 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Humans as Brittle as Large Language Models?
Sep 09, 2025The output of large language models (LLM) is unstable, due to both non-determinism of the decoding process as well as to prompt brittleness. While the intrinsic non-determinism of LLM generation may mimic existing uncertainty in human annotations through distributional shifts in outputs, it is largely assumed, yet unexplored, that the prompt brittleness effect is unique to LLMs. This raises the question: do human annotators show similar sensitivity to instruction changes? If so, should prompt brittleness in LLMs be considered problematic? One may alternatively hypothesize that prompt brittleness correctly reflects human annotation variances. To fill this research gap, we systematically compare the effects of prompt modifications on LLMs and identical instruction modifications for human annotators, focusing on the question of whether humans are similarly sensitive to prompt perturbations. To study this, we prompt both humans and LLMs for a set of text classification tasks conditioned on prompt variations. Our findings indicate that both humans and LLMs exhibit increased brittleness in response to specific types of prompt modifications, particularly those involving the substitution of alternative label sets or label formats. However, the distribution of human judgments is less affected by typographical errors and reversed label order than that of LLMs.
Strategies for political-statement segmentation and labelling in unstructured text
Mar 10, 2025
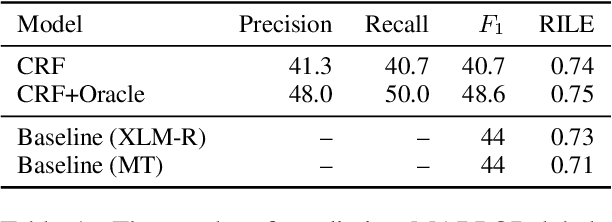
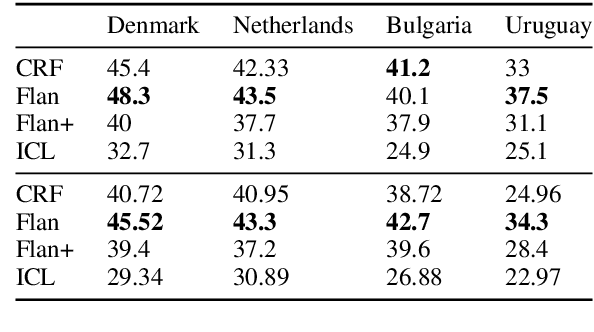
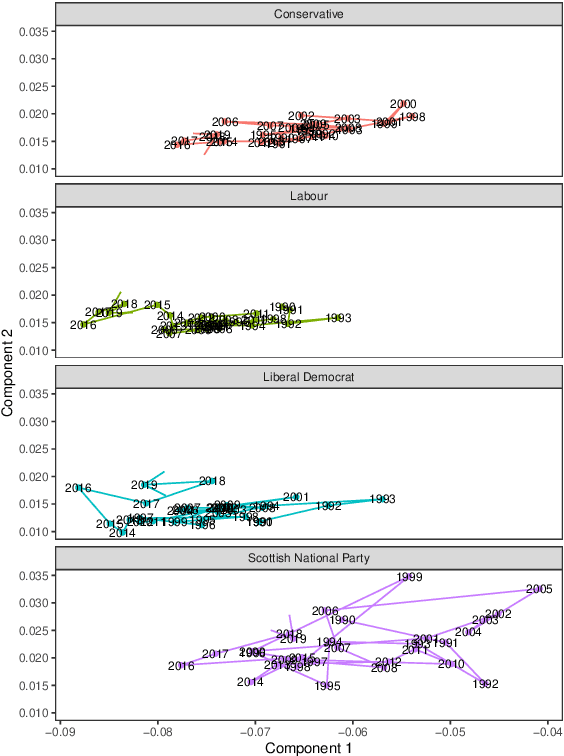
Analysis of parliamentary speeches and political-party manifestos has become an integral area of computational study of political texts. While speeches have been overwhelmingly analysed using unsupervised methods, a large corpus of manifestos with by-statement political-stance labels has been created by the participants of the MARPOR project. It has been recently shown that these labels can be predicted by a neural model; however, the current approach relies on provided statement boundaries, limiting out-of-domain applicability. In this work, we propose and test a range of unified split-and-label frameworks -- based on linear-chain CRFs, fine-tuned text-to-text models, and the combination of in-context learning with constrained decoding -- that can be used to jointly segment and classify statements from raw textual data. We show that our approaches achieve competitive accuracy when applied to raw text of political manifestos, and then demonstrate the research potential of our method by applying it to the records of the UK House of Commons and tracing the political trajectories of four major parties in the last three decades.
Regular-pattern-sensitive CRFs for Distant Label Interactions
Nov 19, 2024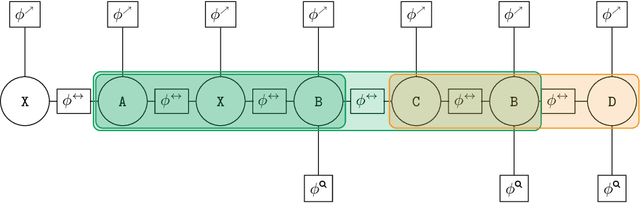

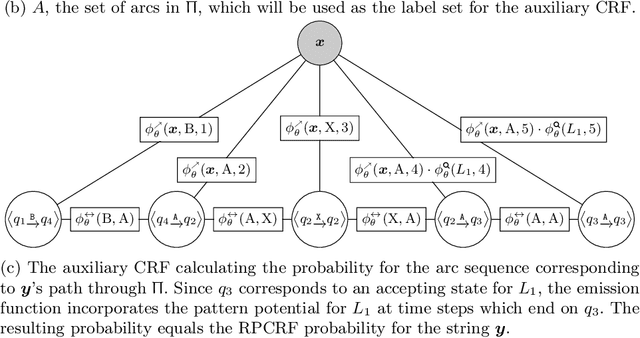

Linear-chain conditional random fields (CRFs) are a common model component for sequence labeling tasks when modeling the interactions between different labels is important. However, the Markov assumption limits linear-chain CRFs to only directly modeling interactions between adjacent labels. Weighted finite-state transducers (FSTs) are a related approach which can be made to model distant label-label interactions, but exact label inference is intractable for these models in the general case, and the task of selecting an appropriate automaton structure for the desired interaction types poses a practical challenge. In this work, we present regular-pattern-sensitive CRFs (RPCRFs), a method of enriching standard linear-chain CRFs with the ability to learn long-distance label interactions which occur in user-specified patterns. This approach allows users to write regular-expression label patterns concisely specifying which types of interactions the model should take into account, allowing the model to learn from data whether and in which contexts these patterns occur. The result can be interpreted alternatively as a CRF augmented with additional, non-local potentials, or as a finite-state transducer whose structure is defined by a set of easily-interpretable patterns. Critically, unlike the general case for FSTs (and for non-chain CRFs), exact training and inference are tractable for many pattern sets. In this work, we detail how a RPCRF can be automatically constructed from a set of user-specified patterns, and demonstrate the model's effectiveness on synthetic data, showing how different types of patterns can capture different nonlocal dependency structures in label sequences.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

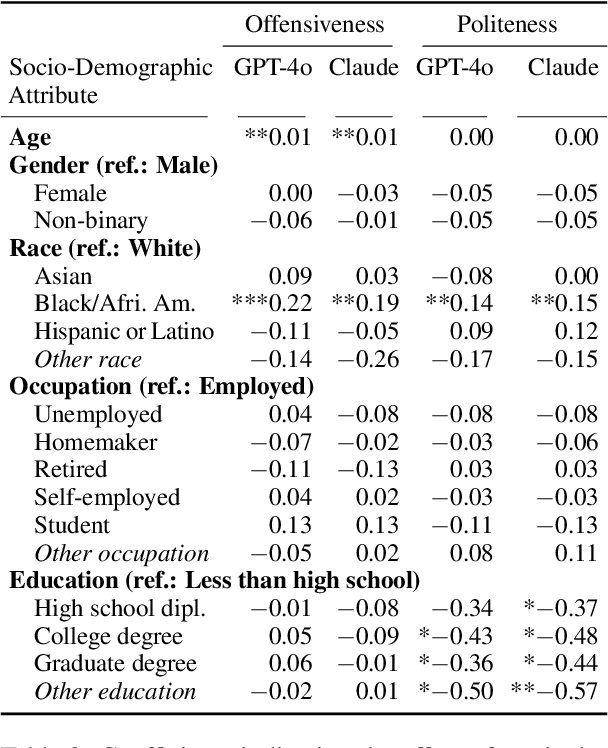
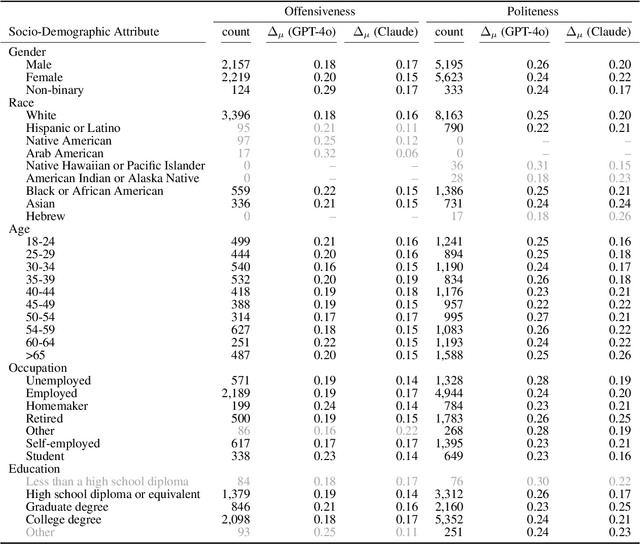
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
Actor Identification in Discourse: A Challenge for LLMs?
Feb 01, 2024The identification of political actors who put forward claims in public debate is a crucial step in the construction of discourse networks, which are helpful to analyze societal debates. Actor identification is, however, rather challenging: Often, the locally mentioned speaker of a claim is only a pronoun ("He proposed that [claim]"), so recovering the canonical actor name requires discourse understanding. We compare a traditional pipeline of dedicated NLP components (similar to those applied to the related task of coreference) with a LLM, which appears a good match for this generation task. Evaluating on a corpus of German actors in newspaper reports, we find surprisingly that the LLM performs worse. Further analysis reveals that the LLM is very good at identifying the right reference, but struggles to generate the correct canonical form. This points to an underlying issue in LLMs with controlling generated output. Indeed, a hybrid model combining the LLM with a classifier to normalize its output substantially outperforms both initial models.
Constraining Linear-chain CRFs to Regular Languages
Jun 15, 2021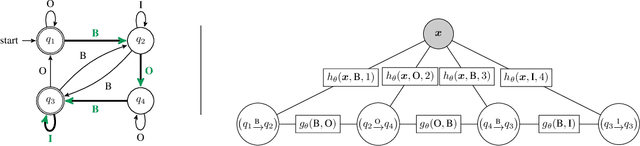



In structured prediction, a major challenge for models is to represent the interdependencies within their output structures. For the common case where outputs are structured as a sequence, linear-chain conditional random fields (CRFs) are a widely used model class which can learn local dependencies in output sequences. However, the CRF's Markov assumption makes it impossible for these models to capture nonlocal dependencies, and standard CRFs are unable to respect nonlocal constraints of the data (such as global arity constraints on output labels). We present a generalization of CRFs that can enforce a broad class of constraints, including nonlocal ones, by specifying the space of possible output structures as a regular language $\mathcal{L}$. The resulting regular-constrained CRF (RegCCRF) has the same formal properties as a standard CRF, but assigns zero probability to all label sequences not in $\mathcal{L}$. Notably, RegCCRFs can incorporate their constraints during training, while related models only enforce constraints during decoding. We prove that constrained training is never worse than constrained decoding, and show using synthetic data that it can be substantially better in practice. Additionally, we demonstrate a practical benefit on downstream tasks by incorporating a RegCCRF into a deep neural model for semantic role labeling, exceeding state-of-the-art results on a standard dataset.
Dissecting Span Identification Tasks with Performance Prediction
Oct 06, 2020



Span identification (in short, span ID) tasks such as chunking, NER, or code-switching detection, ask models to identify and classify relevant spans in a text. Despite being a staple of NLP, and sharing a common structure, there is little insight on how these tasks' properties influence their difficulty, and thus little guidance on what model families work well on span ID tasks, and why. We analyze span ID tasks via performance prediction, estimating how well neural architectures do on different tasks. Our contributions are: (a) we identify key properties of span ID tasks that can inform performance prediction; (b) we carry out a large-scale experiment on English data, building a model to predict performance for unseen span ID tasks that can support architecture choices; (c), we investigate the parameters of the meta model, yielding new insights on how model and task properties interact to affect span ID performance. We find, e.g., that span frequency is especially important for LSTMs, and that CRFs help when spans are infrequent and boundaries non-distinctive.
IMS at SemEval-2020 Task 1: How low can you go? Dimensionality in Lexical Semantic Change Detection
Aug 07, 2020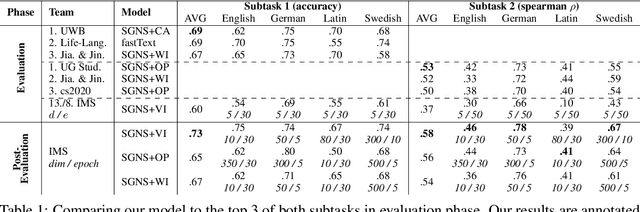
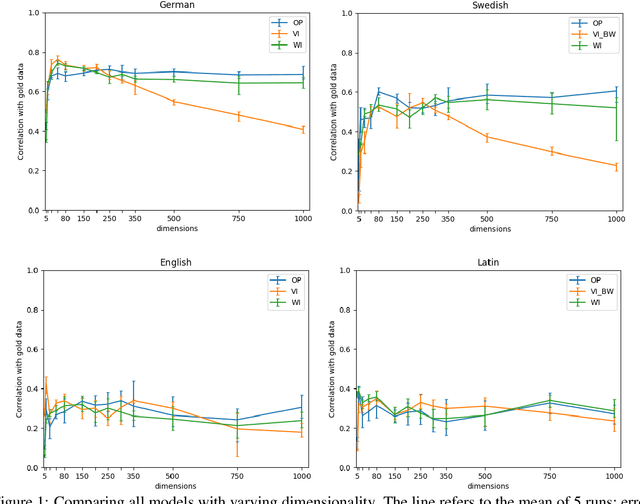
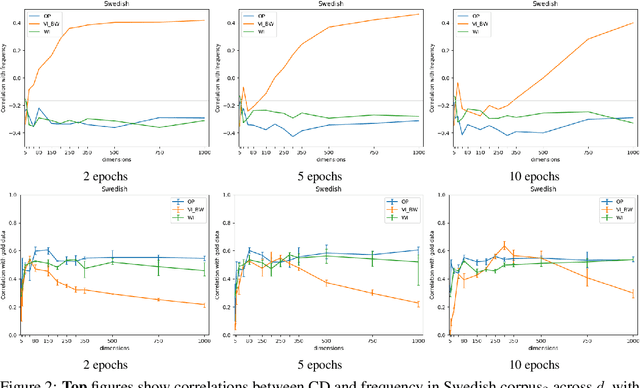

We present the results of our system for SemEval-2020 Task 1 that exploits a commonly used lexical semantic change detection model based on Skip-Gram with Negative Sampling. Our system focuses on Vector Initialization (VI) alignment, compares VI to the currently top-ranking models for Subtask 2 and demonstrates that these can be outperformed if we optimize VI dimensionality. We demonstrate that differences in performance can largely be attributed to model-specific sources of noise, and we reveal a strong relationship between dimensionality and frequency-induced noise in VI alignment. Our results suggest that lexical semantic change models integrating vector space alignment should pay more attention to the role of the dimensionality parameter.