 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Emotions or Appraisals - Which Emotion Model Explains Argument Convincingness Better?
Nov 18, 2025The convincingness of an argument does not only depend on its structure (logos), the person who makes the argument (ethos), but also on the emotion that it causes in the recipient (pathos). While the overall intensity and categorical values of emotions in arguments have received considerable attention in the research community, we argue that the emotion an argument evokes in a recipient is subjective. It depends on the recipient's goals, standards, prior knowledge, and stance. Appraisal theories lend themselves as a link between the subjective cognitive assessment of events and emotions. They have been used in event-centric emotion analysis, but their suitability for assessing argument convincingness remains unexplored. In this paper, we evaluate whether appraisal theories are suitable for emotion analysis in arguments by considering subjective cognitive evaluations of the importance and impact of an argument on its receiver. Based on the annotations in the recently published ContArgA corpus, we perform zero-shot prompting experiments to evaluate the importance of gold-annotated and predicted emotions and appraisals for the assessment of the subjective convincingness labels. We find that, while categorical emotion information does improve convincingness prediction, the improvement is more pronounced with appraisals. This work presents the first systematic comparison between emotion models for convincingness prediction, demonstrating the advantage of appraisals, providing insights for theoretical and practical applications in computational argumentation.
Feeling Machines: Ethics, Culture, and the Rise of Emotional AI
Jun 14, 2025This paper explores the growing presence of emotionally responsive artificial intelligence through a critical and interdisciplinary lens. Bringing together the voices of early-career researchers from multiple fields, it explores how AI systems that simulate or interpret human emotions are reshaping our interactions in areas such as education, healthcare, mental health, caregiving, and digital life. The analysis is structured around four central themes: the ethical implications of emotional AI, the cultural dynamics of human-machine interaction, the risks and opportunities for vulnerable populations, and the emerging regulatory, design, and technical considerations. The authors highlight the potential of affective AI to support mental well-being, enhance learning, and reduce loneliness, as well as the risks of emotional manipulation, over-reliance, misrepresentation, and cultural bias. Key challenges include simulating empathy without genuine understanding, encoding dominant sociocultural norms into AI systems, and insufficient safeguards for individuals in sensitive or high-risk contexts. Special attention is given to children, elderly users, and individuals with mental health challenges, who may interact with AI in emotionally significant ways. However, there remains a lack of cognitive or legal protections which are necessary to navigate such engagements safely. The report concludes with ten recommendations, including the need for transparency, certification frameworks, region-specific fine-tuning, human oversight, and longitudinal research. A curated supplementary section provides practical tools, models, and datasets to support further work in this domain.
Fearful Falcons and Angry Llamas: Emotion Category Annotations of Arguments by Humans and LLMs
Dec 20, 2024Arguments evoke emotions, influencing the effect of the argument itself. Not only the emotional intensity but also the category influence the argument's effects, for instance, the willingness to adapt stances. While binary emotionality has been studied in arguments, there is no work on discrete emotion categories (e.g., "Anger") in such data. To fill this gap, we crowdsource subjective annotations of emotion categories in a German argument corpus and evaluate automatic LLM-based labeling methods. Specifically, we compare three prompting strategies (zero-shot, one-shot, chain-of-thought) on three large instruction-tuned language models (Falcon-7b-instruct, Llama-3.1-8B-instruct, GPT-4o-mini). We further vary the definition of the output space to be binary (is there emotionality in the argument?), closed-domain (which emotion from a given label set is in the argument?), or open-domain (which emotion is in the argument?). We find that emotion categories enhance the prediction of emotionality in arguments, emphasizing the need for discrete emotion annotations in arguments. Across all prompt settings and models, automatic predictions show a high recall but low precision for predicting anger and fear, indicating a strong bias toward negative emotions.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

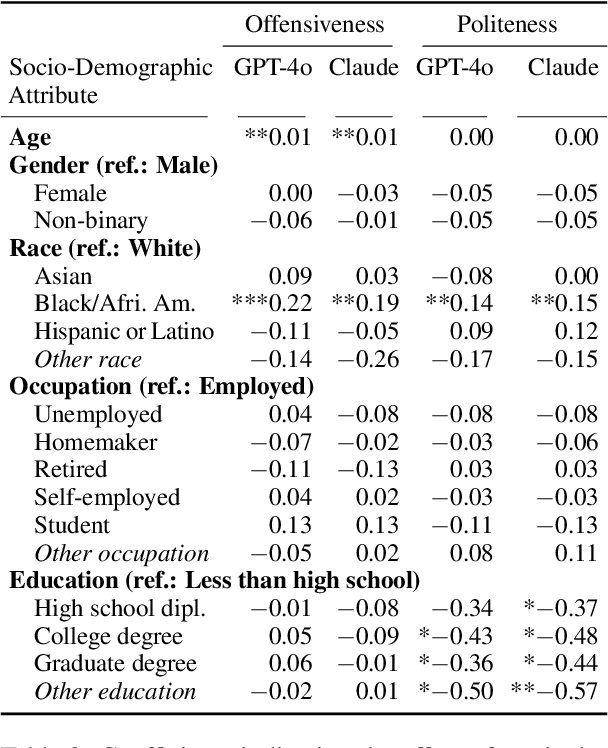
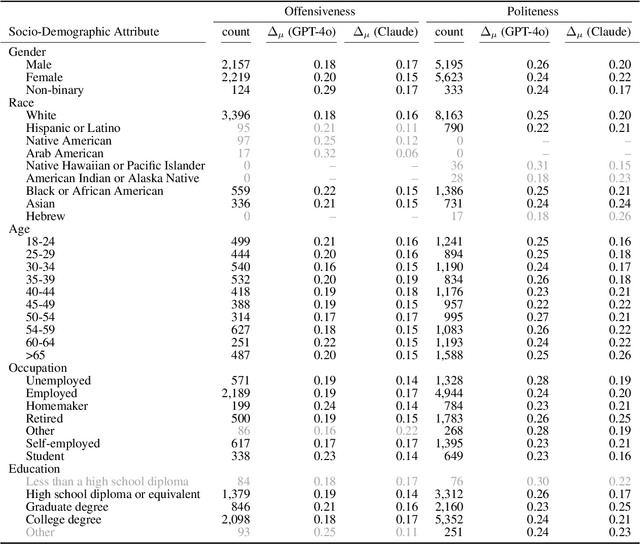
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.