 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Demographics do LLMs Default to During Annotation?
Oct 11, 2024

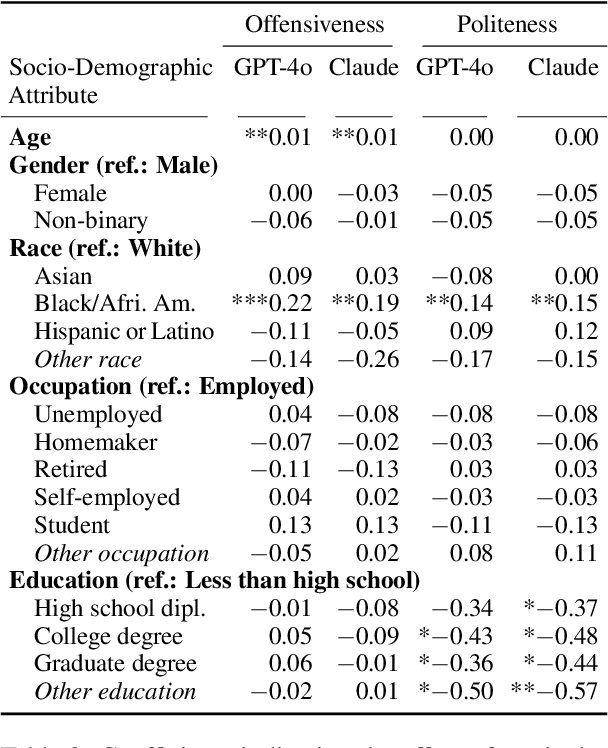
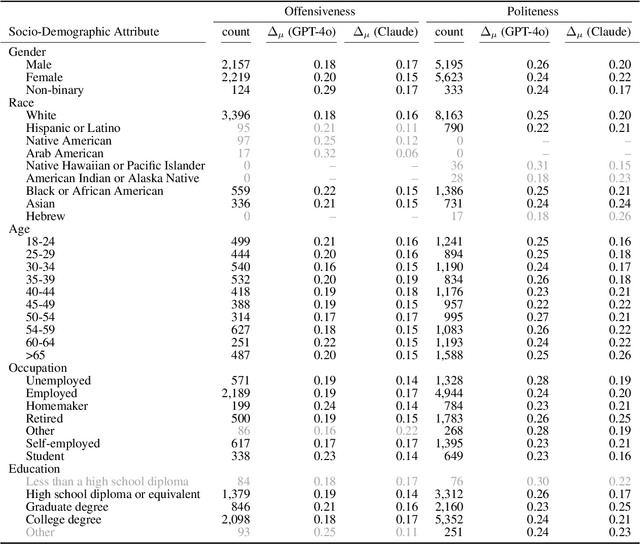
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
Autism Detection in Speech -- A Survey
Feb 20, 2024There has been a range of studies of how autism is displayed in voice, speech, and language. We analyse studies from the biomedical, as well as the psychological domain, but also from the NLP domain in order to find linguistic, prosodic and acoustic cues that could indicate autism. Our survey looks at all three domains. We define autism and which comorbidities might influence the correct detection of the disorder. We especially look at observations such as verbal and semantic fluency, prosodic features, but also disfluencies and speaking rate. We also show word-based approaches and describe machine learning and transformer-based approaches both on the audio data as well as the transcripts. Lastly, we conclude, while there already is a lot of research, female patients seem to be severely under-researched. Also, most NLP research focuses on traditional machine learning methods instead of transformers which could be beneficial in this context. Additionally, we were unable to find research combining both features from audio and transcripts.