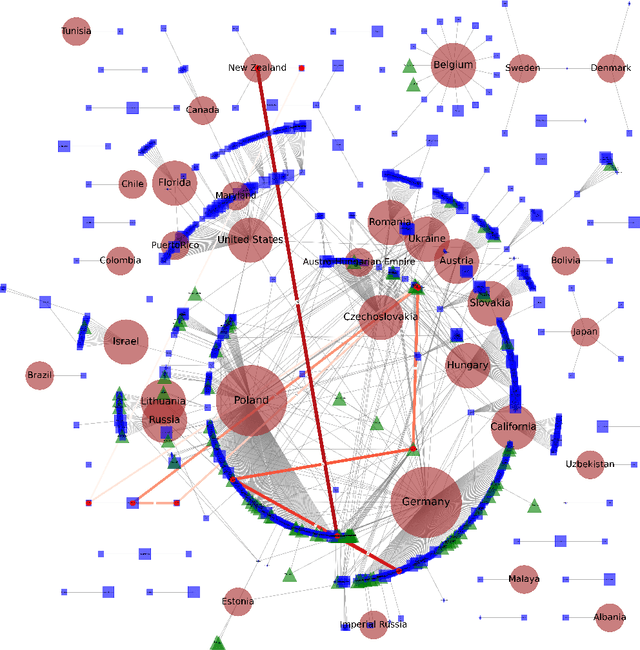
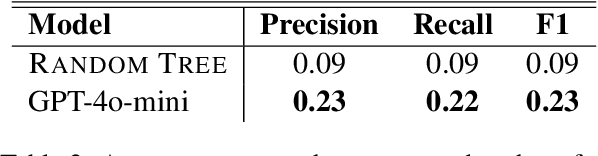
This work presents the task of unsupervised location mapping, which seeks to map the trajectory of an individual narrative on a spatial map of locations in which a large set of narratives take place. Despite the fundamentality and generality of the task, very little work addressed the spatial mapping of narrative texts. The task consists of two parts: (1) inducing a ``map'' with the locations mentioned in a set of texts, and (2) extracting a trajectory from a single narrative and positioning it on the map. Following recent advances in increasing the context length of large language models, we propose a pipeline for this task in a completely unsupervised manner without predefining the set of labels. We test our method on two different domains: (1) Holocaust testimonies and (2) Lake District writing, namely multi-century literature on travels in the English Lake District. We perform both intrinsic and extrinsic evaluations for the task, with encouraging results, thereby setting a benchmark and evaluation practices for the task, as well as highlighting challenges.
Beyond Benchmarks: On The False Promise of AI Regulation
Jan 26, 2025

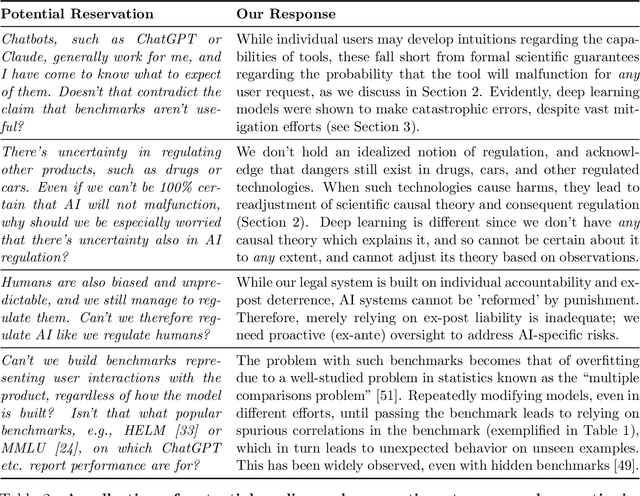

The rapid advancement of artificial intelligence (AI) systems in critical domains like healthcare, justice, and social services has sparked numerous regulatory initiatives aimed at ensuring their safe deployment. Current regulatory frameworks, exemplified by recent US and EU efforts, primarily focus on procedural guidelines while presuming that scientific benchmarking can effectively validate AI safety, similar to how crash tests verify vehicle safety or clinical trials validate drug efficacy. However, this approach fundamentally misunderstands the unique technical challenges posed by modern AI systems. Through systematic analysis of successful technology regulation case studies, we demonstrate that effective scientific regulation requires a causal theory linking observable test outcomes to future performance - for instance, how a vehicle's crash resistance at one speed predicts its safety at lower speeds. We show that deep learning models, which learn complex statistical patterns from training data without explicit causal mechanisms, preclude such guarantees. This limitation renders traditional regulatory approaches inadequate for ensuring AI safety. Moving forward, we call for regulators to reckon with this limitation, and propose a preliminary two-tiered regulatory framework that acknowledges these constraints: mandating human oversight for high-risk applications while developing appropriate risk communication strategies for lower-risk uses. Our findings highlight the urgent need to reconsider fundamental assumptions in AI regulation and suggest a concrete path forward for policymakers and researchers.
Computational Analysis of Character Development in Holocaust Testimonies
Dec 22, 2024This work presents a computational approach to analyze character development along the narrative timeline. The analysis characterizes the inner and outer changes the protagonist undergoes within a narrative, and the interplay between them. We consider transcripts of Holocaust survivor testimonies as a test case, each telling the story of an individual in first-person terms. We focus on the survivor's religious trajectory, examining the evolution of their disposition toward religious belief and practice along the testimony. Clustering the resulting trajectories in the dataset, we identify common sequences in the data. Our findings highlight multiple common structures of religiosity across the narratives: in terms of belief, most present a constant disposition, while for practice, most present an oscillating structure, serving as valuable material for historical and sociological research. This work demonstrates the potential of natural language processing techniques for analyzing character evolution through thematic trajectories in narratives.
Identifying Narrative Patterns and Outliers in Holocaust Testimonies Using Topic Modeling
May 04, 2024


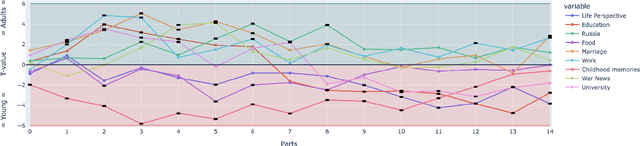
The vast collection of Holocaust survivor testimonies presents invaluable historical insights but poses challenges for manual analysis. This paper leverages advanced Natural Language Processing (NLP) techniques to explore the USC Shoah Foundation Holocaust testimony corpus. By treating testimonies as structured question-and-answer sections, we apply topic modeling to identify key themes. We experiment with BERTopic, which leverages recent advances in language modeling technology. We align testimony sections into fixed parts, revealing the evolution of topics across the corpus of testimonies. This highlights both a common narrative schema and divergences between subgroups based on age and gender. We introduce a novel method to identify testimonies within groups that exhibit atypical topic distributions resembling those of other groups. This study offers unique insights into the complex narratives of Holocaust survivors, demonstrating the power of NLP to illuminate historical discourse and identify potential deviations in survivor experiences.
The Perfect Victim: Computational Analysis of Judicial Attitudes towards Victims of Sexual Violence
May 09, 2023We develop computational models to analyze court statements in order to assess judicial attitudes toward victims of sexual violence in the Israeli court system. The study examines the resonance of "rape myths" in the criminal justice system's response to sex crimes, in particular in judicial assessment of victim's credibility. We begin by formulating an ontology for evaluating judicial attitudes toward victim's credibility, with eight ordinal labels and binary categorizations. Second, we curate a manually annotated dataset for judicial assessments of victim's credibility in the Hebrew language, as well as a model that can extract credibility labels from court cases. The dataset consists of 855 verdict decision documents in sexual assault cases from 1990-2021, annotated with the help of legal experts and trained law students. The model uses a combined approach of syntactic and latent structures to find sentences that convey the judge's attitude towards the victim and classify them according to the credibility label set. Our ontology, data, and models will be made available upon request, in the hope they spur future progress in this judicial important task.
Topical Segmentation of Spoken Narratives: A Test Case on Holocaust Survivor Testimonies
Oct 25, 2022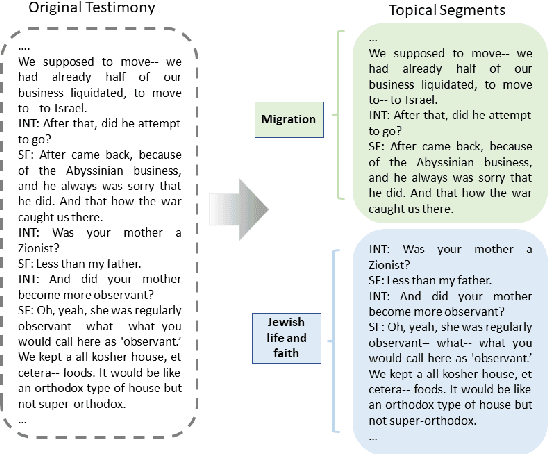
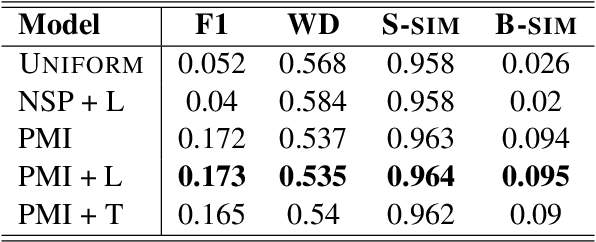
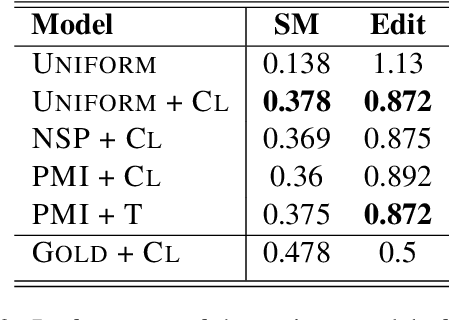
The task of topical segmentation is well studied, but previous work has mostly addressed it in the context of structured, well-defined segments, such as segmentation into paragraphs, chapters, or segmenting text that originated from multiple sources. We tackle the task of segmenting running (spoken) narratives, which poses hitherto unaddressed challenges. As a test case, we address Holocaust survivor testimonies, given in English. Other than the importance of studying these testimonies for Holocaust research, we argue that they provide an interesting test case for topical segmentation, due to their unstructured surface level, relative abundance (tens of thousands of such testimonies were collected), and the relatively confined domain that they cover. We hypothesize that boundary points between segments correspond to low mutual information between the sentences proceeding and following the boundary. Based on this hypothesis, we explore a range of algorithmic approaches to the task, building on previous work on segmentation that uses generative Bayesian modeling and state-of-the-art neural machinery. Compared to manually annotated references, we find that the developed approaches show considerable improvements over previous work.
Automated Extraction of Sentencing Decisions from Court Cases in the Hebrew Language
Oct 24, 2021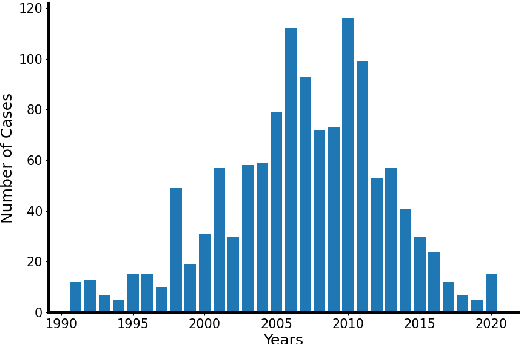

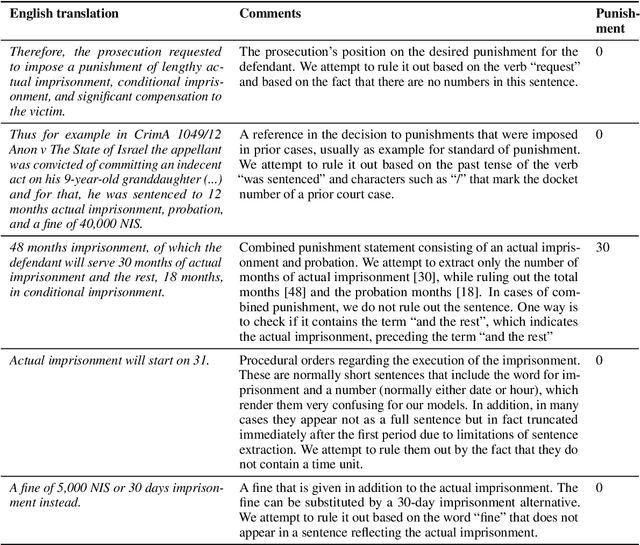

We present the task of Automated Punishment Extraction (APE) in sentencing decisions from criminal court cases in Hebrew. Addressing APE will enable the identification of sentencing patterns and constitute an important stepping stone for many follow up legal NLP applications in Hebrew, including the prediction of sentencing decisions. We curate a dataset of sexual assault sentencing decisions and a manually-annotated evaluation dataset, and implement rule-based and supervised models. We find that while supervised models can identify the sentence containing the punishment with good accuracy, rule-based approaches outperform them on the full APE task. We conclude by presenting a first analysis of sentencing patterns in our dataset and analyze common models' errors, indicating avenues for future work, such as distinguishing between probation and actual imprisonment punishment. We will make all our resources available upon request, including data, annotation, and first benchmark models.