 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash-GMM: A Memory-Efficient Kernel for Scalable Soft Clustering
Jun 09, 2026We present \textbf{Flash-GMM}, a fused Triton kernel for efficient computation of Gaussian Mixture Models (GMMs) over large-scale data in a single GPU pass. By eliminating the need to materialize the full responsibility matrix in GPU memory, Flash-GMM achieves a \textbf{20$\times$} speedup over existing implementations and enables training on datasets more than \textbf{100$\times$} larger than previously feasible on one device. To demonstrate its impact, we integrate Flash-GMM into the IVF coarse quantizer for approximate nearest-neighbor (ANN) search. We show that soft GMM clustering is now a viable drop-in replacement for $k$-means, and that GMM responsibilities can be leveraged to assign border vectors to multiple clusters. Our approach reaches fixed recall targets with up to $1.7\times$ fewer distance computations, or equivalently, yields $+2$--$12$ recall@10 at matched computational cost. We release the kernel as an open-source project.
Teaching Values to Machines: Simulating Human-Like Behavior in LLMs
May 28, 2026Large Language Models (LLMs) demonstrate a remarkable capacity to adopt different personas and roles; however, it remains unclear whether they can manifest behavior that adheres to a coherent, human-like value structure. In this work, we draw on established psychological value theory to induce human-like values in LLMs and assess their alignment with patterns observed in human studies. Using validated psychological questionnaires, we conduct large-scale experiments -- over 5 million questions -- to evaluate value structures and value-behavior relationships in leading LLMs and compare them to humans. Our findings reveal strong agreement between value-prompted LLMs and humans across both dimensions. Moreover, incorporating human value distributions enhances population-level simulations with value-induced LLMs. These findings highlight the potential of value-induced LLMs as effective, psychologically grounded tools for simulating human behavior.
Task-Adaptive Embedding Refinement via Test-time LLM Guidance
May 12, 2026We explore the effectiveness of an LLM-guided query refinement paradigm for extending the usability of embedding models to challenging zero-shot search and classification tasks. Our approach refines the embedding representation of a user query using feedback from a generative LLM on a small set of documents, enabling embeddings to adapt in real time to the target task. We conduct extensive experiments with state-of-the-art text embedding models across a diverse set of challenging search and classification benchmarks. Empirical results indicate that LLM-guided query refinement yields consistent gains across all models and datasets, with relative improvements of up to +25% in literature search, intent detection, key-point matching, and nuanced query-instruction following. The refined queries improve ranking quality and induce clearer binary separation across the corpus, enabling the embedding space to better reflect the nuanced, task-specific constraints of each ad-hoc user query. Importantly, this expands the range of practical settings in which embedding models can be effectively deployed, making them a compelling alternative when costly LLM pipelines are not viable at corpus-scale. We release our experimental code for reproducibility, at https://github.com/IBM/task-aware-embedding-refinement.
Robustness as an Emergent Property of Task Performance
Feb 03, 2026Robustness is often regarded as a critical future challenge for real-world applications, where stability is essential. However, as models often learn tasks in a similar order, we hypothesize that easier tasks will be easier regardless of how they are presented to the model. Indeed, in this paper, we show that as models approach high performance on a task, robustness is effectively achieved. Through an empirical analysis of multiple models across diverse datasets and configurations (e.g., paraphrases, different temperatures), we find a strong positive correlation. Moreover, we find that robustness is primarily driven by task-specific competence rather than inherent model-level properties, challenging current approaches that treat robustness as an independent capability. Thus, from a high-level perspective, we may expect that as new tasks saturate, model robustness on these tasks will emerge accordingly. For researchers, this implies that explicit efforts to measure and improve robustness may warrant reduced emphasis, as such robustness is likely to develop alongside performance gains. For practitioners, it acts as a sign that indeed the tasks that the literature deals with are unreliable, but on easier past tasks, the models are reliable and ready for real-world deployment.
Guided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Oct 06, 2025

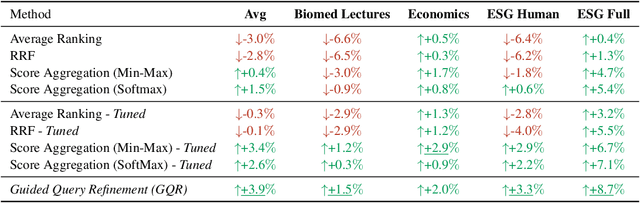

Multimodal encoders have pushed the boundaries of visual document retrieval, matching textual query tokens directly to image patches and achieving state-of-the-art performance on public benchmarks. Recent models relying on this paradigm have massively scaled the sizes of their query and document representations, presenting obstacles to deployment and scalability in real-world pipelines. Furthermore, purely vision-centric approaches may be constrained by the inherent modality gap still exhibited by modern vision-language models. In this work, we connect these challenges to the paradigm of hybrid retrieval, investigating whether a lightweight dense text retriever can enhance a stronger vision-centric model. Existing hybrid methods, which rely on coarse-grained fusion of ranks or scores, fail to exploit the rich interactions within each model's representation space. To address this, we introduce Guided Query Refinement (GQR), a novel test-time optimization method that refines a primary retriever's query embedding using guidance from a complementary retriever's scores. Through extensive experiments on visual document retrieval benchmarks, we demonstrate that GQR allows vision-centric models to match the performance of models with significantly larger representations, while being up to 14x faster and requiring 54x less memory. Our findings show that GQR effectively pushes the Pareto frontier for performance and efficiency in multimodal retrieval. We release our code at https://github.com/IBM/test-time-hybrid-retrieval
Debatable Intelligence: Benchmarking LLM Judges via Debate Speech Evaluation
Jun 05, 2025We introduce Debate Speech Evaluation as a novel and challenging benchmark for assessing LLM judges. Evaluating debate speeches requires a deep understanding of the speech at multiple levels, including argument strength and relevance, the coherence and organization of the speech, the appropriateness of its style and tone, and so on. This task involves a unique set of cognitive abilities that have previously received limited attention in systematic LLM benchmarking. To explore such skills, we leverage a dataset of over 600 meticulously annotated debate speeches and present the first in-depth analysis of how state-of-the-art LLMs compare to human judges on this task. Our findings reveal a nuanced picture: while larger models can approximate individual human judgments in some respects, they differ substantially in their overall judgment behavior. We also investigate the ability of frontier LLMs to generate persuasive, opinionated speeches, showing that models may perform at a human level on this task.
An Analysis of Hyper-Parameter Optimization Methods for Retrieval Augmented Generation
May 06, 2025Finding the optimal Retrieval-Augmented Generation (RAG) configuration for a given use case can be complex and expensive. Motivated by this challenge, frameworks for RAG hyper-parameter optimization (HPO) have recently emerged, yet their effectiveness has not been rigorously benchmarked. To address this gap, we present a comprehensive study involving 5 HPO algorithms over 5 datasets from diverse domains, including a new one collected for this work on real-world product documentation. Our study explores the largest HPO search space considered to date, with two optimized evaluation metrics. Analysis of the results shows that RAG HPO can be done efficiently, either greedily or with iterative random search, and that it significantly boosts RAG performance for all datasets. For greedy HPO approaches, we show that optimizing models first is preferable to the prevalent practice of optimizing sequentially according to the RAG pipeline order.
WildIFEval: Instruction Following in the Wild
Mar 09, 2025



Recent LLMs have shown remarkable success in following user instructions, yet handling instructions with multiple constraints remains a significant challenge. In this work, we introduce WildIFEval - a large-scale dataset of 12K real user instructions with diverse, multi-constraint conditions. Unlike prior datasets, our collection spans a broad lexical and topical spectrum of constraints, in natural user prompts. We categorize these constraints into eight high-level classes to capture their distribution and dynamics in real-world scenarios. Leveraging WildIFEval, we conduct extensive experiments to benchmark the instruction-following capabilities of leading LLMs. Our findings reveal that all evaluated models experience performance degradation with an increasing number of constraints. Thus, we show that all models have a large room for improvement on such tasks. Moreover, we observe that the specific type of constraint plays a critical role in model performance. We release our dataset to promote further research on instruction-following under complex, realistic conditions.
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
JuStRank: Benchmarking LLM Judges for System Ranking
Dec 12, 2024



Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such evaluations make the use of LLM-based judges a compelling solution for this challenge. Crucially, this approach requires first to validate the quality of the LLM judge itself. Previous work has focused on instance-based assessment of LLM judges, where a judge is evaluated over a set of responses, or response pairs, while being agnostic to their source systems. We argue that this setting overlooks critical factors affecting system-level ranking, such as a judge's positive or negative bias towards certain systems. To address this gap, we conduct the first large-scale study of LLM judges as system rankers. System scores are generated by aggregating judgment scores over multiple system outputs, and the judge's quality is assessed by comparing the resulting system ranking to a human-based ranking. Beyond overall judge assessment, our analysis provides a fine-grained characterization of judge behavior, including their decisiveness and bias.