 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Analysis of Cross-Linguistic Syntactic Divergences
May 07, 2020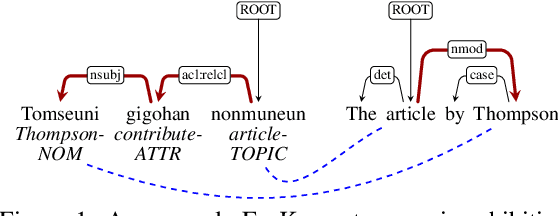
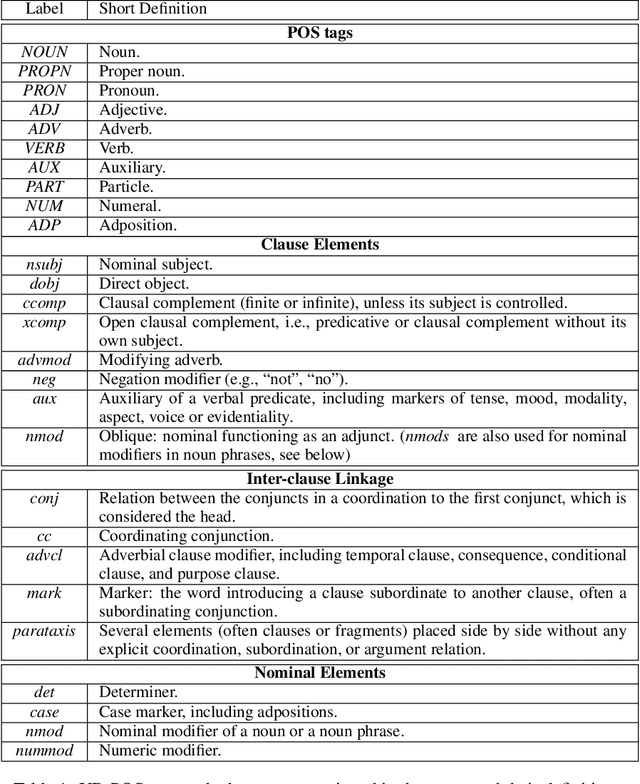
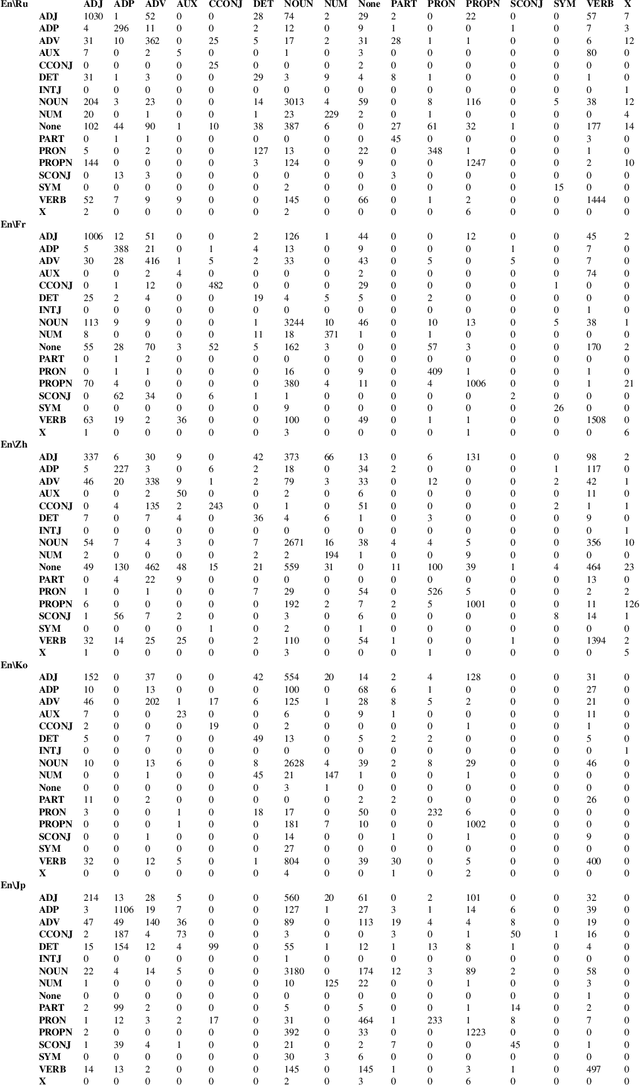
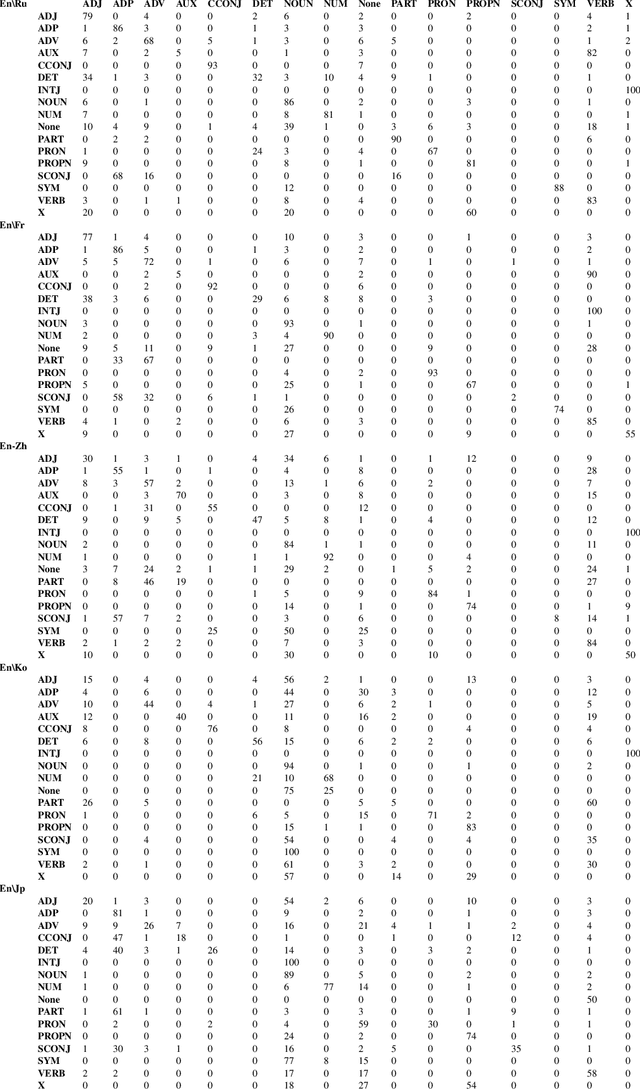
The patterns in which the syntax of different languages converges and diverges are often used to inform work on cross-lingual transfer. Nevertheless, little empirical work has been done on quantifying the prevalence of different syntactic divergences across language pairs. We propose a framework for extracting divergence patterns for any language pair from a parallel corpus, building on Universal Dependencies. We show that our framework provides a detailed picture of cross-language divergences, generalizes previous approaches, and lends itself to full automation. We further present a novel dataset, a manually word-aligned subset of the Parallel UD corpus in five languages, and use it to perform a detailed corpus study. We demonstrate the usefulness of the resulting analysis by showing that it can help account for performance patterns of a cross-lingual parser.