 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: Behavioral Intention-aware Multimodal Trajectory Prediction with Adaptive Context Trimming
Apr 12, 2025While most prior research has focused on improving the precision of multimodal trajectory predictions, the explicit modeling of multimodal behavioral intentions (e.g., yielding, overtaking) remains relatively underexplored. This paper proposes a unified framework that jointly predicts both behavioral intentions and trajectories to enhance prediction accuracy, interpretability, and efficiency. Specifically, we employ a shared context encoder for both intention and trajectory predictions, thereby reducing structural redundancy and information loss. Moreover, we address the lack of ground-truth behavioral intention labels in mainstream datasets (Waymo, Argoverse) by auto-labeling these datasets, thus advancing the community's efforts in this direction. We further introduce a vectorized occupancy prediction module that infers the probability of each map polyline being occupied by the target vehicle's future trajectory. By leveraging these intention and occupancy prediction priors, our method conducts dynamic, modality-dependent pruning of irrelevant agents and map polylines in the decoding stage, effectively reducing computational overhead and mitigating noise from non-critical elements. Our approach ranks first among LiDAR-free methods on the Waymo Motion Dataset and achieves first place on the Waymo Interactive Prediction Dataset. Remarkably, even without model ensembling, our single-model framework improves the soft mean average precision (softmAP) by 10 percent compared to the second-best method in the Waymo Interactive Prediction Leaderboard. Furthermore, the proposed framework has been successfully deployed on real vehicles, demonstrating its practical effectiveness in real-world applications.
PEGG-Net: Background Agnostic Pixel-Wise Efficient Grasp Generation Under Closed-Loop Conditions
Mar 30, 2022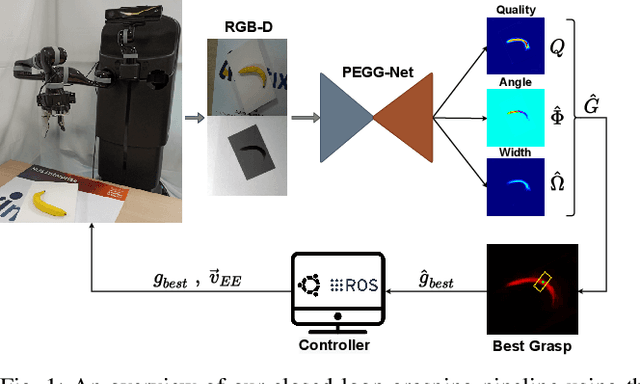
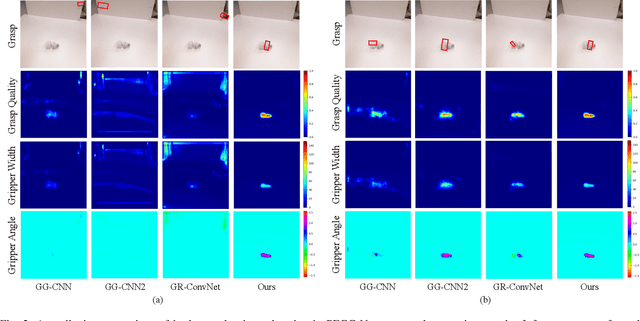
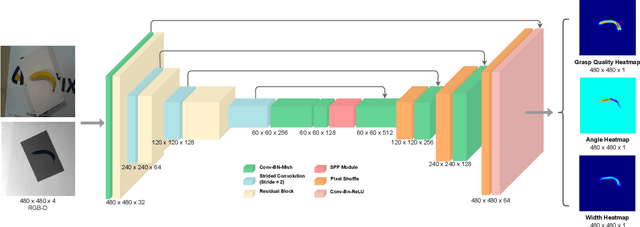

Performing closed-loop grasping at close proximity to an object requires a large field of view. However, such images will inevitably bring large amounts of unnecessary background information, especially when the camera is far away from the target object at the initial stage, resulting in performance degradation of the grasping network. To address this problem, we design a novel PEGG-Net, a real-time, pixel-wise, robotic grasp generation network. The proposed lightweight network is inherently able to learn to remove background noise that can reduce grasping accuracy. Our proposed PEGG-Net achieves improved state-of-the-art performance on both Cornell dataset (98.9%) and Jacquard dataset (93.8%). In the real-world tests, PEGG-Net can support closed-loop grasping at up to 50Hz using an image size of 480x480 in dynamic environments. The trained model also generalizes to previously unseen objects with complex geometrical shapes, household objects and workshop tools and achieved an overall grasp success rate of 91.2% in our real-world grasping experiments.
Improving Learning from Demonstrations by Learning from Experience
Nov 16, 2021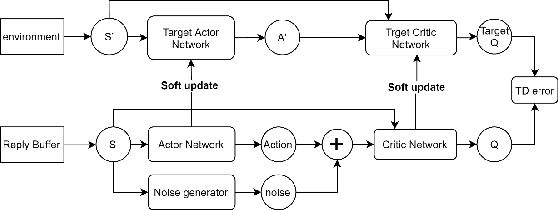
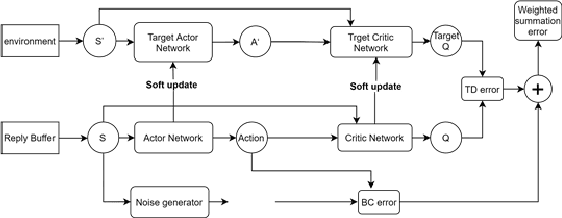
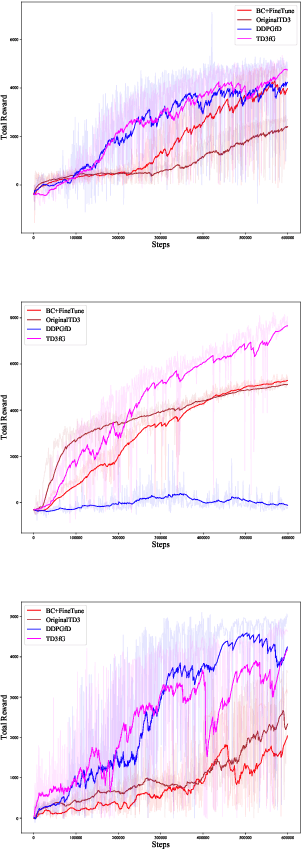
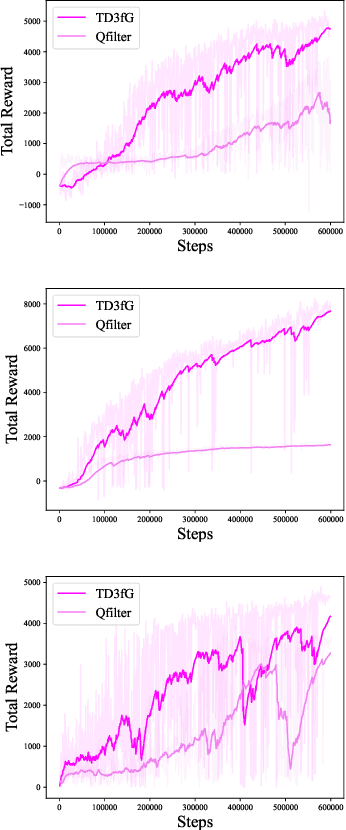
How to make imitation learning more general when demonstrations are relatively limited has been a persistent problem in reinforcement learning (RL). Poor demonstrations lead to narrow and biased date distribution, non-Markovian human expert demonstration makes it difficult for the agent to learn, and over-reliance on sub-optimal trajectories can make it hard for the agent to improve its performance. To solve these problems we propose a new algorithm named TD3fG that can smoothly transition from learning from experts to learning from experience. Our algorithm achieves good performance in the MUJOCO environment with limited and sub-optimal demonstrations. We use behavior cloning to train the network as a reference action generator and utilize it in terms of both loss function and exploration noise. This innovation can help agents extract a priori knowledge from demonstrations while reducing the detrimental effects of the poor Markovian properties of the demonstrations. It has a better performance compared to the BC+ fine-tuning and DDPGfD approach, especially when the demonstrations are relatively limited. We call our method TD3fG meaning TD3 from a generator.
Voxel-based Network for Shape Completion by Leveraging Edge Generation
Aug 23, 2021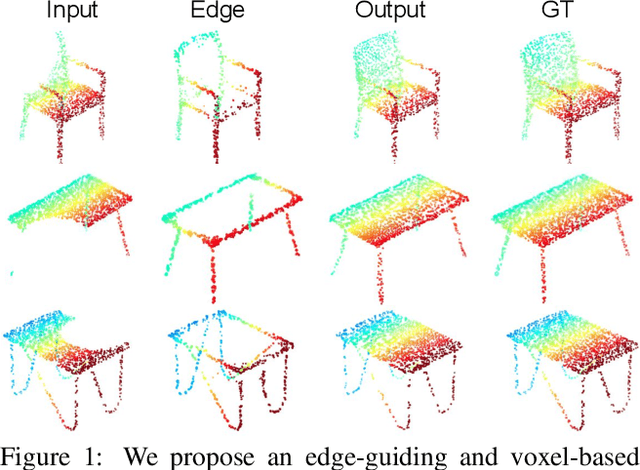
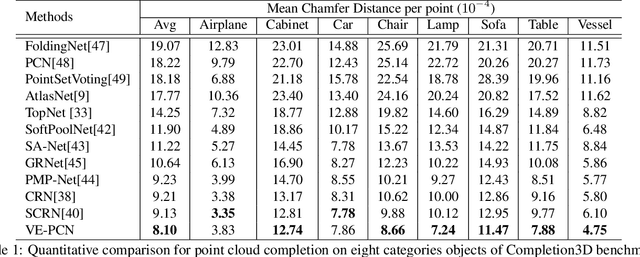


Deep learning technique has yielded significant improvements in point cloud completion with the aim of completing missing object shapes from partial inputs. However, most existing methods fail to recover realistic structures due to over-smoothing of fine-grained details. In this paper, we develop a voxel-based network for point cloud completion by leveraging edge generation (VE-PCN). We first embed point clouds into regular voxel grids, and then generate complete objects with the help of the hallucinated shape edges. This decoupled architecture together with a multi-scale grid feature learning is able to generate more realistic on-surface details. We evaluate our model on the publicly available completion datasets and show that it outperforms existing state-of-the-art approaches quantitatively and qualitatively. Our source code is available at https://github.com/xiaogangw/VE-PCN.
A Self-supervised Cascaded Refinement Network for Point Cloud Completion
Oct 17, 2020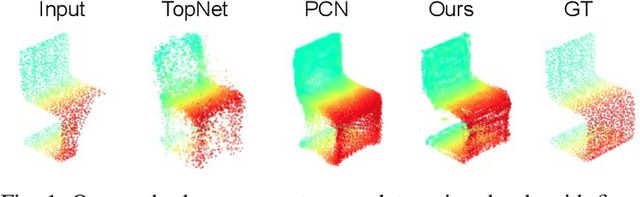
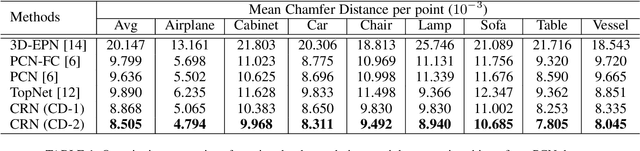
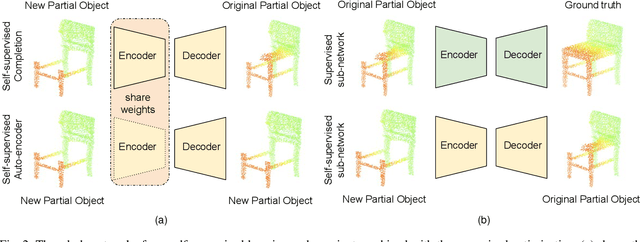

Point clouds are often sparse and incomplete, which imposes difficulties for real-world applications, such as 3D object classification, detection and segmentation. Existing shape completion methods tend to generate coarse shapes of objects without fine-grained details. Moreover, current approaches require fully-complete ground truth, which are difficult to obtain in real-world applications. In view of these, we propose a self-supervised object completion method, which optimizes the training procedure solely on the partial input without utilizing the fully-complete ground truth. In order to generate high-quality objects with detailed geometric structures, we propose a cascaded refinement network (CRN) with a coarse-to-fine strategy to synthesize the complete objects. Considering the local details of partial input together with the adversarial training, we are able to learn the complicated distributions of point clouds and generate the object details as realistic as possible. We verify our self-supervised method on both unsupervised and supervised experimental settings and show superior performances. Quantitative and qualitative experiments on different datasets demonstrate that our method achieves more realistic outputs compared to existing state-of-the-art approaches on the 3D point cloud completion task.
Point Cloud Completion by Learning Shape Priors
Aug 02, 2020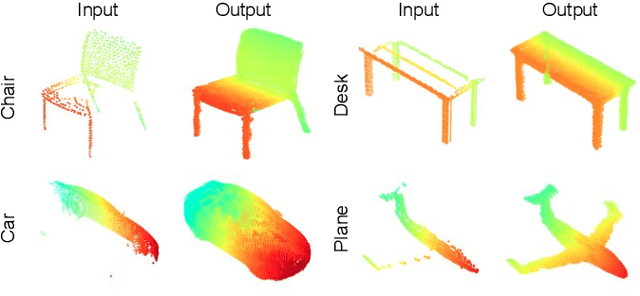
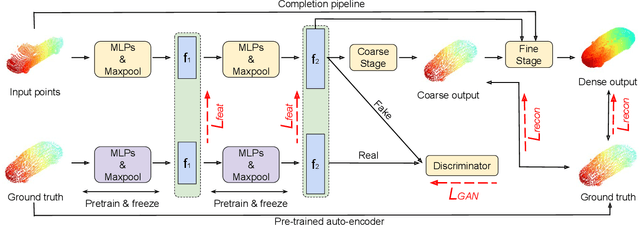
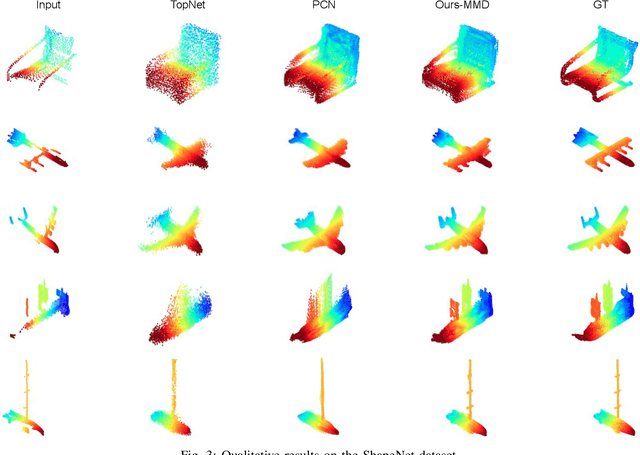
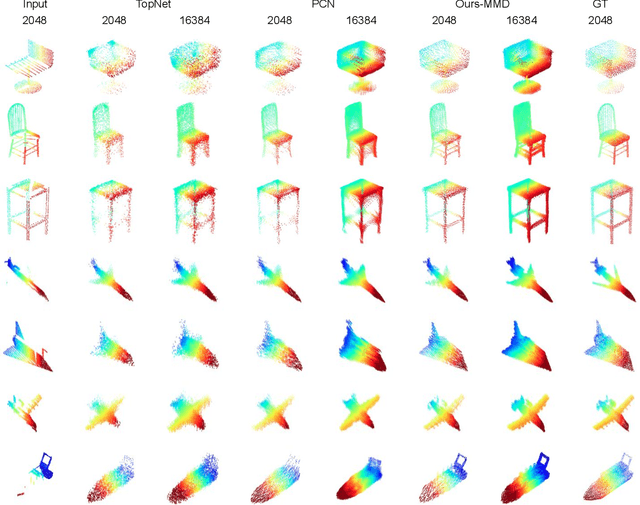
In view of the difficulty in reconstructing object details in point cloud completion, we propose a shape prior learning method for object completion. The shape priors include geometric information in both complete and the partial point clouds. We design a feature alignment strategy to learn the shape prior from complete points, and a coarse to fine strategy to incorporate partial prior in the fine stage. To learn the complete objects prior, we first train a point cloud auto-encoder to extract the latent embeddings from complete points. Then we learn a mapping to transfer the point features from partial points to that of the complete points by optimizing feature alignment losses. The feature alignment losses consist of a L2 distance and an adversarial loss obtained by Maximum Mean Discrepancy Generative Adversarial Network (MMD-GAN). The L2 distance optimizes the partial features towards the complete ones in the feature space, and MMD-GAN decreases the statistical distance of two point features in a Reproducing Kernel Hilbert Space. We achieve state-of-the-art performances on the point cloud completion task. Our code is available at https://github.com/xiaogangw/point-cloud-completion-shape-prior.
Shape Prior Deformation for Categorical 6D Object Pose and Size Estimation
Jul 16, 2020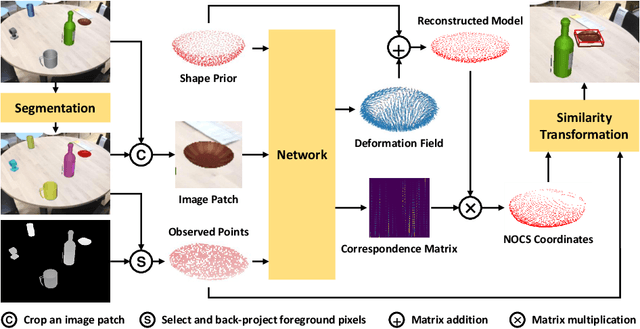
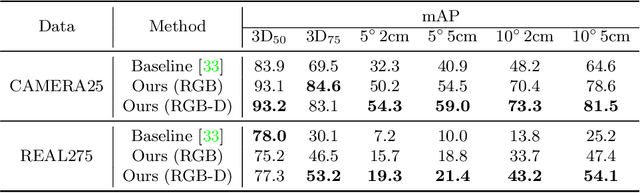


We present a novel learning approach to recover the 6D poses and sizes of unseen object instances from an RGB-D image. To handle the intra-class shape variation, we propose a deep network to reconstruct the 3D object model by explicitly modeling the deformation from a pre-learned categorical shape prior. Additionally, our network infers the dense correspondences between the depth observation of the object instance and the reconstructed 3D model to jointly estimate the 6D object pose and size. We design an autoencoder that trains on a collection of object models and compute the mean latent embedding for each category to learn the categorical shape priors. Extensive experiments on both synthetic and real-world datasets demonstrate that our approach significantly outperforms the state of the art. Our code is available at https://github.com/mentian/object-deformnet.
Cascaded Refinement Network for Point Cloud Completion
Apr 07, 2020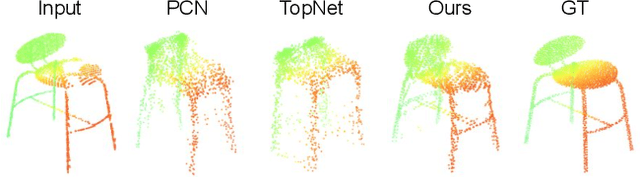
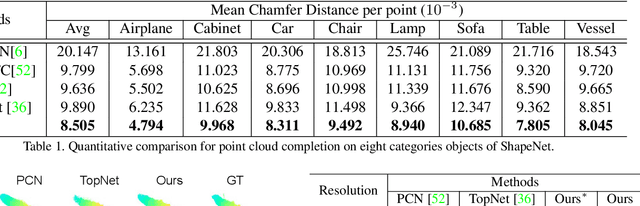
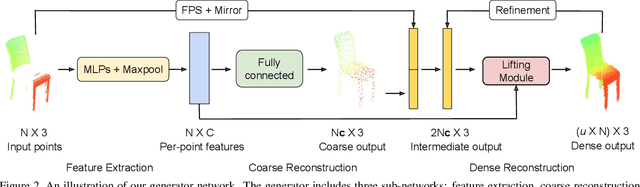
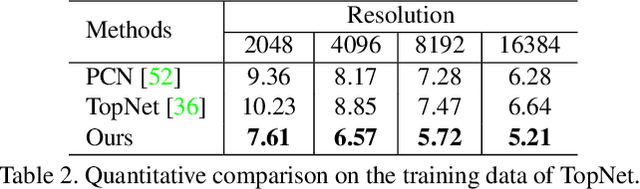
Point clouds are often sparse and incomplete. Existing shape completion methods are incapable of generating details of objects or learning the complex point distributions. To this end, we propose a cascaded refinement network together with a coarse-to-fine strategy to synthesize the detailed object shapes. Considering the local details of partial input with the global shape information together, we can preserve the existing details in the incomplete point set and generate the missing parts with high fidelity. We also design a patch discriminator that guarantees every local area has the same pattern with the ground truth to learn the complicated point distribution. Quantitative and qualitative experiments on different datasets show that our method achieves superior results compared to existing state-of-the-art approaches on the 3D point cloud completion task. Our source code is available at https://github.com/xiaogangw/cascaded-point-completion.git.
Robust 6D Object Pose Estimation by Learning RGB-D Features
Mar 09, 2020

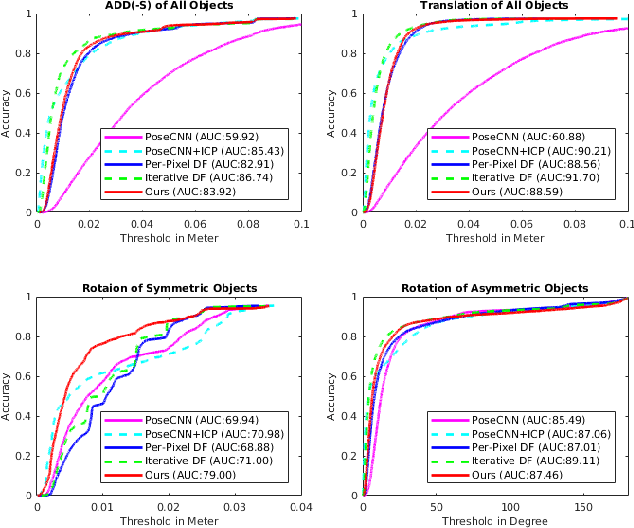
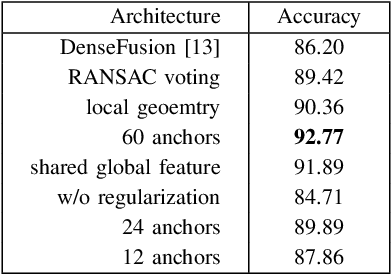
Accurate 6D object pose estimation is fundamental to robotic manipulation and grasping. Previous methods follow a local optimization approach which minimizes the distance between closest point pairs to handle the rotation ambiguity of symmetric objects. In this work, we propose a novel discrete-continuous formulation for rotation regression to resolve this local-optimum problem. We uniformly sample rotation anchors in SO(3), and predict a constrained deviation from each anchor to the target, as well as uncertainty scores for selecting the best prediction. Additionally, the object location is detected by aggregating point-wise vectors pointing to the 3D center. Experiments on two benchmarks: LINEMOD and YCB-Video, show that the proposed method outperforms state-of-the-art approaches. Our code is available at https://github.com/mentian/object-posenet.