 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Measuring Cross-lingual Lexical Alignment: A Domain and Word Level Perspective
Oct 07, 2024NLP research on aligning lexical representation spaces to one another has so far focused on aligning language spaces in their entirety. However, cognitive science has long focused on a local perspective, investigating whether translation equivalents truly share the same meaning or the extent that cultural and regional influences result in meaning variations. With recent technological advances and the increasing amounts of available data, the longstanding question of cross-lingual lexical alignment can now be approached in a more data-driven manner. However, developing metrics for the task requires some methodology for comparing metric efficacy. We address this gap and present a methodology for analyzing both synthetic validations and a novel naturalistic validation using lexical gaps in the kinship domain. We further propose new metrics, hitherto unexplored on this task, based on contextualized embeddings. Our analysis spans 16 diverse languages, demonstrating that there is substantial room for improvement with the use of newer language models. Our research paves the way for more accurate and nuanced cross-lingual lexical alignment methodologies and evaluation.
Assessing the Role of Lexical Semantics in Cross-lingual Transfer through Controlled Manipulations
Aug 14, 2024While cross-linguistic model transfer is effective in many settings, there is still limited understanding of the conditions under which it works. In this paper, we focus on assessing the role of lexical semantics in cross-lingual transfer, as we compare its impact to that of other language properties. Examining each language property individually, we systematically analyze how differences between English and a target language influence the capacity to align the language with an English pretrained representation space. We do so by artificially manipulating the English sentences in ways that mimic specific characteristics of the target language, and reporting the effect of each manipulation on the quality of alignment with the representation space. We show that while properties such as the script or word order only have a limited impact on alignment quality, the degree of lexical matching between the two languages, which we define using a measure of translation entropy, greatly affects it.
A Nurse is Blue and Elephant is Rugby: Cross Domain Alignment in Large Language Models Reveal Human-like Patterns
May 23, 2024



Cross-domain alignment refers to the task of mapping a concept from one domain to another. For example, ``If a \textit{doctor} were a \textit{color}, what color would it be?''. This seemingly peculiar task is designed to investigate how people represent concrete and abstract concepts through their mappings between categories and their reasoning processes over those mappings. In this paper, we adapt this task from cognitive science to evaluate the conceptualization and reasoning abilities of large language models (LLMs) through a behavioral study. We examine several LLMs by prompting them with a cross-domain mapping task and analyzing their responses at both the population and individual levels. Additionally, we assess the models' ability to reason about their predictions by analyzing and categorizing their explanations for these mappings. The results reveal several similarities between humans' and models' mappings and explanations, suggesting that models represent concepts similarly to humans. This similarity is evident not only in the model representation but also in their behavior. Furthermore, the models mostly provide valid explanations and deploy reasoning paths that are similar to those of humans.
Does Mapo Tofu Contain Coffee? Probing LLMs for Food-related Cultural Knowledge
Apr 10, 2024



Recent studies have highlighted the presence of cultural biases in Large Language Models (LLMs), yet often lack a robust methodology to dissect these phenomena comprehensively. Our work aims to bridge this gap by delving into the Food domain, a universally relevant yet culturally diverse aspect of human life. We introduce FmLAMA, a multilingual dataset centered on food-related cultural facts and variations in food practices. We analyze LLMs across various architectures and configurations, evaluating their performance in both monolingual and multilingual settings. By leveraging templates in six different languages, we investigate how LLMs interact with language-specific and cultural knowledge. Our findings reveal that (1) LLMs demonstrate a pronounced bias towards food knowledge prevalent in the United States; (2) Incorporating relevant cultural context significantly improves LLMs' ability to access cultural knowledge; (3) The efficacy of LLMs in capturing cultural nuances is highly dependent on the interplay between the probing language, the specific model architecture, and the cultural context in question. This research underscores the complexity of integrating cultural understanding into LLMs and emphasizes the importance of culturally diverse datasets to mitigate biases and enhance model performance across different cultural domains.
Improving Cross-Lingual Transfer through Subtree-Aware Word Reordering
Oct 20, 2023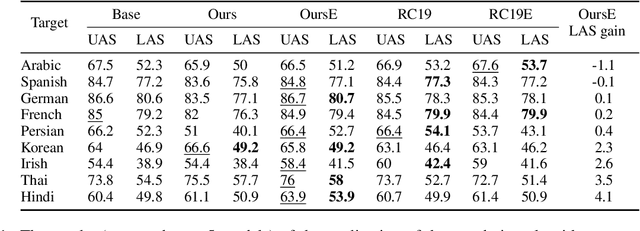
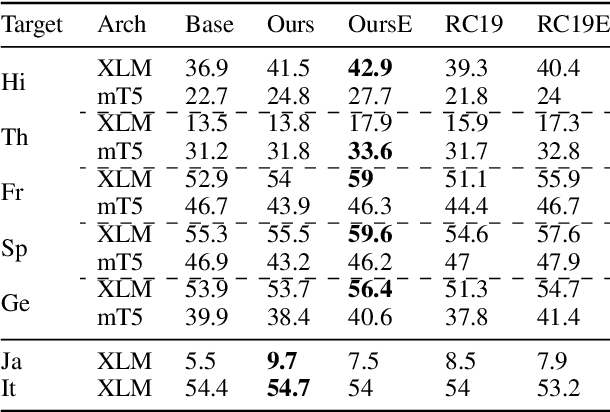
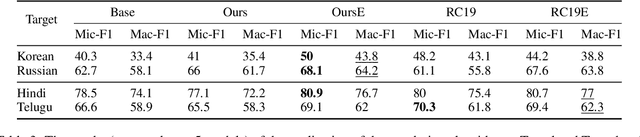

Despite the impressive growth of the abilities of multilingual language models, such as XLM-R and mT5, it has been shown that they still face difficulties when tackling typologically-distant languages, particularly in the low-resource setting. One obstacle for effective cross-lingual transfer is variability in word-order patterns. It can be potentially mitigated via source- or target-side word reordering, and numerous approaches to reordering have been proposed. However, they rely on language-specific rules, work on the level of POS tags, or only target the main clause, leaving subordinate clauses intact. To address these limitations, we present a new powerful reordering method, defined in terms of Universal Dependencies, that is able to learn fine-grained word-order patterns conditioned on the syntactic context from a small amount of annotated data and can be applied at all levels of the syntactic tree. We conduct experiments on a diverse set of tasks and show that our method consistently outperforms strong baselines over different language pairs and model architectures. This performance advantage holds true in both zero-shot and few-shot scenarios.
MuLER: Detailed and Scalable Reference-based Evaluation
May 24, 2023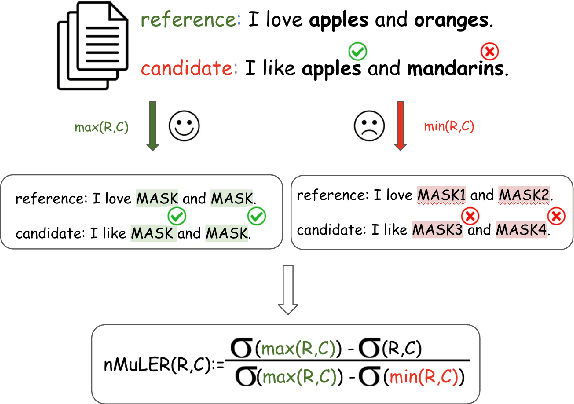
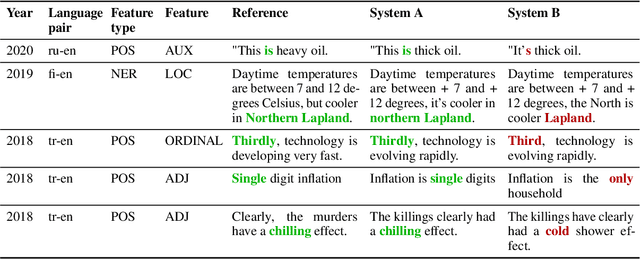
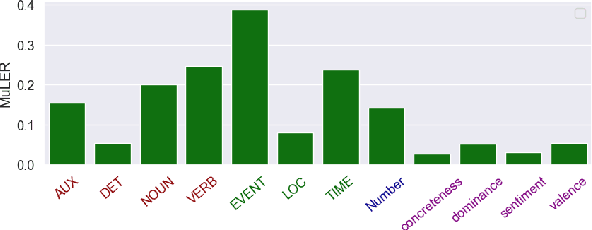
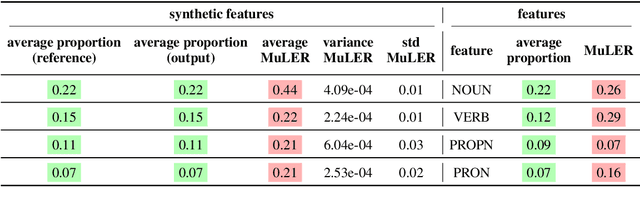
We propose a novel methodology (namely, MuLER) that transforms any reference-based evaluation metric for text generation, such as machine translation (MT) into a fine-grained analysis tool. Given a system and a metric, MuLER quantifies how much the chosen metric penalizes specific error types (e.g., errors in translating names of locations). MuLER thus enables a detailed error analysis which can lead to targeted improvement efforts for specific phenomena. We perform experiments in both synthetic and naturalistic settings to support MuLER's validity and showcase its usability in MT evaluation, and other tasks, such as summarization. Analyzing all submissions to WMT in 2014-2020, we find consistent trends. For example, nouns and verbs are among the most frequent POS tags. However, they are among the hardest to translate. Performance on most POS tags improves with overall system performance, but a few are not thus correlated (their identity changes from language to language). Preliminary experiments with summarization reveal similar trends.
Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
Mar 16, 2023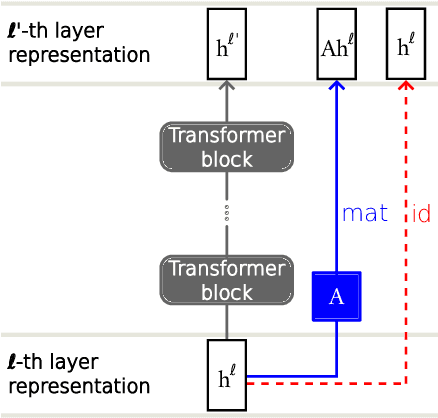

Transformer-based language models (LMs) create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, by using linear transformations. We show that our approach produces more accurate approximations than the prevailing practice of inspecting hidden representations from all layers in the space of the final layer. Moreover, in the context of language modeling, our method allows "peeking" into early layer representations of GPT-2 and BERT, showing that often LMs already predict the final output in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT, on top of the savings of the original approach. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change.
On the Relation between Syntactic Divergence and Zero-Shot Performance
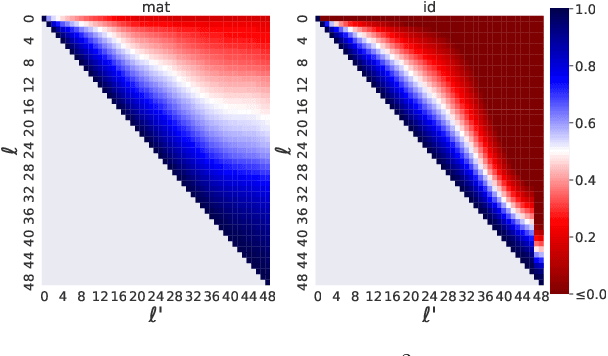
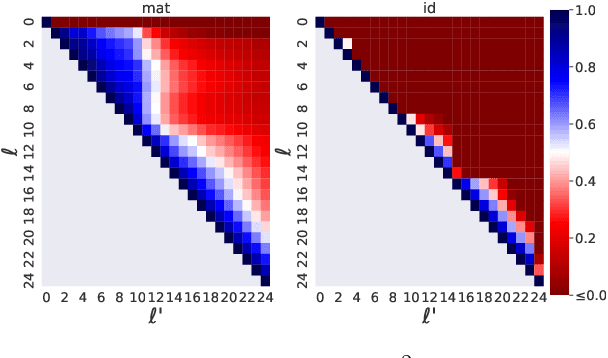
Oct 09, 2021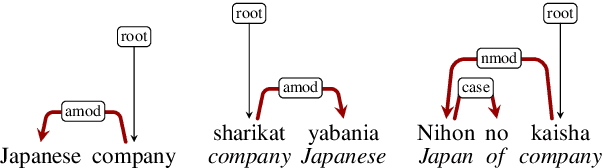
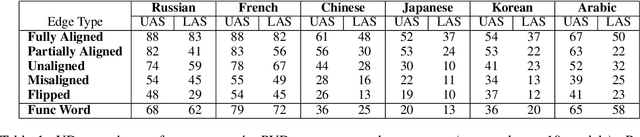

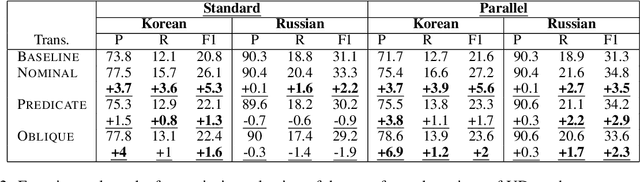
We explore the link between the extent to which syntactic relations are preserved in translation and the ease of correctly constructing a parse tree in a zero-shot setting. While previous work suggests such a relation, it tends to focus on the macro level and not on the level of individual edges-a gap we aim to address. As a test case, we take the transfer of Universal Dependencies (UD) parsing from English to a diverse set of languages and conduct two sets of experiments. In one, we analyze zero-shot performance based on the extent to which English source edges are preserved in translation. In another, we apply three linguistically motivated transformations to UD, creating more cross-lingually stable versions of it, and assess their zero-shot parsability. In order to compare parsing performance across different schemes, we perform extrinsic evaluation on the downstream task of cross-lingual relation extraction (RE) using a subset of a popular English RE benchmark translated to Russian and Korean. In both sets of experiments, our results suggest a strong relation between cross-lingual stability and zero-shot parsing performance.
Putting Words in BERT's Mouth: Navigating Contextualized Vector Spaces with Pseudowords
Oct 04, 2021



We present a method for exploring regions around individual points in a contextualized vector space (particularly, BERT space), as a way to investigate how these regions correspond to word senses. By inducing a contextualized "pseudoword" as a stand-in for a static embedding in the input layer, and then performing masked prediction of a word in the sentence, we are able to investigate the geometry of the BERT-space in a controlled manner around individual instances. Using our method on a set of carefully constructed sentences targeting ambiguous English words, we find substantial regularity in the contextualized space, with regions that correspond to distinct word senses; but between these regions there are occasionally "sense voids" -- regions that do not correspond to any intelligible sense.
Fine-Grained Analysis of Cross-Linguistic Syntactic Divergences
May 07, 2020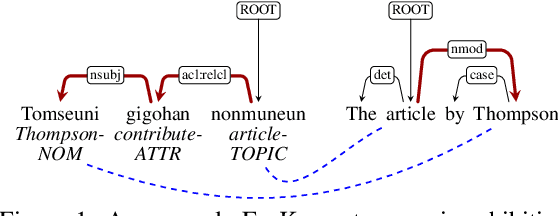
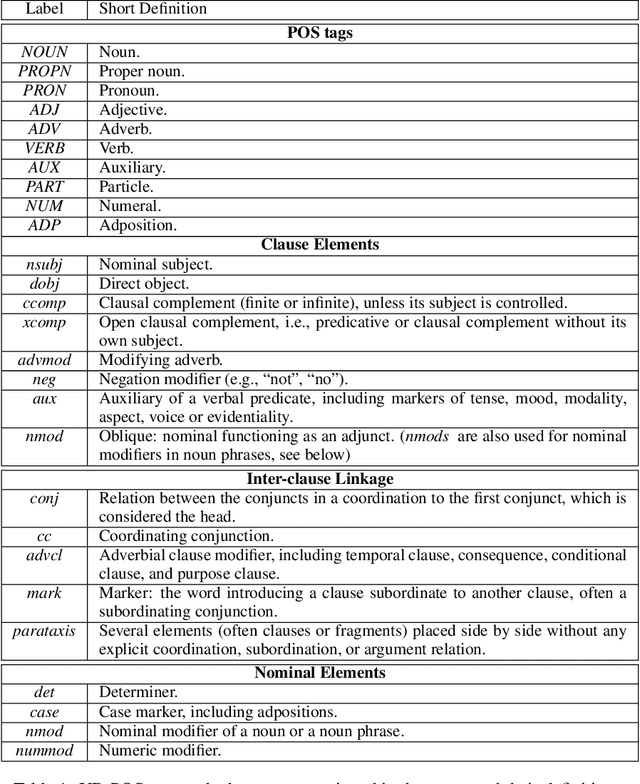
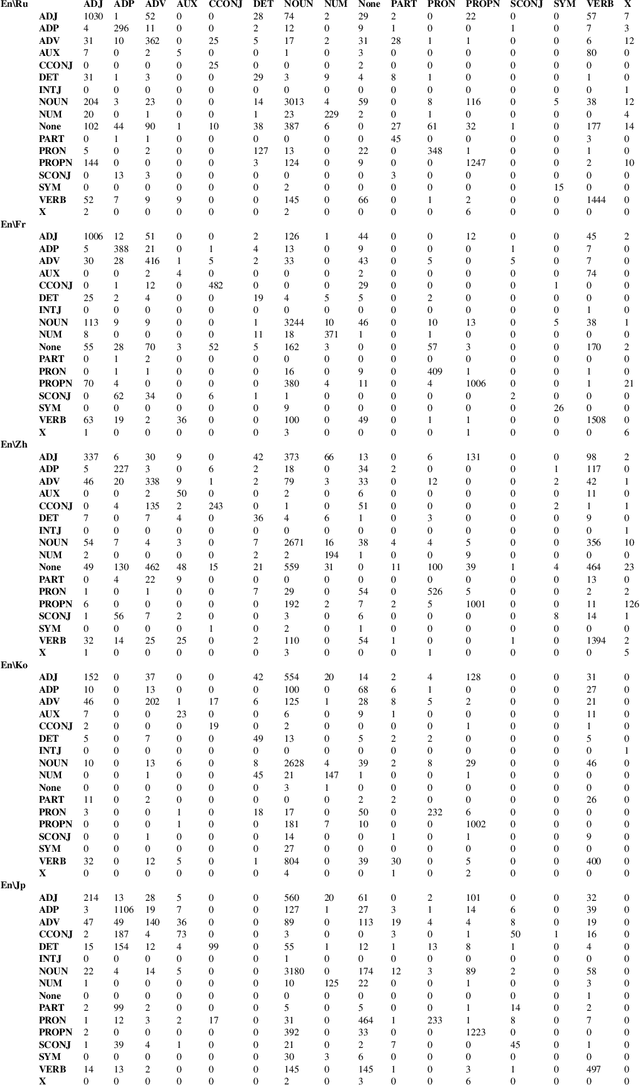
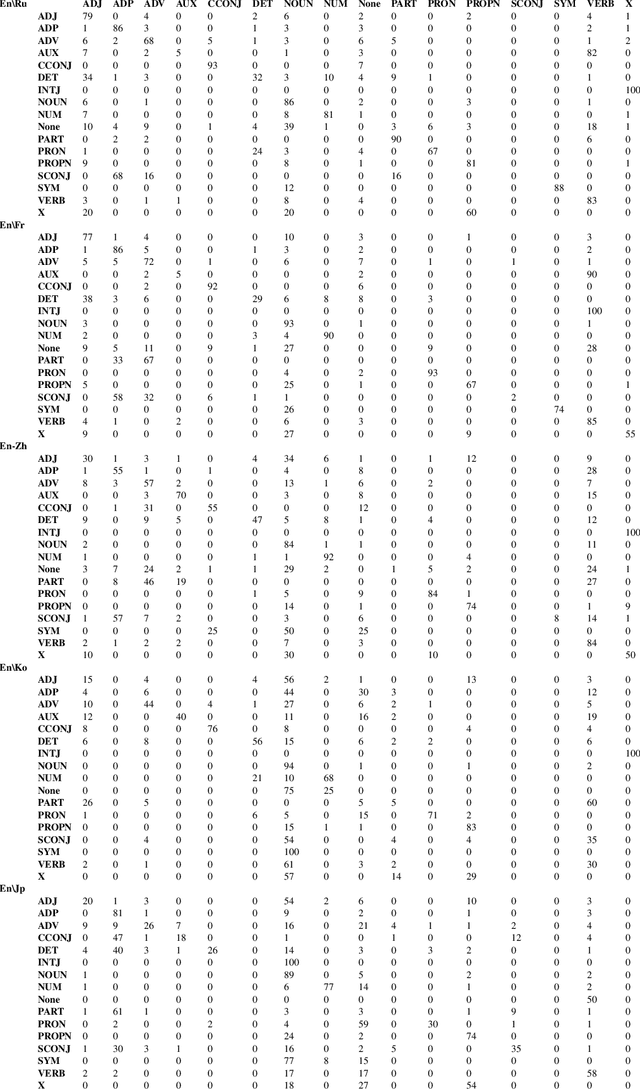
The patterns in which the syntax of different languages converges and diverges are often used to inform work on cross-lingual transfer. Nevertheless, little empirical work has been done on quantifying the prevalence of different syntactic divergences across language pairs. We propose a framework for extracting divergence patterns for any language pair from a parallel corpus, building on Universal Dependencies. We show that our framework provides a detailed picture of cross-language divergences, generalizes previous approaches, and lends itself to full automation. We further present a novel dataset, a manually word-aligned subset of the Parallel UD corpus in five languages, and use it to perform a detailed corpus study. We demonstrate the usefulness of the resulting analysis by showing that it can help account for performance patterns of a cross-lingual parser.