 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Is The Political Content in LLMs' Pre- and Post-Training Data?
Sep 26, 2025
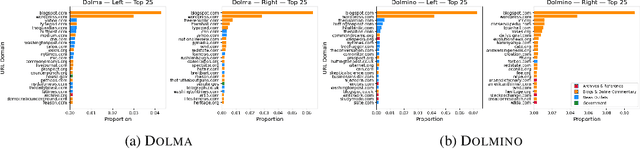


Large language models (LLMs) are known to generate politically biased text, yet how such biases arise remains unclear. A crucial step toward answering this question is the analysis of training data, whose political content remains largely underexplored in current LLM research. To address this gap, we present in this paper an analysis of the pre- and post-training corpora of OLMO2, the largest fully open-source model released together with its complete dataset. From these corpora, we draw large random samples, automatically annotate documents for political orientation, and analyze their source domains and content. We then assess how political content in the training data correlates with models' stance on specific policy issues. Our analysis shows that left-leaning documents predominate across datasets, with pre-training corpora containing significantly more politically engaged content than post-training data. We also find that left- and right-leaning documents frame similar topics through distinct values and sources of legitimacy. Finally, the predominant stance in the training data strongly correlates with models' political biases when evaluated on policy issues. These findings underscore the need to integrate political content analysis into future data curation pipelines as well as in-depth documentation of filtering strategies for transparency.
Strategies for political-statement segmentation and labelling in unstructured text
Mar 10, 2025
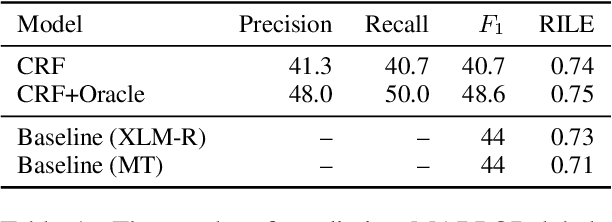
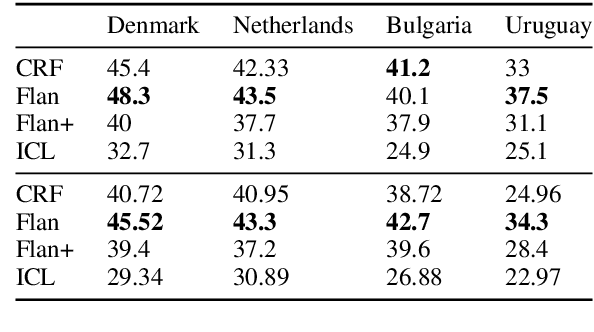
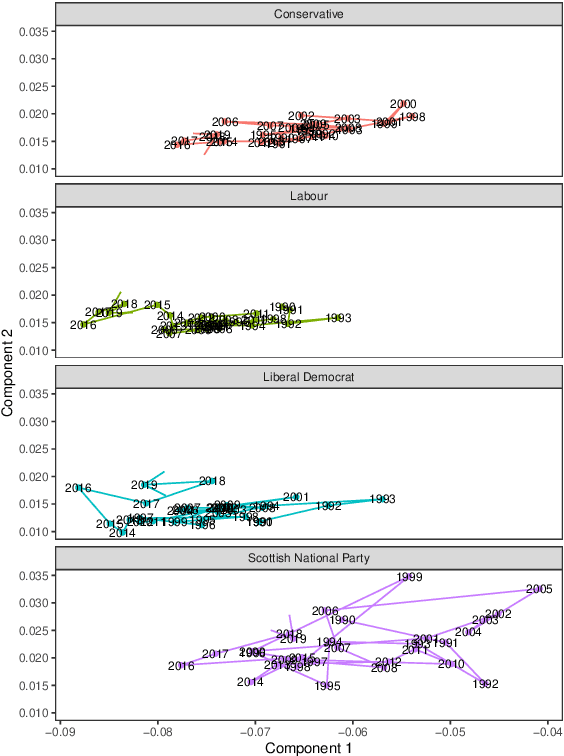
Analysis of parliamentary speeches and political-party manifestos has become an integral area of computational study of political texts. While speeches have been overwhelmingly analysed using unsupervised methods, a large corpus of manifestos with by-statement political-stance labels has been created by the participants of the MARPOR project. It has been recently shown that these labels can be predicted by a neural model; however, the current approach relies on provided statement boundaries, limiting out-of-domain applicability. In this work, we propose and test a range of unified split-and-label frameworks -- based on linear-chain CRFs, fine-tuned text-to-text models, and the combination of in-context learning with constrained decoding -- that can be used to jointly segment and classify statements from raw textual data. We show that our approaches achieve competitive accuracy when applied to raw text of political manifestos, and then demonstrate the research potential of our method by applying it to the records of the UK House of Commons and tracing the political trajectories of four major parties in the last three decades.
Generalization of Brady-Yong Algorithm for Fast Hough Transform to Arbitrary Image Size
Nov 11, 2024Nowadays, the Hough (discrete Radon) transform (HT/DRT) has proved to be an extremely powerful and widespread tool harnessed in a number of application areas, ranging from general image processing to X-ray computed tomography. Efficient utilization of the HT to solve applied problems demands its acceleration and increased accuracy. Along with this, most fast algorithms for computing the HT, especially the pioneering Brady-Yong algorithm, operate on power-of-two size input images and are not adapted for arbitrary size images. This paper presents a new algorithm for calculating the HT for images of arbitrary size. It generalizes the Brady-Yong algorithm from which it inherits the optimal computational complexity. Moreover, the algorithm allows to compute the HT with considerably higher accuracy compared to the existing algorithm. Herewith, the paper provides a theoretical analysis of the computational complexity and accuracy of the proposed algorithm. The conclusions of the performed experiments conform with the theoretical results.
Classifier identification in Ancient Egyptian as a low-resource sequence-labelling task
Jun 29, 2024
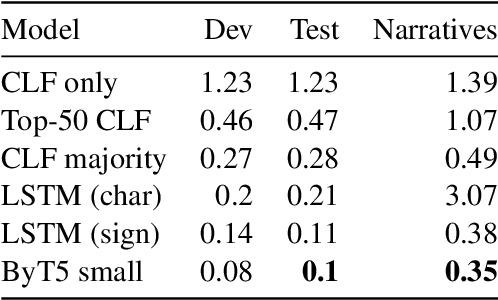

The complex Ancient Egyptian (AE) writing system was characterised by widespread use of graphemic classifiers (determinatives): silent (unpronounced) hieroglyphic signs clarifying the meaning or indicating the pronunciation of the host word. The study of classifiers has intensified in recent years with the launch and quick growth of the iClassifier project, a web-based platform for annotation and analysis of classifiers in ancient and modern languages. Thanks to the data contributed by the project participants, it is now possible to formulate the identification of classifiers in AE texts as an NLP task. In this paper, we make first steps towards solving this task by implementing a series of sequence-labelling neural models, which achieve promising performance despite the modest amount of training data. We discuss tokenisation and operationalisation issues arising from tackling AE texts and contrast our approach with frequency-based baselines.
Beyond prompt brittleness: Evaluating the reliability and consistency of political worldviews in LLMs
Feb 27, 2024Due to the widespread use of large language models (LLMs) in ubiquitous systems, we need to understand whether they embed a specific worldview and what these views reflect. Recent studies report that, prompted with political questionnaires, LLMs show left-liberal leanings. However, it is as yet unclear whether these leanings are reliable (robust to prompt variations) and whether the leaning is consistent across policies and political leaning. We propose a series of tests which assess the reliability and consistency of LLMs' stances on political statements based on a dataset of voting-advice questionnaires collected from seven EU countries and annotated for policy domains. We study LLMs ranging in size from 7B to 70B parameters and find that their reliability increases with parameter count. Larger models show overall stronger alignment with left-leaning parties but differ among policy programs: They evince a (left-wing) positive stance towards environment protection, social welfare but also (right-wing) law and order, with no consistent preferences in foreign policy, migration, and economy.
Approximate Attributions for Off-the-Shelf Siamese Transformers
Feb 05, 2024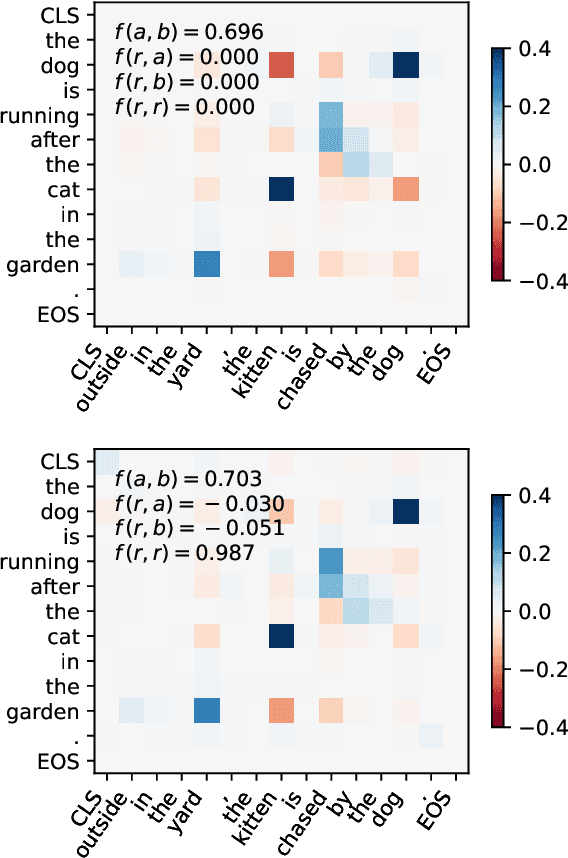
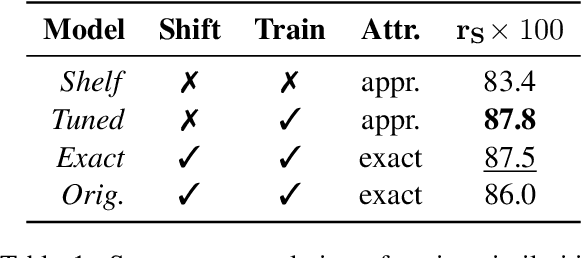
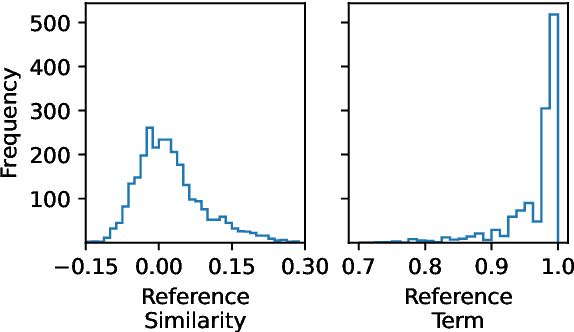

Siamese encoders such as sentence transformers are among the least understood deep models. Established attribution methods cannot tackle this model class since it compares two inputs rather than processing a single one. To address this gap, we have recently proposed an attribution method specifically for Siamese encoders (M\"oller et al., 2023). However, it requires models to be adjusted and fine-tuned and therefore cannot be directly applied to off-the-shelf models. In this work, we reassess these restrictions and propose (i) a model with exact attribution ability that retains the original model's predictive performance and (ii) a way to compute approximate attributions for off-the-shelf models. We extensively compare approximate and exact attributions and use them to analyze the models' attendance to different linguistic aspects. We gain insights into which syntactic roles Siamese transformers attend to, confirm that they mostly ignore negation, explore how they judge semantically opposite adjectives, and find that they exhibit lexical bias.
An Attribution Method for Siamese Encoders
Oct 23, 2023



Despite the success of Siamese encoder models such as sentence transformers (ST), little is known about the aspects of inputs they pay attention to. A barrier is that their predictions cannot be attributed to individual features, as they compare two inputs rather than processing a single one. This paper derives a local attribution method for Siamese encoders by generalizing the principle of integrated gradients to models with multiple inputs. The solution takes the form of feature-pair attributions, and can be reduced to a token-token matrix for STs. Our method involves the introduction of integrated Jacobians and inherits the advantageous formal properties of integrated gradients: it accounts for the model's full computation graph and is guaranteed to converge to the actual prediction. A pilot study shows that in an ST few token-pairs can often explain large fractions of predictions, and it focuses on nouns and verbs. For accurate predictions, it however needs to attend to the majority of tokens and parts of speech.
Improving Cross-Lingual Transfer through Subtree-Aware Word Reordering
Oct 20, 2023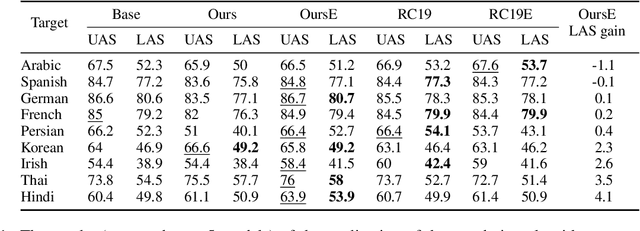
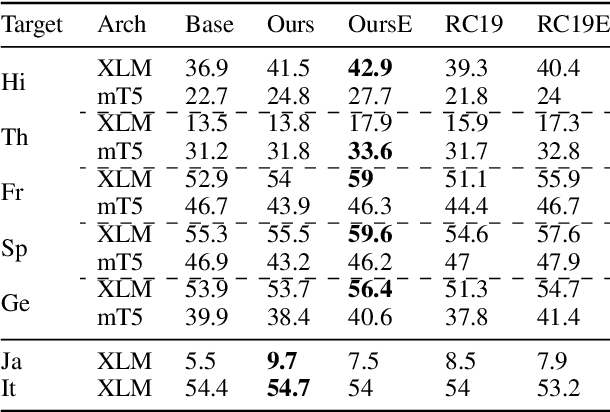

Despite the impressive growth of the abilities of multilingual language models, such as XLM-R and mT5, it has been shown that they still face difficulties when tackling typologically-distant languages, particularly in the low-resource setting. One obstacle for effective cross-lingual transfer is variability in word-order patterns. It can be potentially mitigated via source- or target-side word reordering, and numerous approaches to reordering have been proposed. However, they rely on language-specific rules, work on the level of POS tags, or only target the main clause, leaving subordinate clauses intact. To address these limitations, we present a new powerful reordering method, defined in terms of Universal Dependencies, that is able to learn fine-grained word-order patterns conditioned on the syntactic context from a small amount of annotated data and can be applied at all levels of the syntactic tree. We conduct experiments on a diverse set of tasks and show that our method consistently outperforms strong baselines over different language pairs and model architectures. This performance advantage holds true in both zero-shot and few-shot scenarios.
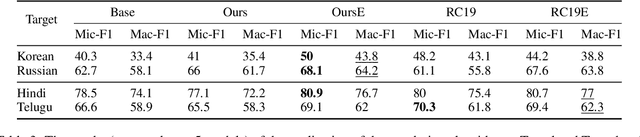
Multilingual estimation of political-party positioning: From label aggregation to long-input Transformers
Oct 19, 2023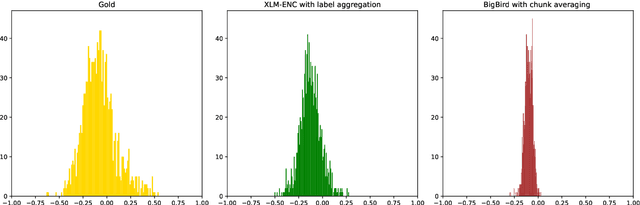
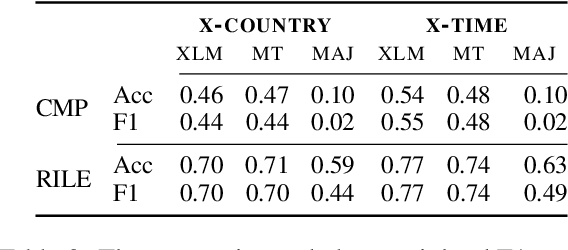
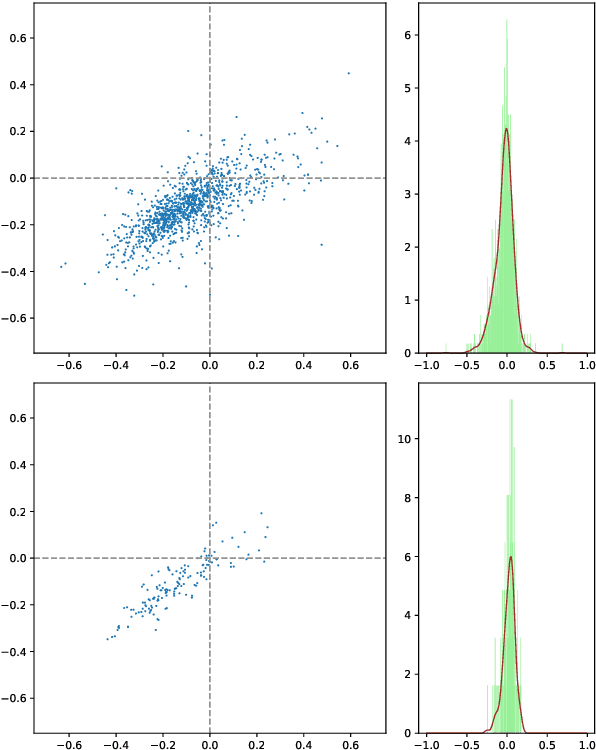
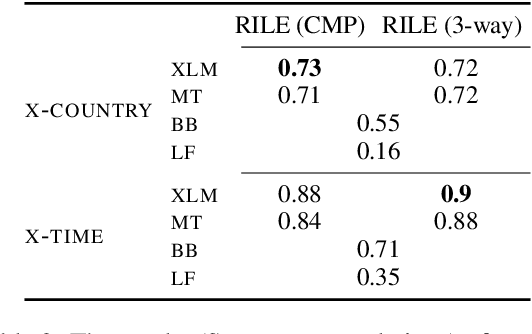
Scaling analysis is a technique in computational political science that assigns a political actor (e.g. politician or party) a score on a predefined scale based on a (typically long) body of text (e.g. a parliamentary speech or an election manifesto). For example, political scientists have often used the left--right scale to systematically analyse political landscapes of different countries. NLP methods for automatic scaling analysis can find broad application provided they (i) are able to deal with long texts and (ii) work robustly across domains and languages. In this work, we implement and compare two approaches to automatic scaling analysis of political-party manifestos: label aggregation, a pipeline strategy relying on annotations of individual statements from the manifestos, and long-input-Transformer-based models, which compute scaling values directly from raw text. We carry out the analysis of the Comparative Manifestos Project dataset across 41 countries and 27 languages and find that the task can be efficiently solved by state-of-the-art models, with label aggregation producing the best results.
Investigating semantic subspaces of Transformer sentence embeddings through linear structural probing
Oct 18, 2023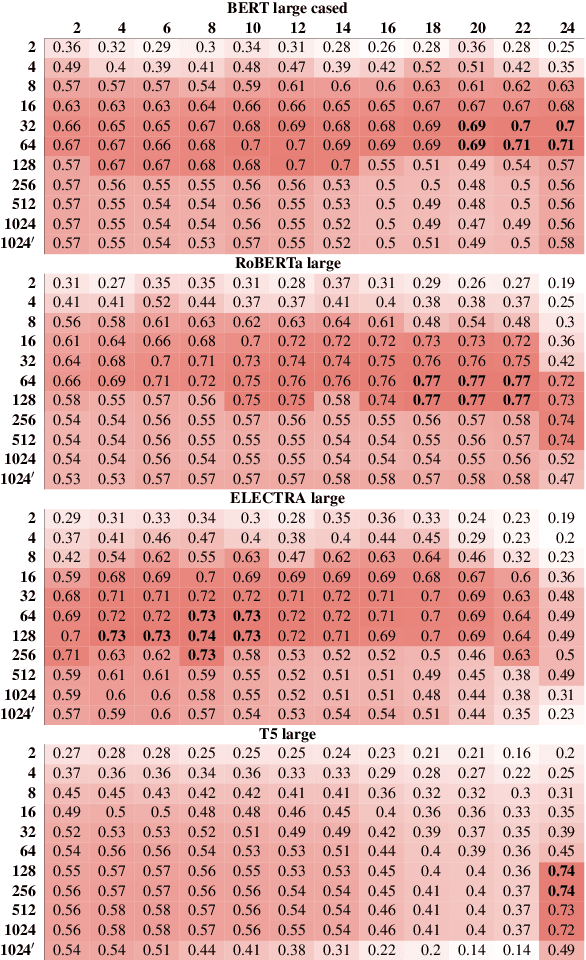
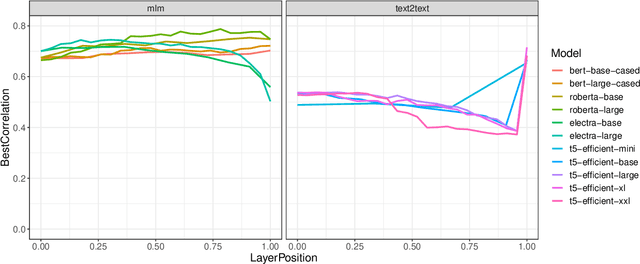

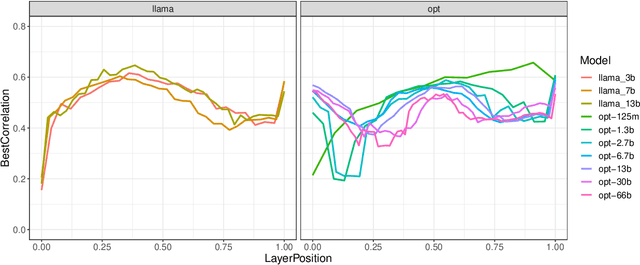
The question of what kinds of linguistic information are encoded in different layers of Transformer-based language models is of considerable interest for the NLP community. Existing work, however, has overwhelmingly focused on word-level representations and encoder-only language models with the masked-token training objective. In this paper, we present experiments with semantic structural probing, a method for studying sentence-level representations via finding a subspace of the embedding space that provides suitable task-specific pairwise distances between data-points. We apply our method to language models from different families (encoder-only, decoder-only, encoder-decoder) and of different sizes in the context of two tasks, semantic textual similarity and natural-language inference. We find that model families differ substantially in their performance and layer dynamics, but that the results are largely model-size invariant.