 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feelings to Metrics: Understanding and Formalizing How Users Vibe-Test LLMs
Apr 16, 2026Evaluating LLMs is challenging, as benchmark scores often fail to capture models' real-world usefulness. Instead, users often rely on ``vibe-testing'': informal experience-based evaluation, such as comparing models on coding tasks related to their own workflow. While prevalent, vibe-testing is often too ad hoc and unstructured to analyze or reproduce at scale. In this work, we study how vibe-testing works in practice and then formalize it to support systematic analysis. We first analyze two empirical resources: (1) a survey of user evaluation practices, and (2) a collection of in-the-wild model comparison reports from blogs and social media. Based on these resources, we formalize vibe-testing as a two-part process: users personalize both what they test and how they judge responses. We then introduce a proof-of-concept evaluation pipeline that follows this formulation by generating personalized prompts and comparing model outputs using user-aware subjective criteria. In experiments on coding benchmarks, we find that combining personalized prompts and user-aware evaluation can change which model is preferred, reflecting the role of vibe-testing in practice. These findings suggest that formalized vibe-testing can serve as a useful approach for bridging benchmark scores and real-world experience.
Growing Pains: Extensible and Efficient LLM Benchmarking Via Fixed Parameter Calibration
Apr 14, 2026The rapid release of both language models and benchmarks makes it increasingly costly to evaluate every model on every dataset. In practice, models are often evaluated on different samples, making scores difficult to compare across studies. To address this, we propose a framework based on multidimensional Item Response Theory (IRT) that uses anchor items to calibrate new benchmarks to the evaluation suite while holding previously calibrated item parameters fixed. Our approach supports a realistic evaluation setting in which datasets are introduced over time and models are evaluated only on the datasets available at the time of evaluation, while a fixed anchor set for each dataset is used so that results from different evaluation periods can be compared directly. In large-scale experiments on more than $400$ models, our framework predicts full-evaluation performance within 2-3 percentage points using only $100$ anchor questions per dataset, with Spearman $ρ\geq 0.9$ for ranking preservation, showing that it is possible to extend benchmark suites over time while preserving score comparability, at a constant evaluation cost per new dataset. Code available at https://github.com/eliyahabba/growing-pains
ScheMatiQ: From Research Question to Structured Data through Interactive Schema Discovery
Apr 10, 2026Many disciplines pose natural-language research questions over large document collections whose answers typically require structured evidence, traditionally obtained by manually designing an annotation schema and exhaustively labeling the corpus, a slow and error-prone process. We introduce ScheMatiQ, which leverages calls to a backbone LLM to take a question and a corpus to produce a schema and a grounded database, with a web interface that lets steer and revise the extraction. In collaboration with domain experts, we show that ScheMatiQ yields outputs that support real-world analysis in law and computational biology. We release ScheMatiQ as open source with a public web interface, and invite experts across disciplines to use it with their own data. All resources, including the website, source code, and demonstration video, are available at: www.ScheMatiQ-ai.com
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
JSON Whisperer: Efficient JSON Editing with LLMs
Oct 06, 2025Large language models (LLMs) can modify JSON documents through natural language commands, but current approaches regenerate entire structures for each edit, resulting in computational inefficiency. We present JSON Whisperer, a framework that enables LLMs to generate RFC 6902 diff patches-expressing only the necessary modifications-rather than complete documents. We identify two key challenges in patch-based editing: (1) LLMs often miss related updates when generating isolated patches, and (2) array manipulations require tracking index shifts across operations, which LLMs handle poorly. To address these issues, we introduce EASE (Explicitly Addressed Sequence Encoding), which transforms arrays into dictionaries with stable keys, eliminating index arithmetic complexities. Our evaluation shows that patch generation with EASE reduces token usage by 31% while maintaining edit quality within 5% of full regeneration with particular gains for complex instructions and list manipulations. The dataset is available at: https://github.com/emnlp2025/JSON-Whisperer/
ReliableEval: A Recipe for Stochastic LLM Evaluation via Method of Moments
May 28, 2025



LLMs are highly sensitive to prompt phrasing, yet standard benchmarks typically report performance using a single prompt, raising concerns about the reliability of such evaluations. In this work, we argue for a stochastic method of moments evaluation over the space of meaning-preserving prompt perturbations. We introduce a formal definition of reliable evaluation that accounts for prompt sensitivity, and suggest ReliableEval - a method for estimating the number of prompt resamplings needed to obtain meaningful results. Using our framework, we stochastically evaluate five frontier LLMs and find that even top-performing models like GPT-4o and Claude-3.7-Sonnet exhibit substantial prompt sensitivity. Our approach is model-, task-, and metric-agnostic, offering a recipe for meaningful and robust LLM evaluation.
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
Beyond Benchmarks: On The False Promise of AI Regulation
Jan 26, 2025

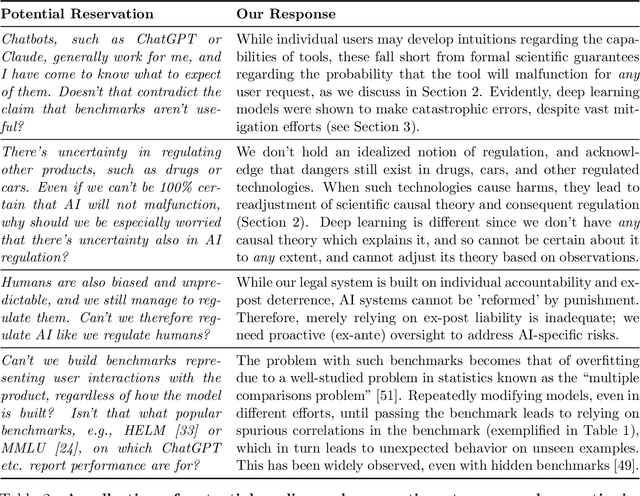

The rapid advancement of artificial intelligence (AI) systems in critical domains like healthcare, justice, and social services has sparked numerous regulatory initiatives aimed at ensuring their safe deployment. Current regulatory frameworks, exemplified by recent US and EU efforts, primarily focus on procedural guidelines while presuming that scientific benchmarking can effectively validate AI safety, similar to how crash tests verify vehicle safety or clinical trials validate drug efficacy. However, this approach fundamentally misunderstands the unique technical challenges posed by modern AI systems. Through systematic analysis of successful technology regulation case studies, we demonstrate that effective scientific regulation requires a causal theory linking observable test outcomes to future performance - for instance, how a vehicle's crash resistance at one speed predicts its safety at lower speeds. We show that deep learning models, which learn complex statistical patterns from training data without explicit causal mechanisms, preclude such guarantees. This limitation renders traditional regulatory approaches inadequate for ensuring AI safety. Moving forward, we call for regulators to reckon with this limitation, and propose a preliminary two-tiered regulatory framework that acknowledges these constraints: mandating human oversight for high-risk applications while developing appropriate risk communication strategies for lower-risk uses. Our findings highlight the urgent need to reconsider fundamental assumptions in AI regulation and suggest a concrete path forward for policymakers and researchers.
Visual Riddles: a Commonsense and World Knowledge Challenge for Large Vision and Language Models
Jul 28, 2024Imagine observing someone scratching their arm; to understand why, additional context would be necessary. However, spotting a mosquito nearby would immediately offer a likely explanation for the person's discomfort, thereby alleviating the need for further information. This example illustrates how subtle visual cues can challenge our cognitive skills and demonstrates the complexity of interpreting visual scenarios. To study these skills, we present Visual Riddles, a benchmark aimed to test vision and language models on visual riddles requiring commonsense and world knowledge. The benchmark comprises 400 visual riddles, each featuring a unique image created by a variety of text-to-image models, question, ground-truth answer, textual hint, and attribution. Human evaluation reveals that existing models lag significantly behind human performance, which is at 82\% accuracy, with Gemini-Pro-1.5 leading with 40\% accuracy. Our benchmark comes with automatic evaluation tasks to make assessment scalable. These findings underscore the potential of Visual Riddles as a valuable resource for enhancing vision and language models' capabilities in interpreting complex visual scenarios.