 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCategorical Emotions or Appraisals - Which Emotion Model Explains Argument Convincingness Better?
Nov 18, 2025The convincingness of an argument does not only depend on its structure (logos), the person who makes the argument (ethos), but also on the emotion that it causes in the recipient (pathos). While the overall intensity and categorical values of emotions in arguments have received considerable attention in the research community, we argue that the emotion an argument evokes in a recipient is subjective. It depends on the recipient's goals, standards, prior knowledge, and stance. Appraisal theories lend themselves as a link between the subjective cognitive assessment of events and emotions. They have been used in event-centric emotion analysis, but their suitability for assessing argument convincingness remains unexplored. In this paper, we evaluate whether appraisal theories are suitable for emotion analysis in arguments by considering subjective cognitive evaluations of the importance and impact of an argument on its receiver. Based on the annotations in the recently published ContArgA corpus, we perform zero-shot prompting experiments to evaluate the importance of gold-annotated and predicted emotions and appraisals for the assessment of the subjective convincingness labels. We find that, while categorical emotion information does improve convincingness prediction, the improvement is more pronounced with appraisals. This work presents the first systematic comparison between emotion models for convincingness prediction, demonstrating the advantage of appraisals, providing insights for theoretical and practical applications in computational argumentation.
Which Demographics do LLMs Default to During Annotation?
Oct 11, 2024

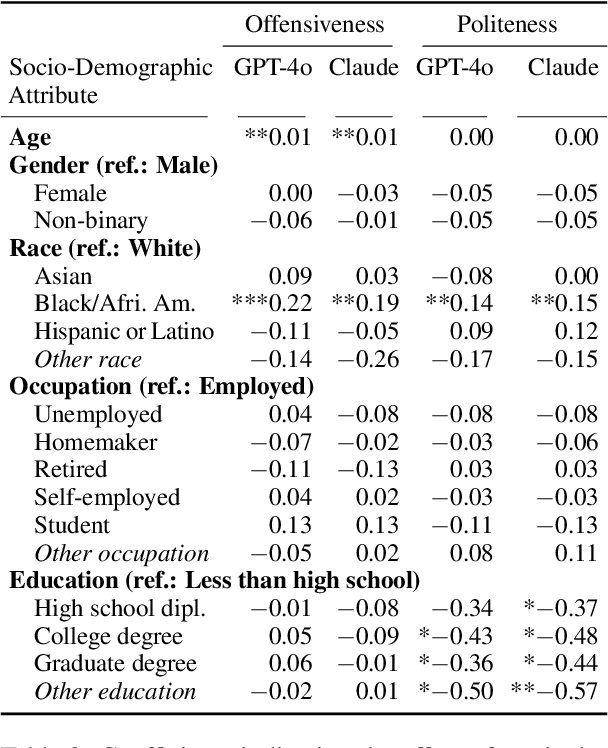
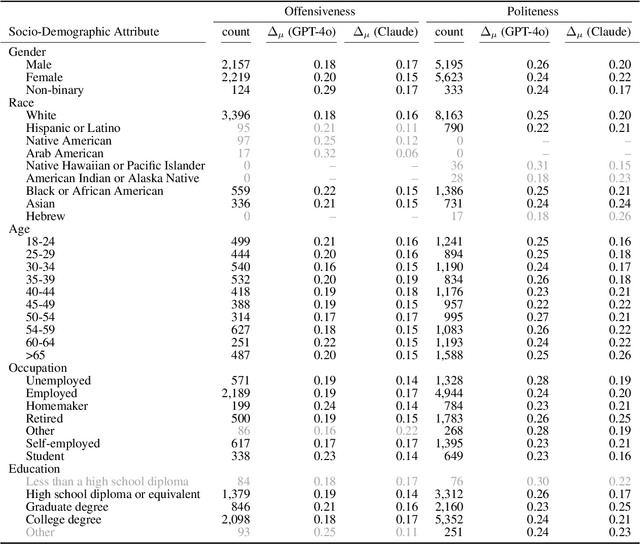
Demographics and cultural background of annotators influence the labels they assign in text annotation -- for instance, an elderly woman might find it offensive to read a message addressed to a "bro", but a male teenager might find it appropriate. It is therefore important to acknowledge label variations to not under-represent members of a society. Two research directions developed out of this observation in the context of using large language models (LLM) for data annotations, namely (1) studying biases and inherent knowledge of LLMs and (2) injecting diversity in the output by manipulating the prompt with demographic information. We combine these two strands of research and ask the question to which demographics an LLM resorts to when no demographics is given. To answer this question, we evaluate which attributes of human annotators LLMs inherently mimic. Furthermore, we compare non-demographic conditioned prompts and placebo-conditioned prompts (e.g., "you are an annotator who lives in house number 5") to demographics-conditioned prompts ("You are a 45 year old man and an expert on politeness annotation. How do you rate {instance}"). We study these questions for politeness and offensiveness annotations on the POPQUORN data set, a corpus created in a controlled manner to investigate human label variations based on demographics which has not been used for LLM-based analyses so far. We observe notable influences related to gender, race, and age in demographic prompting, which contrasts with previous studies that found no such effects.
Language Models Are Poor Learners of Directional Inference
Oct 10, 2022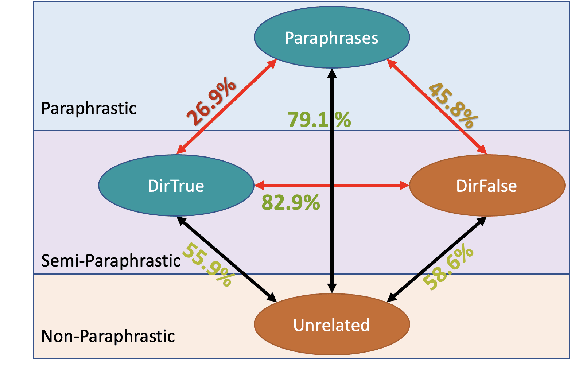
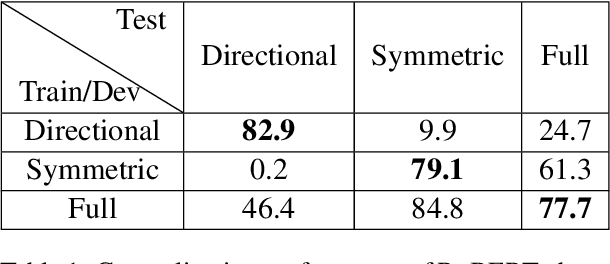
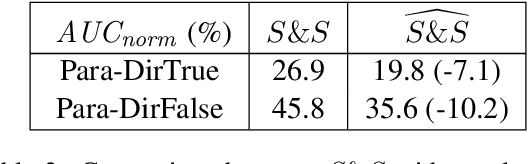
We examine LMs' competence of directional predicate entailments by supervised fine-tuning with prompts. Our analysis shows that contrary to their apparent success on standard NLI, LMs show limited ability to learn such directional inference; moreover, existing datasets fail to test directionality, and/or are infested by artefacts that can be learnt as proxy for entailments, yielding over-optimistic results. In response, we present BoOQA (Boolean Open QA), a robust multi-lingual evaluation benchmark for directional predicate entailments, extrinsic to existing training sets. On BoOQA, we establish baselines and show evidence of existing LM-prompting models being incompetent directional entailment learners, in contrast to entailment graphs, however limited by sparsity.
Cross-lingual Inference with A Chinese Entailment Graph
Mar 11, 2022
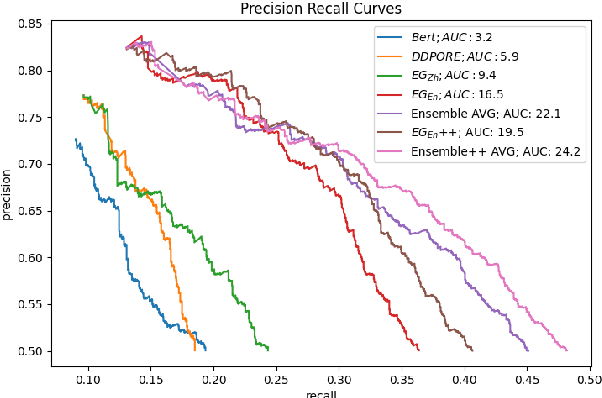
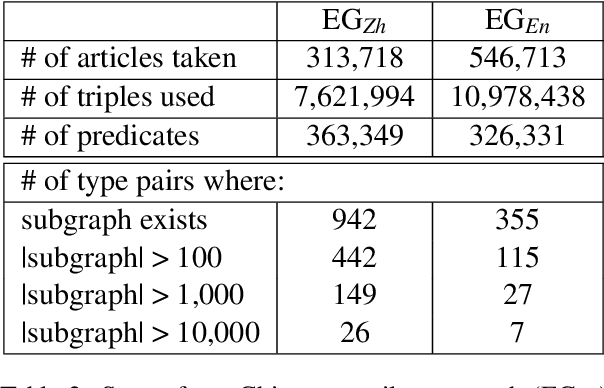
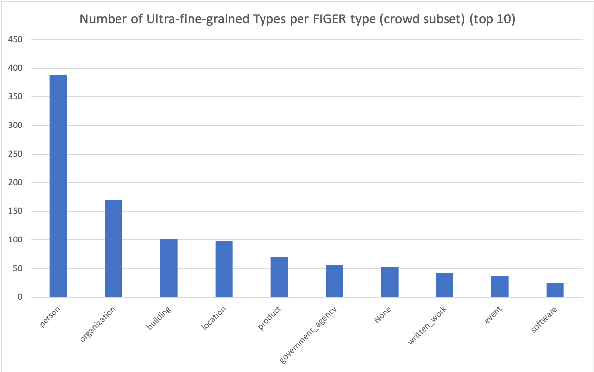
Predicate entailment detection is a crucial task for question-answering from text, where previous work has explored unsupervised learning of entailment graphs from typed open relation triples. In this paper, we present the first pipeline for building Chinese entailment graphs, which involves a novel high-recall open relation extraction (ORE) method and the first Chinese fine-grained entity typing dataset under the FIGER type ontology. Through experiments on the Levy-Holt dataset, we verify the strength of our Chinese entailment graph, and reveal the cross-lingual complementarity: on the parallel Levy-Holt dataset, an ensemble of Chinese and English entailment graphs outperforms both monolingual graphs, and raises unsupervised SOTA by 4.7 AUC points.