 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Video Distillation: Mitigating Oversaturation and Temporal Collapse in Few-Step Generation
Mar 23, 2026Video generation has recently emerged as a central task in the field of generative AI. However, the substantial computational cost inherent in video synthesis makes model distillation a critical technique for efficient deployment. Despite its significance, there is a scarcity of methods specifically designed for video diffusion models. Prevailing approaches often directly adapt image distillation techniques, which frequently lead to artifacts such as oversaturation, temporal inconsistency, and mode collapse. To address these challenges, we propose a novel distillation framework tailored specifically for video diffusion models. Its core innovations include: (1) an adaptive regression loss that dynamically adjusts spatial supervision weights to prevent artifacts arising from excessive distribution shifts; (2) a temporal regularization loss to counteract temporal collapse, promoting smooth and physically plausible sampling trajectories; and (3) an inference-time frame interpolation strategy that reduces sampling overhead while preserving perceptual quality. Extensive experiments and ablation studies on the VBench and VBench2 benchmarks demonstrate that our method achieves stable few-step video synthesis, significantly enhancing perceptual fidelity and motion realism. It consistently outperforms existing distillation baselines across multiple metrics.
Path-Decoupled Hyperbolic Flow Matching for Few-Shot Adaptation
Feb 24, 2026Recent advances in cross-modal few-shot adaptation treat visual-semantic alignment as a continuous feature transport problem via Flow Matching (FM). However, we argue that Euclidean-based FM overlooks fundamental limitations of flat geometry, where polynomial volume growth fails to accommodate diverse feature distributions, leading to severe path entanglement. To this end, we propose path-decoupled Hyperbolic Flow Matching (HFM), leveraging the Lorentz manifold's exponential expansion for trajectory decoupling. HFM structures the transport via two key designs: 1) Centripetal hyperbolic alignment: It constructs a centripetal hierarchy by anchoring textual roots, which pushes visual leaves to the boundary to initialize orderly flows. 2) Path-decoupled objective: It acts as a ``semantic guardrail'' rigidly confining trajectories within isolated class-specific geodesic corridors via step-wise supervision. Furthermore, we devise an adaptive diameter-based stopping to prevent over-transportation into the crowded origin based on the intrinsic semantic scale. Extensive ablations on 11 benchmarks have shown that HFM establishes a new state-of-the-art, consistently outperforming its Euclidean counterparts. Our codes and models will be released.
$\text{H}^2$em: Learning Hierarchical Hyperbolic Embeddings for Compositional Zero-Shot Learning
Dec 23, 2025Compositional zero-shot learning (CZSL) aims to recognize unseen state-object compositions by generalizing from a training set of their primitives (state and object). Current methods often overlook the rich hierarchical structures, such as the semantic hierarchy of primitives (e.g., apple fruit) and the conceptual hierarchy between primitives and compositions (e.g, sliced apple apple). A few recent efforts have shown effectiveness in modeling these hierarchies through loss regularization within Euclidean space. In this paper, we argue that they fail to scale to the large-scale taxonomies required for real-world CZSL: the space's polynomial volume growth in flat geometry cannot match the exponential structure, impairing generalization capacity. To this end, we propose H2em, a new framework that learns Hierarchical Hyperbolic EMbeddings for CZSL. H2em leverages the unique properties of hyperbolic geometry, a space naturally suited for embedding tree-like structures with low distortion. However, a naive hyperbolic mapping may suffer from hierarchical collapse and poor fine-grained discrimination. We further design two learning objectives to structure this space: a Dual-Hierarchical Entailment Loss that uses hyperbolic entailment cones to enforce the predefined hierarchies, and a Discriminative Alignment Loss with hard negative mining to establish a large geodesic distance between semantically similar compositions. Furthermore, we devise Hyperbolic Cross-Modal Attention to realize instance-aware cross-modal infusion within hyperbolic geometry. Extensive ablations on three benchmarks demonstrate that H2em establishes a new state-of-the-art in both closed-world and open-world scenarios. Our codes will be released.
Low-Altitude UAV-Carried Movable Antenna for Joint Wireless Power Transfer and Covert Communications
Oct 30, 2025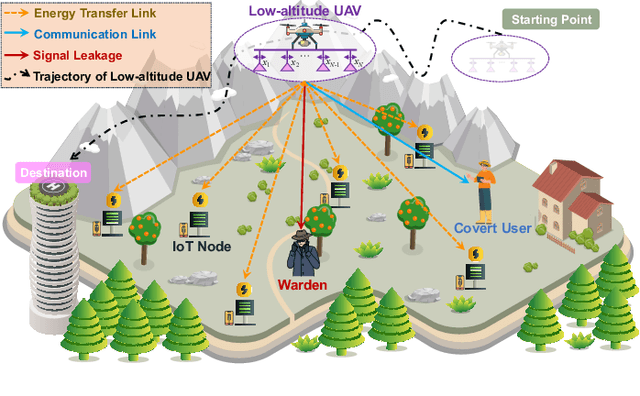
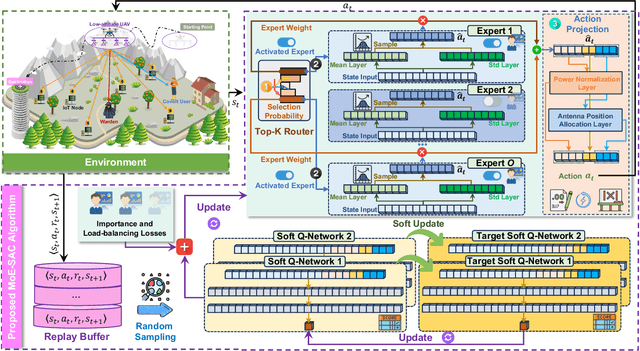
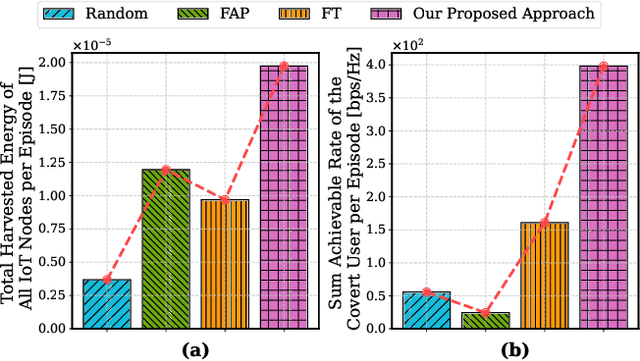
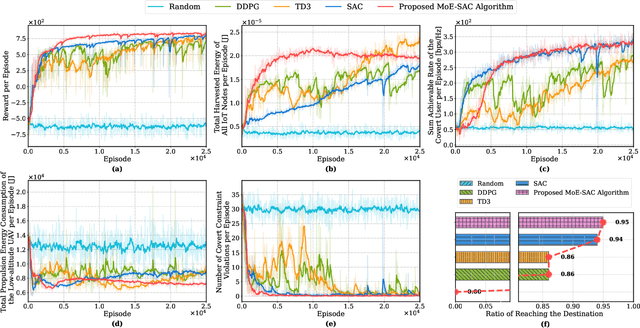
The proliferation of Internet of Things (IoT) networks has created an urgent need for sustainable energy solutions, particularly for the battery-constrained spatially distributed IoT nodes. While low-altitude uncrewed aerial vehicles (UAVs) employed with wireless power transfer (WPT) capabilities offer a promising solution, the line-of-sight channels that facilitate efficient energy delivery also expose sensitive operational data to adversaries. This paper proposes a novel low-altitude UAV-carried movable antenna-enhanced transmission system joint WPT and covert communications, which simultaneously performs energy supplements to IoT nodes and establishes transmission links with a covert user by leveraging wireless energy signals as a natural cover. Then, we formulate a multi-objective optimization problem that jointly maximizes the total harvested energy of IoT nodes and sum achievable rate of the covert user, while minimizing the propulsion energy consumption of the low-altitude UAV. To address the non-convex and temporally coupled optimization problem, we propose a mixture-of-experts-augmented soft actor-critic (MoE-SAC) algorithm that employs a sparse Top-K gated mixture-of-shallow-experts architecture to represent multimodal policy distributions arising from the conflicting optimization objectives. We also incorporate an action projection module that explicitly enforces per-time-slot power budget constraints and antenna position constraints. Simulation results demonstrate that the proposed approach significantly outperforms some baseline approaches and other state-of-the-art deep reinforcement learning algorithms.
Joint AoI and Handover Optimization in Space-Air-Ground Integrated Network
Sep 16, 2025Despite the widespread deployment of terrestrial networks, providing reliable communication services to remote areas and maintaining connectivity during emergencies remains challenging. Low Earth orbit (LEO) satellite constellations offer promising solutions with their global coverage capabilities and reduced latency, yet struggle with intermittent coverage and limited communication windows due to orbital dynamics. This paper introduces an age of information (AoI)-aware space-air-ground integrated network (SAGIN) architecture that leverages a high-altitude platform (HAP) as intelligent relay between the LEO satellites and ground terminals. Our three-layer design employs hybrid free-space optical (FSO) links for high-capacity satellite-to-HAP communication and reliable radio frequency (RF) links for HAP-to-ground transmission, and thus addressing the temporal discontinuity in LEO satellite coverage while serving diverse user priorities. Specifically, we formulate a joint optimization problem to simultaneously minimize the AoI and satellite handover frequency through optimal transmit power distribution and satellite selection decisions. This highly dynamic, non-convex problem with time-coupled constraints presents significant computational challenges for traditional approaches. To address these difficulties, we propose a novel diffusion model (DM)-enhanced dueling double deep Q-network with action decomposition and state transformer encoder (DD3QN-AS) algorithm that incorporates transformer-based temporal feature extraction and employs a DM-based latent prompt generative module to refine state-action representations through conditional denoising. Simulation results highlight the superior performance of the proposed approach compared with policy-based methods and some other deep reinforcement learning (DRL) benchmarks.
Are Humans as Brittle as Large Language Models?
Sep 09, 2025The output of large language models (LLM) is unstable, due to both non-determinism of the decoding process as well as to prompt brittleness. While the intrinsic non-determinism of LLM generation may mimic existing uncertainty in human annotations through distributional shifts in outputs, it is largely assumed, yet unexplored, that the prompt brittleness effect is unique to LLMs. This raises the question: do human annotators show similar sensitivity to instruction changes? If so, should prompt brittleness in LLMs be considered problematic? One may alternatively hypothesize that prompt brittleness correctly reflects human annotation variances. To fill this research gap, we systematically compare the effects of prompt modifications on LLMs and identical instruction modifications for human annotators, focusing on the question of whether humans are similarly sensitive to prompt perturbations. To study this, we prompt both humans and LLMs for a set of text classification tasks conditioned on prompt variations. Our findings indicate that both humans and LLMs exhibit increased brittleness in response to specific types of prompt modifications, particularly those involving the substitution of alternative label sets or label formats. However, the distribution of human judgments is less affected by typographical errors and reversed label order than that of LLMs.
SplitGaussian: Reconstructing Dynamic Scenes via Visual Geometry Decomposition
Aug 06, 2025



Reconstructing dynamic 3D scenes from monocular video remains fundamentally challenging due to the need to jointly infer motion, structure, and appearance from limited observations. Existing dynamic scene reconstruction methods based on Gaussian Splatting often entangle static and dynamic elements in a shared representation, leading to motion leakage, geometric distortions, and temporal flickering. We identify that the root cause lies in the coupled modeling of geometry and appearance across time, which hampers both stability and interpretability. To address this, we propose \textbf{SplitGaussian}, a novel framework that explicitly decomposes scene representations into static and dynamic components. By decoupling motion modeling from background geometry and allowing only the dynamic branch to deform over time, our method prevents motion artifacts in static regions while supporting view- and time-dependent appearance refinement. This disentangled design not only enhances temporal consistency and reconstruction fidelity but also accelerates convergence. Extensive experiments demonstrate that SplitGaussian outperforms prior state-of-the-art methods in rendering quality, geometric stability, and motion separation.
LLM-guided DRL for Multi-tier LEO Satellite Networks with Hybrid FSO/RF Links
May 17, 2025



Despite significant advancements in terrestrial networks, inherent limitations persist in providing reliable coverage to remote areas and maintaining resilience during natural disasters. Multi-tier networks with low Earth orbit (LEO) satellites and high-altitude platforms (HAPs) offer promising solutions, but face challenges from high mobility and dynamic channel conditions that cause unstable connections and frequent handovers. In this paper, we design a three-tier network architecture that integrates LEO satellites, HAPs, and ground terminals with hybrid free-space optical (FSO) and radio frequency (RF) links to maximize coverage while maintaining connectivity reliability. This hybrid approach leverages the high bandwidth of FSO for satellite-to-HAP links and the weather resilience of RF for HAP-to-ground links. We formulate a joint optimization problem to simultaneously balance downlink transmission rate and handover frequency by optimizing network configuration and satellite handover decisions. The problem is highly dynamic and non-convex with time-coupled constraints. To address these challenges, we propose a novel large language model (LLM)-guided truncated quantile critics algorithm with dynamic action masking (LTQC-DAM) that utilizes dynamic action masking to eliminate unnecessary exploration and employs LLMs to adaptively tune hyperparameters. Simulation results demonstrate that the proposed LTQC-DAM algorithm outperforms baseline algorithms in terms of convergence, downlink transmission rate, and handover frequency. We also reveal that compared to other state-of-the-art LLMs, DeepSeek delivers the best performance through gradual, contextually-aware parameter adjustments.
Joint Resource Management for Energy-efficient UAV-assisted SWIPT-MEC: A Deep Reinforcement Learning Approach
May 06, 2025The integration of simultaneous wireless information and power transfer (SWIPT) technology in 6G Internet of Things (IoT) networks faces significant challenges in remote areas and disaster scenarios where ground infrastructure is unavailable. This paper proposes a novel unmanned aerial vehicle (UAV)-assisted mobile edge computing (MEC) system enhanced by directional antennas to provide both computational resources and energy support for ground IoT terminals. However, such systems require multiple trade-off policies to balance UAV energy consumption, terminal battery levels, and computational resource allocation under various constraints, including limited UAV battery capacity, non-linear energy harvesting characteristics, and dynamic task arrivals. To address these challenges comprehensively, we formulate a bi-objective optimization problem that simultaneously considers system energy efficiency and terminal battery sustainability. We then reformulate this non-convex problem with a hybrid solution space as a Markov decision process (MDP) and propose an improved soft actor-critic (SAC) algorithm with an action simplification mechanism to enhance its convergence and generalization capabilities. Simulation results have demonstrated that our proposed approach outperforms various baselines in different scenarios, achieving efficient energy management while maintaining high computational performance. Furthermore, our method shows strong generalization ability across different scenarios, particularly in complex environments, validating the effectiveness of our designed boundary penalty and charging reward mechanisms.
Aerial Active STAR-RIS-assisted Satellite-Terrestrial Covert Communications
Apr 22, 2025An integration of satellites and terrestrial networks is crucial for enhancing performance of next generation communication systems. However, the networks are hindered by the long-distance path loss and security risks in dense urban environments. In this work, we propose a satellite-terrestrial covert communication system assisted by the aerial active simultaneous transmitting and reflecting reconfigurable intelligent surface (AASTAR-RIS) to improve the channel capacity while ensuring the transmission covertness. Specifically, we first derive the minimal detection error probability (DEP) under the worst condition that the Warden has perfect channel state information (CSI). Then, we formulate an AASTAR-RIS-assisted satellite-terrestrial covert communication optimization problem (ASCCOP) to maximize the sum of the fair channel capacity for all ground users while meeting the strict covert constraint, by jointly optimizing the trajectory and active beamforming of the AASTAR-RIS. Due to the challenges posed by the complex and high-dimensional state-action spaces as well as the need for efficient exploration in dynamic environments, we propose a generative deterministic policy gradient (GDPG) algorithm, which is a generative deep reinforcement learning (DRL) method to solve the ASCCOP. Concretely, the generative diffusion model (GDM) is utilized as the policy representation of the algorithm to enhance the exploration process by generating diverse and high-quality samples through a series of denoising steps. Moreover, we incorporate an action gradient mechanism to accomplish the policy improvement of the algorithm, which refines the better state-action pairs through the gradient ascent. Simulation results demonstrate that the proposed approach significantly outperforms important benchmarks.