 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowing Pains: Extensible and Efficient LLM Benchmarking Via Fixed Parameter Calibration
Apr 14, 2026The rapid release of both language models and benchmarks makes it increasingly costly to evaluate every model on every dataset. In practice, models are often evaluated on different samples, making scores difficult to compare across studies. To address this, we propose a framework based on multidimensional Item Response Theory (IRT) that uses anchor items to calibrate new benchmarks to the evaluation suite while holding previously calibrated item parameters fixed. Our approach supports a realistic evaluation setting in which datasets are introduced over time and models are evaluated only on the datasets available at the time of evaluation, while a fixed anchor set for each dataset is used so that results from different evaluation periods can be compared directly. In large-scale experiments on more than $400$ models, our framework predicts full-evaluation performance within 2-3 percentage points using only $100$ anchor questions per dataset, with Spearman $ρ\geq 0.9$ for ranking preservation, showing that it is possible to extend benchmark suites over time while preserving score comparability, at a constant evaluation cost per new dataset. Code available at https://github.com/eliyahabba/growing-pains
CUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
General Agent Evaluation
Feb 26, 2026The promise of general-purpose agents - systems that perform tasks in unfamiliar environments without domain-specific engineering - remains largely unrealized. Existing agents are predominantly specialized, and while emerging implementations like OpenAI SDK Agent and Claude Code hint at broader capabilities, no systematic evaluation of their general performance has been pursued. Current agentic benchmarks assume domain-specific integration, encoding task information in ways that preclude fair evaluation of general agents. This paper frames general-agent evaluation as a first-class research objective. We propose conceptual principles for such evaluation, a Unified Protocol enabling agent-benchmark integration, and Exgentic - a practical framework for general agent evaluation. We benchmark five prominent agent implementations across six environments as the first Open General Agent Leaderboard. Our experiments show that general agents generalize across diverse environments, achieving performance comparable to domain-specific agents without any environment-specific tuning. We release our evaluation protocol, framework, and leaderboard to establish a foundation for systematic research on general-purpose agents.
Robustness as an Emergent Property of Task Performance
Feb 03, 2026Robustness is often regarded as a critical future challenge for real-world applications, where stability is essential. However, as models often learn tasks in a similar order, we hypothesize that easier tasks will be easier regardless of how they are presented to the model. Indeed, in this paper, we show that as models approach high performance on a task, robustness is effectively achieved. Through an empirical analysis of multiple models across diverse datasets and configurations (e.g., paraphrases, different temperatures), we find a strong positive correlation. Moreover, we find that robustness is primarily driven by task-specific competence rather than inherent model-level properties, challenging current approaches that treat robustness as an independent capability. Thus, from a high-level perspective, we may expect that as new tasks saturate, model robustness on these tasks will emerge accordingly. For researchers, this implies that explicit efforts to measure and improve robustness may warrant reduced emphasis, as such robustness is likely to develop alongside performance gains. For practitioners, it acts as a sign that indeed the tasks that the literature deals with are unreliable, but on easier past tasks, the models are reliable and ready for real-world deployment.
ErrorMap and ErrorAtlas: Charting the Failure Landscape of Large Language Models
Jan 22, 2026Large Language Models (LLM) benchmarks tell us when models fail, but not why they fail. A wrong answer on a reasoning dataset may stem from formatting issues, calculation errors, or dataset noise rather than weak reasoning. Without disentangling such causes, benchmarks remain incomplete and cannot reliably guide model improvement. We introduce ErrorMap, the first method to chart the sources of LLM failure. It extracts a model's unique "failure signature", clarifies what benchmarks measure, and broadens error identification to reduce blind spots. This helps developers debug models, aligns benchmark goals with outcomes, and supports informed model selection. ErrorMap works on any model or dataset with the same logic. Applying our method to 35 datasets and 83 models we generate ErrorAtlas, a taxonomy of model errors, revealing recurring failure patterns. ErrorAtlas highlights error types that are currently underexplored in LLM research, such as omissions of required details in the output and question misinterpretation. By shifting focus from where models succeed to why they fail, ErrorMap and ErrorAtlas enable advanced evaluation - one that exposes hidden weaknesses and directs progress. Unlike success, typically measured by task-level metrics, our approach introduces a deeper evaluation layer that can be applied globally across models and tasks, offering richer insights into model behavior and limitations. We make the taxonomy and code publicly available with plans to periodically update ErrorAtlas as new benchmarks and models emerge.
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Mar 04, 2025Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
Benchmark Agreement Testing Done Right: A Guide for LLM Benchmark Evaluation
Jul 18, 2024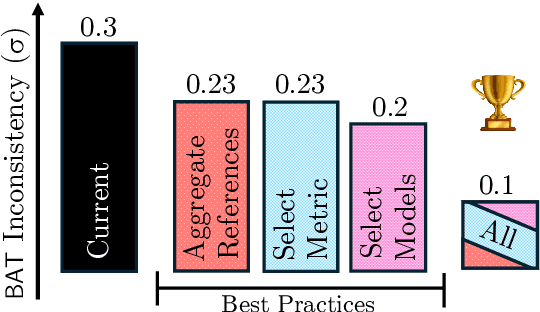
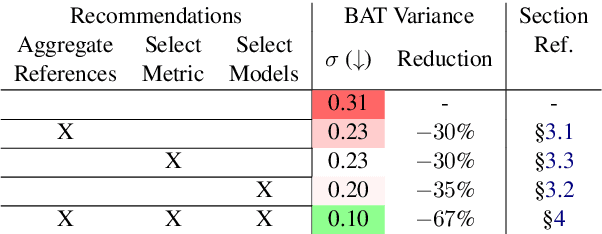
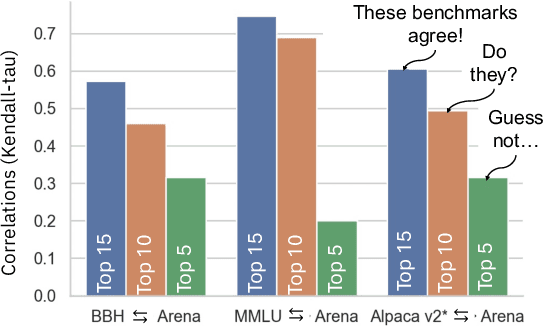
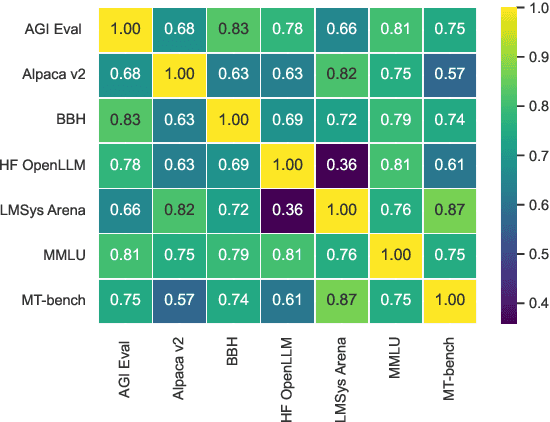
Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models' general capabilities. A crucial task, however, is assessing the validity of the benchmarks themselves. This is most commonly done via Benchmark Agreement Testing (BAT), where new benchmarks are validated against established ones using some agreement metric (e.g., rank correlation). Despite the crucial role of BAT for benchmark builders and consumers, there are no standardized procedures for such agreement testing. This deficiency can lead to invalid conclusions, fostering mistrust in benchmarks and upending the ability to properly choose the appropriate benchmark to use. By analyzing over 40 prominent benchmarks, we demonstrate how some overlooked methodological choices can significantly influence BAT results, potentially undermining the validity of conclusions. To address these inconsistencies, we propose a set of best practices for BAT and demonstrate how utilizing these methodologies greatly improves BAT robustness and validity. To foster adoption and facilitate future research,, we introduce BenchBench, a python package for BAT, and release the BenchBench-leaderboard, a meta-benchmark designed to evaluate benchmarks using their peers. Our findings underscore the necessity for standardized BAT, ensuring the robustness and validity of benchmark evaluations in the evolving landscape of language model research. BenchBench Package: https://github.com/IBM/BenchBench Leaderboard: https://huggingface.co/spaces/per/BenchBench
Unitxt: Flexible, Shareable and Reusable Data Preparation and Evaluation for Generative AI
Jan 25, 2024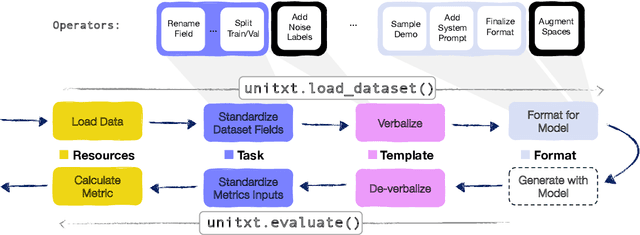

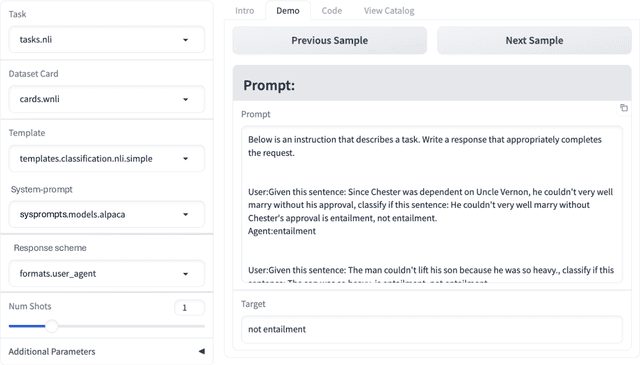

In the dynamic landscape of generative NLP, traditional text processing pipelines limit research flexibility and reproducibility, as they are tailored to specific dataset, task, and model combinations. The escalating complexity, involving system prompts, model-specific formats, instructions, and more, calls for a shift to a structured, modular, and customizable solution. Addressing this need, we present Unitxt, an innovative library for customizable textual data preparation and evaluation tailored to generative language models. Unitxt natively integrates with common libraries like HuggingFace and LM-eval-harness and deconstructs processing flows into modular components, enabling easy customization and sharing between practitioners. These components encompass model-specific formats, task prompts, and many other comprehensive dataset processing definitions. The Unitxt-Catalog centralizes these components, fostering collaboration and exploration in modern textual data workflows. Beyond being a tool, Unitxt is a community-driven platform, empowering users to build, share, and advance their pipelines collaboratively. Join the Unitxt community at https://github.com/IBM/unitxt!
Efficient Benchmarking (of Language Models)
Aug 31, 2023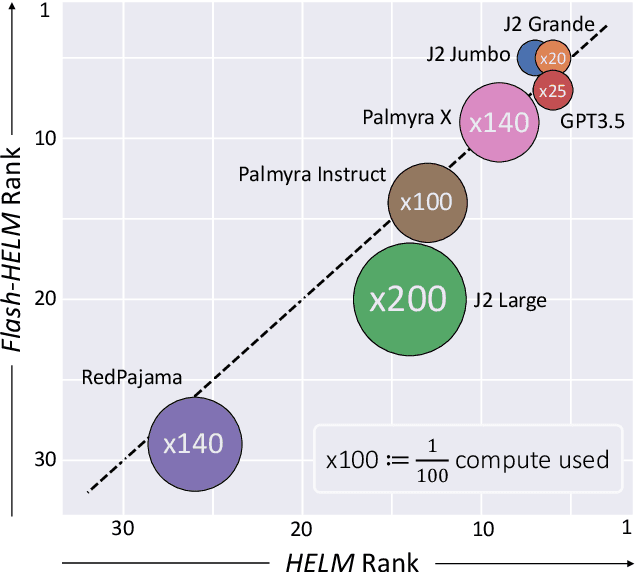
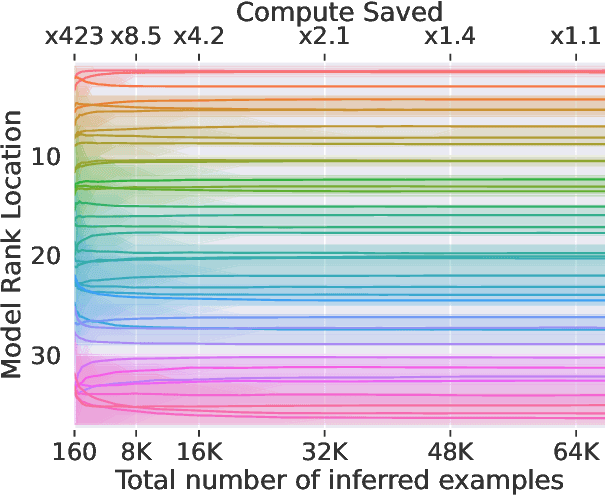
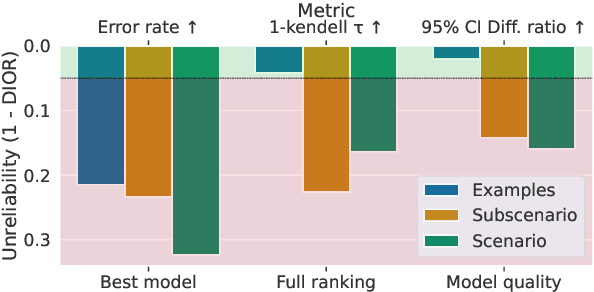
The increasing versatility of language models LMs has given rise to a new class of benchmarks that comprehensively assess a broad range of capabilities. Such benchmarks are associated with massive computational costs reaching thousands of GPU hours per model. However the efficiency aspect of these evaluation efforts had raised little discussion in the literature. In this work we present the problem of Efficient Benchmarking namely intelligently reducing the computation costs of LM evaluation without compromising reliability. Using the HELM benchmark as a test case we investigate how different benchmark design choices affect the computation-reliability tradeoff. We propose to evaluate the reliability of such decisions by using a new measure Decision Impact on Reliability DIoR for short. We find for example that the current leader on HELM may change by merely removing a low-ranked model from the benchmark and observe that a handful of examples suffice to obtain the correct benchmark ranking. Conversely a slightly different choice of HELM scenarios varies ranking widely. Based on our findings we outline a set of concrete recommendations for more efficient benchmark design and utilization practices leading to dramatic cost savings with minimal loss of benchmark reliability often reducing computation by x100 or more.