 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill it Merge? On The Causes of Model Mergeability
Jan 10, 2026Model merging has emerged as a promising technique for combining multiple fine-tuned models into a single multitask model without retraining. However, the factors that determine whether merging will succeed or fail remain poorly understood. In this work, we investigate why specific models are merged better than others. To do so, we propose a concrete, measurable definition of mergeability. We investigate several potential causes for high or low mergeability, highlighting the base model knowledge as a dominant factor: Models fine-tuned on instances that the base model knows better are more mergeable than models fine-tuned on instances that the base model struggles with. Based on our mergeability definition, we explore a simple weighted merging technique that better preserves weak knowledge in the base model.
Guided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Oct 06, 2025Multimodal encoders have pushed the boundaries of visual document retrieval, matching textual query tokens directly to image patches and achieving state-of-the-art performance on public benchmarks. Recent models relying on this paradigm have massively scaled the sizes of their query and document representations, presenting obstacles to deployment and scalability in real-world pipelines. Furthermore, purely vision-centric approaches may be constrained by the inherent modality gap still exhibited by modern vision-language models. In this work, we connect these challenges to the paradigm of hybrid retrieval, investigating whether a lightweight dense text retriever can enhance a stronger vision-centric model. Existing hybrid methods, which rely on coarse-grained fusion of ranks or scores, fail to exploit the rich interactions within each model's representation space. To address this, we introduce Guided Query Refinement (GQR), a novel test-time optimization method that refines a primary retriever's query embedding using guidance from a complementary retriever's scores. Through extensive experiments on visual document retrieval benchmarks, we demonstrate that GQR allows vision-centric models to match the performance of models with significantly larger representations, while being up to 14x faster and requiring 54x less memory. Our findings show that GQR effectively pushes the Pareto frontier for performance and efficiency in multimodal retrieval. We release our code at https://github.com/IBM/test-time-hybrid-retrieval
Survey on Evaluation of LLM-based Agents
Mar 20, 2025The emergence of LLM-based agents represents a paradigm shift in AI, enabling autonomous systems to plan, reason, use tools, and maintain memory while interacting with dynamic environments. This paper provides the first comprehensive survey of evaluation methodologies for these increasingly capable agents. We systematically analyze evaluation benchmarks and frameworks across four critical dimensions: (1) fundamental agent capabilities, including planning, tool use, self-reflection, and memory; (2) application-specific benchmarks for web, software engineering, scientific, and conversational agents; (3) benchmarks for generalist agents; and (4) frameworks for evaluating agents. Our analysis reveals emerging trends, including a shift toward more realistic, challenging evaluations with continuously updated benchmarks. We also identify critical gaps that future research must address-particularly in assessing cost-efficiency, safety, and robustness, and in developing fine-grained, and scalable evaluation methods. This survey maps the rapidly evolving landscape of agent evaluation, reveals the emerging trends in the field, identifies current limitations, and proposes directions for future research.
WildIFEval: Instruction Following in the Wild
Mar 09, 2025



Recent LLMs have shown remarkable success in following user instructions, yet handling instructions with multiple constraints remains a significant challenge. In this work, we introduce WildIFEval - a large-scale dataset of 12K real user instructions with diverse, multi-constraint conditions. Unlike prior datasets, our collection spans a broad lexical and topical spectrum of constraints, in natural user prompts. We categorize these constraints into eight high-level classes to capture their distribution and dynamics in real-world scenarios. Leveraging WildIFEval, we conduct extensive experiments to benchmark the instruction-following capabilities of leading LLMs. Our findings reveal that all evaluated models experience performance degradation with an increasing number of constraints. Thus, we show that all models have a large room for improvement on such tasks. Moreover, we observe that the specific type of constraint plays a critical role in model performance. We release our dataset to promote further research on instruction-following under complex, realistic conditions.
The Mighty ToRR: A Benchmark for Table Reasoning and Robustness
Feb 26, 2025



Despite its real-world significance, model performance on tabular data remains underexplored, leaving uncertainty about which model to rely on and which prompt configuration to adopt. To address this gap, we create ToRR, a benchmark for Table Reasoning and Robustness, that measures model performance and robustness on table-related tasks. The benchmark includes 10 datasets that cover different types of table reasoning capabilities across varied domains. ToRR goes beyond model performance rankings, and is designed to reflect whether models can handle tabular data consistently and robustly, across a variety of common table representation formats. We present a leaderboard as well as comprehensive analyses of the results of leading models over ToRR. Our results reveal a striking pattern of brittle model behavior, where even strong models are unable to perform robustly on tabular data tasks. Although no specific table format leads to consistently better performance, we show that testing over multiple formats is crucial for reliably estimating model capabilities. Moreover, we show that the reliability boost from testing multiple prompts can be equivalent to adding more test examples. Overall, our findings show that table understanding and reasoning tasks remain a significant challenge.
Selective Self-to-Supervised Fine-Tuning for Generalization in Large Language Models
Feb 12, 2025Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-to-Supervised Fine-Tuning (S3FT), a fine-tuning approach that achieves better performance than the standard supervised fine-tuning (SFT) while improving generalization. S3FT leverages the existence of multiple valid responses to a query. By utilizing the model's correct responses, S3FT reduces model specialization during the fine-tuning stage. S3FT first identifies the correct model responses from the training set by deploying an appropriate judge. Then, it fine-tunes the model using the correct model responses and the gold response (or its paraphrase) for the remaining samples. The effectiveness of S3FT is demonstrated through experiments on mathematical reasoning, Python programming and reading comprehension tasks. The results show that standard SFT can lead to an average performance drop of up to $4.4$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, S3FT reduces this drop by half, i.e. $2.5$, indicating better generalization capabilities than SFT while performing significantly better on the fine-tuning tasks.
JuStRank: Benchmarking LLM Judges for System Ranking
Dec 12, 2024



Given the rapid progress of generative AI, there is a pressing need to systematically compare and choose between the numerous models and configurations available. The scale and versatility of such evaluations make the use of LLM-based judges a compelling solution for this challenge. Crucially, this approach requires first to validate the quality of the LLM judge itself. Previous work has focused on instance-based assessment of LLM judges, where a judge is evaluated over a set of responses, or response pairs, while being agnostic to their source systems. We argue that this setting overlooks critical factors affecting system-level ranking, such as a judge's positive or negative bias towards certain systems. To address this gap, we conduct the first large-scale study of LLM judges as system rankers. System scores are generated by aggregating judgment scores over multiple system outputs, and the judge's quality is assessed by comparing the resulting system ranking to a human-based ranking. Beyond overall judge assessment, our analysis provides a fine-grained characterization of judge behavior, including their decisiveness and bias.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024
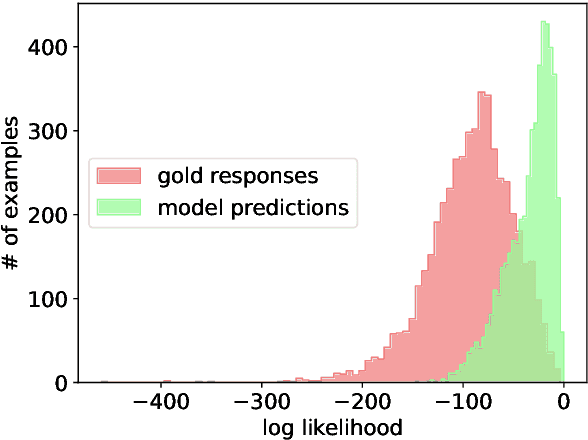
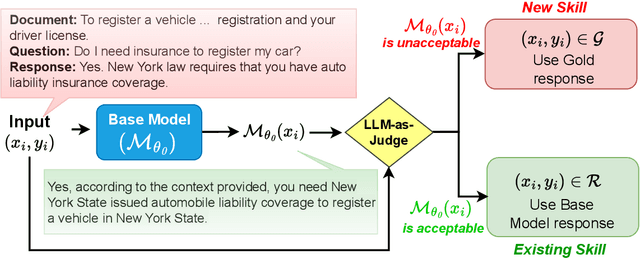
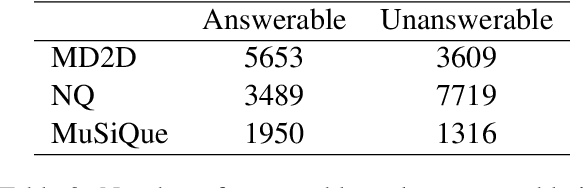
Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.
Benchmark Agreement Testing Done Right: A Guide for LLM Benchmark Evaluation
Jul 18, 2024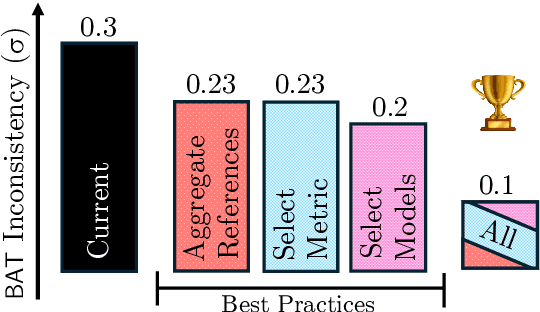
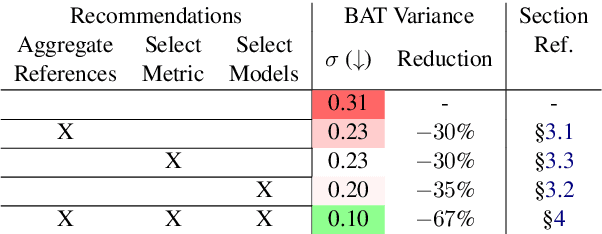
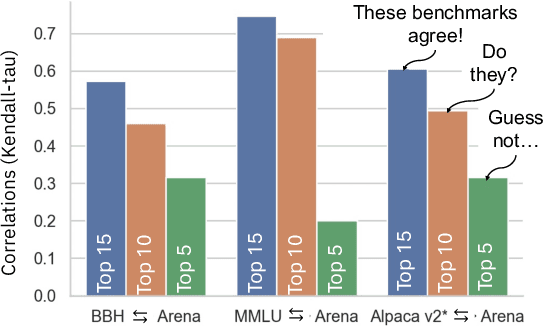
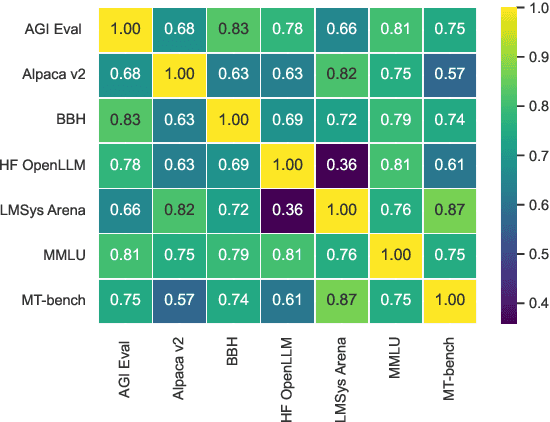
Recent advancements in Language Models (LMs) have catalyzed the creation of multiple benchmarks, designed to assess these models' general capabilities. A crucial task, however, is assessing the validity of the benchmarks themselves. This is most commonly done via Benchmark Agreement Testing (BAT), where new benchmarks are validated against established ones using some agreement metric (e.g., rank correlation). Despite the crucial role of BAT for benchmark builders and consumers, there are no standardized procedures for such agreement testing. This deficiency can lead to invalid conclusions, fostering mistrust in benchmarks and upending the ability to properly choose the appropriate benchmark to use. By analyzing over 40 prominent benchmarks, we demonstrate how some overlooked methodological choices can significantly influence BAT results, potentially undermining the validity of conclusions. To address these inconsistencies, we propose a set of best practices for BAT and demonstrate how utilizing these methodologies greatly improves BAT robustness and validity. To foster adoption and facilitate future research,, we introduce BenchBench, a python package for BAT, and release the BenchBench-leaderboard, a meta-benchmark designed to evaluate benchmarks using their peers. Our findings underscore the necessity for standardized BAT, ensuring the robustness and validity of benchmark evaluations in the evolving landscape of language model research. BenchBench Package: https://github.com/IBM/BenchBench Leaderboard: https://huggingface.co/spaces/per/BenchBench
Applying Intrinsic Debiasing on Downstream Tasks: Challenges and Considerations for Machine Translation
Jun 02, 2024



Most works on gender bias focus on intrinsic bias -- removing traces of information about a protected group from the model's internal representation. However, these works are often disconnected from the impact of such debiasing on downstream applications, which is the main motivation for debiasing in the first place. In this work, we systematically test how methods for intrinsic debiasing affect neural machine translation models, by measuring the extrinsic bias of such systems under different design choices. We highlight three challenges and mismatches between the debiasing techniques and their end-goal usage, including the choice of embeddings to debias, the mismatch between words and sub-word tokens debiasing, and the effect on different target languages. We find that these considerations have a significant impact on downstream performance and the success of debiasing.