 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Pinching Antenna-aided NOMA Systems with Internal Eavesdropping
Dec 25, 2025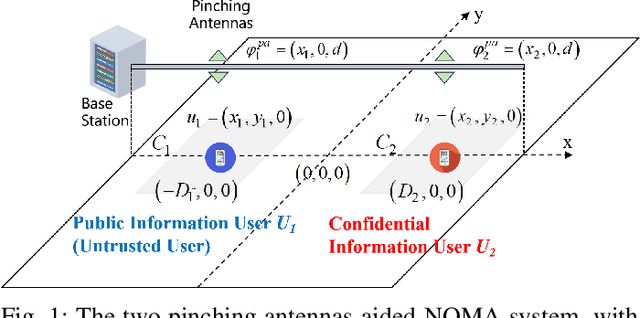
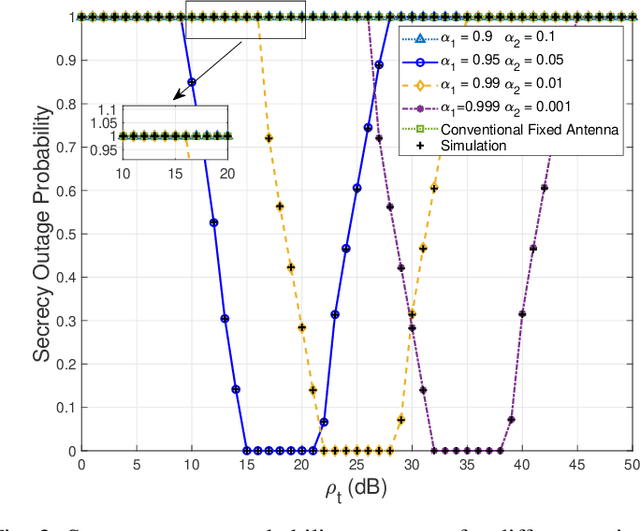
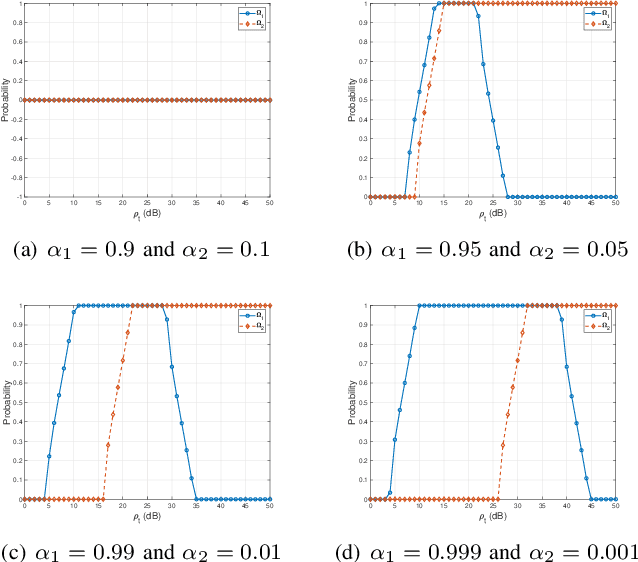
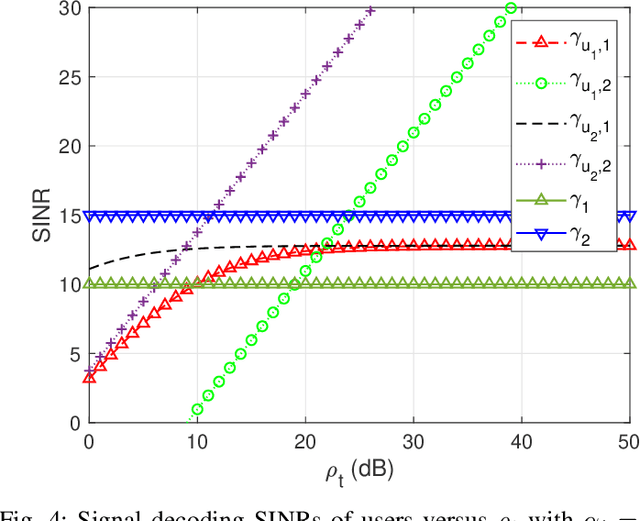
As a novel member of flexible antennas, the pinching antenna (PA) is realized by integrating small dielectric particles on a waveguide, offering unique regulatory capabilities on constructing line-of-sight (LoS) links and enhancing transceiver channels, reducing path loss and signal blockage. Meanwhile, non-orthogonal multiple access (NOMA) has become a potential technology of next-generation communications due to its remarkable advantages in spectrum efficiency and user access capability. The integration of PA and NOMA enables synergistic leveraging of PA's channel regulation capability and NOMA's multi-user multiplexing advantage, forming a complementary technical framework to deliver high-performance communication solutions. However, the use of successive interference cancellation (SIC) introduces significant security risks to power-domain NOMA systems when internal eavesdropping is present. To this end, this paper investigates the physical layer security of a PA-aided NOMA system where a nearby user is considered as an internal eavesdropper. We enhance the security of the NOMA system through optimizing the radiated power of PAs and analyze the secrecy performance by deriving the closed-form expressions for the secrecy outage probability (SOP). Furthermore, we extend the characterization of PA flexibility beyond deployment and scale adjustment to include flexible regulation of PA coupling length. Based on two conventional PA power models, i.e., the equal power model and the proportional power model, we propose a flexible power strategy to achieve secure transmission. The results highlight the potential of the PA-aided NOMA system in mitigating internal eavesdropping risks, and provide an effective strategy for optimizing power allocation and cell range of user activity.
Human or LLM as Standardized Patients? A Comparative Study for Medical Education
Nov 12, 2025Standardized Patients (SP) are indispensable for clinical skills training but remain expensive, inflexible, and difficult to scale. Existing large-language-model (LLM)-based SP simulators promise lower cost yet show inconsistent behavior and lack rigorous comparison with human SP. We present EasyMED, a multi-agent framework combining a Patient Agent for realistic dialogue, an Auxiliary Agent for factual consistency, and an Evaluation Agent that delivers actionable feedback. To support systematic assessment, we introduce SPBench, a benchmark of real SP-doctor interactions spanning 14 specialties and eight expert-defined evaluation criteria. Experiments demonstrate that EasyMED matches human SP learning outcomes while producing greater skill gains for lower-baseline students and offering improved flexibility, psychological safety, and cost efficiency.
Performance Analysis of Wireless-Powered Pinching Antenna Systems
Nov 05, 2025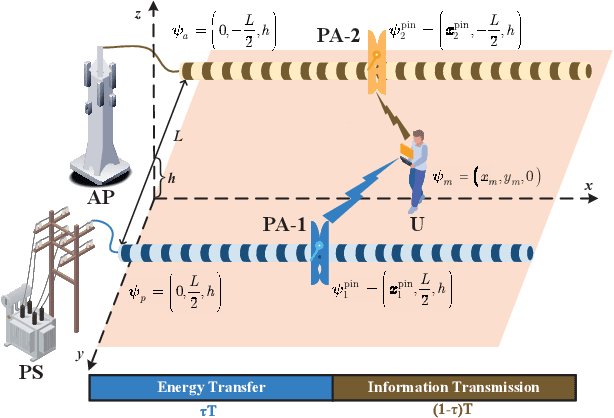
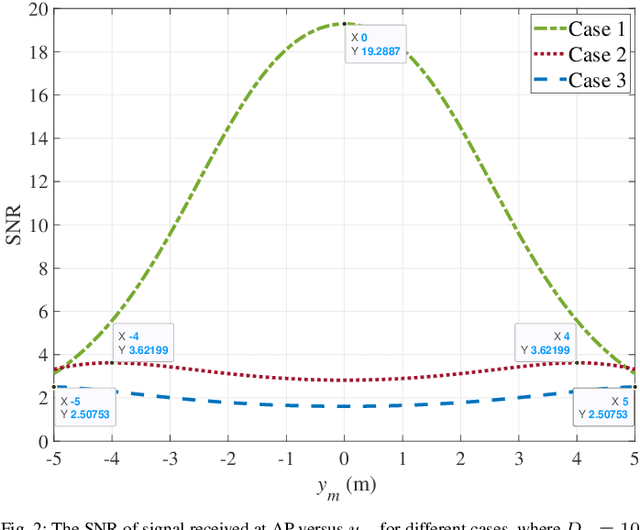
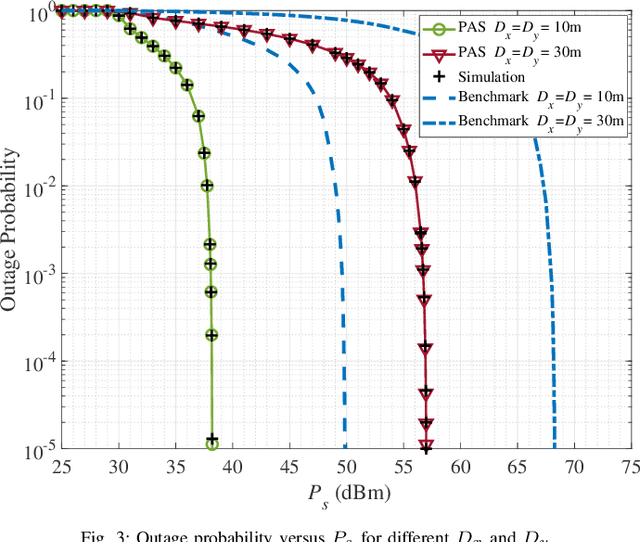
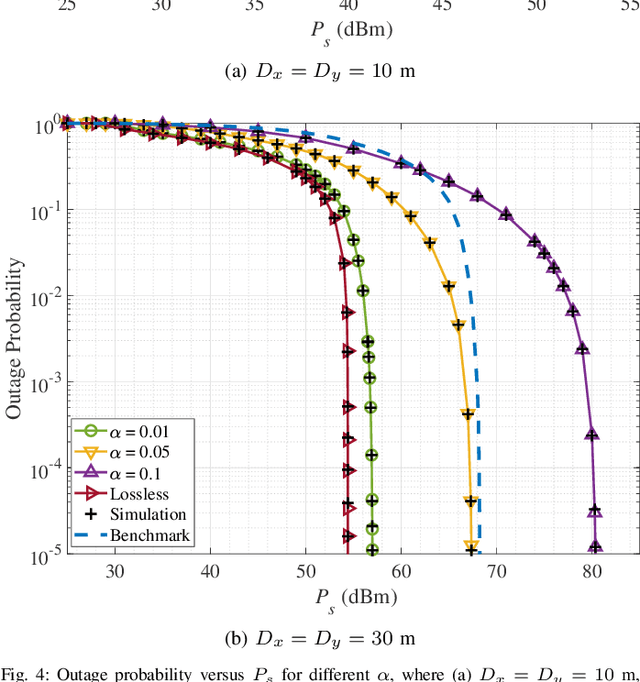
Pinching antenna system (PAS) serves as a groundbreaking paradigm that enhances wireless communications by flexibly adjusting the position of pinching antenna (PA) and establishing a strong line-of-sight (LoS) link, thereby reducing the free-space path loss. This paper introduces the concept of wireless-powered PAS, and investigates the reliability of wireless-powered PAS to explore the advantages of PA in improving the performance of wireless-powered communication (WPC) system. In addition, we derive the closed-form expressions of outage probability and ergodic rate for the practical lossy waveguide case and ideal lossless waveguide case, respectively, and analyze the optimal deployment of waveguides and user to provide valuable insights for guiding their deployments. The results show that an increase in the absorption coefficient and in the dimensions of the user area leads to higher in-waveguide and free-space propagation losses, respectively, which in turn increase the outage probability and reduce the ergodic rate of the wireless-powered PAS. However, the performance of wireless-powered PAS is severely affected by the absorption coefficient and the waveguide length, e.g., under conditions of high absorption coefficient and long waveguide, the outage probability of wireless-powered PAS is even worse than that of traditional WPC system. While the ergodic rate of wireless-powered PAS is better than that of traditional WPC system under conditions of high absorption coefficient and long waveguide. Interestingly, the wireless-powered PAS has the optimal time allocation factor and optimal distance between power station (PS) and access point (AP) to minimize the outage probability or maximize the ergodic rate. Moreover, the system performance of PS and AP separated at the optimal distance between PS and AP is superior to that of PS and AP integrated into a hybrid access point.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Team Xiaomi EV-AD VLA: Learning to Navigate Socially Through Proactive Risk Perception - Technical Report for IROS 2025 RoboSense Challenge Social Navigation Track
Oct 09, 2025In this report, we describe the technical details of our submission to the IROS 2025 RoboSense Challenge Social Navigation Track. This track focuses on developing RGBD-based perception and navigation systems that enable autonomous agents to navigate safely, efficiently, and socially compliantly in dynamic human-populated indoor environments. The challenge requires agents to operate from an egocentric perspective using only onboard sensors including RGB-D observations and odometry, without access to global maps or privileged information, while maintaining social norm compliance such as safe distances and collision avoidance. Building upon the Falcon model, we introduce a Proactive Risk Perception Module to enhance social navigation performance. Our approach augments Falcon with collision risk understanding that learns to predict distance-based collision risk scores for surrounding humans, which enables the agent to develop more robust spatial awareness and proactive collision avoidance behaviors. The evaluation on the Social-HM3D benchmark demonstrates that our method improves the agent's ability to maintain personal space compliance while navigating toward goals in crowded indoor scenes with dynamic human agents, achieving 2nd place among 16 participating teams in the challenge.
Non-Registration Change Detection: A Novel Change Detection Task and Benchmark Dataset
May 15, 2025


In this study, we propose a novel remote sensing change detection task, non-registration change detection, to address the increasing number of emergencies such as natural disasters, anthropogenic accidents, and military strikes. First, in light of the limited discourse on the issue of non-registration change detection, we systematically propose eight scenarios that could arise in the real world and potentially contribute to the occurrence of non-registration problems. Second, we develop distinct image transformation schemes tailored to various scenarios to convert the available registration change detection dataset into a non-registration version. Finally, we demonstrate that non-registration change detection can cause catastrophic damage to the state-of-the-art methods. Our code and dataset are available at https://github.com/ShanZard/NRCD.
ROS-SAM: High-Quality Interactive Segmentation for Remote Sensing Moving Object
Mar 15, 2025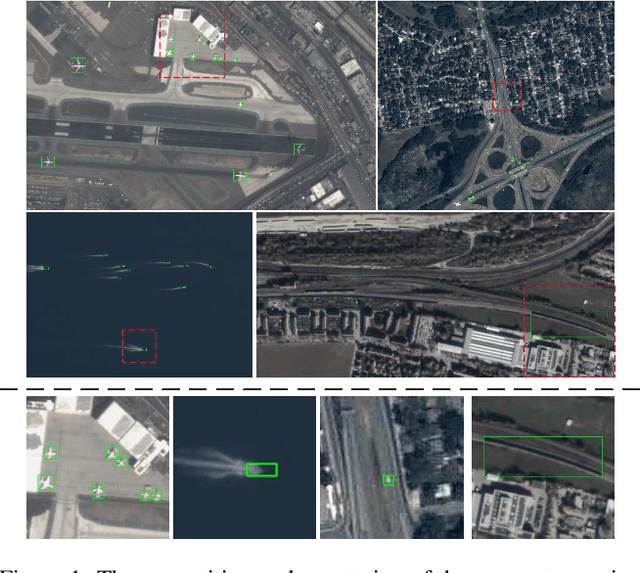

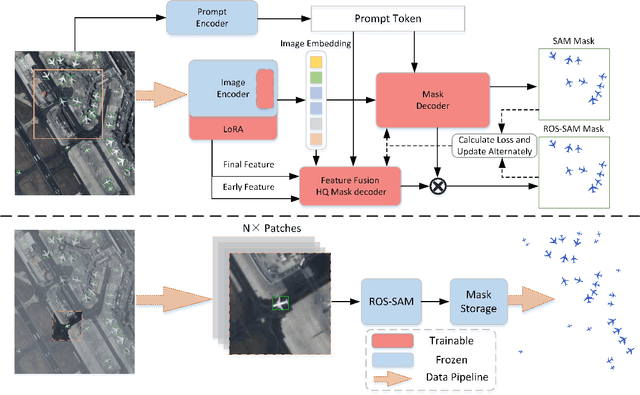

The availability of large-scale remote sensing video data underscores the importance of high-quality interactive segmentation. However, challenges such as small object sizes, ambiguous features, and limited generalization make it difficult for current methods to achieve this goal. In this work, we propose ROS-SAM, a method designed to achieve high-quality interactive segmentation while preserving generalization across diverse remote sensing data. The ROS-SAM is built upon three key innovations: 1) LoRA-based fine-tuning, which enables efficient domain adaptation while maintaining SAM's generalization ability, 2) Enhancement of deep network layers to improve the discriminability of extracted features, thereby reducing misclassifications, and 3) Integration of global context with local boundary details in the mask decoder to generate high-quality segmentation masks. Additionally, we design the data pipeline to ensure the model learns to better handle objects at varying scales during training while focusing on high-quality predictions during inference. Experiments on remote sensing video datasets show that the redesigned data pipeline boosts the IoU by 6%, while ROS-SAM increases the IoU by 13%. Finally, when evaluated on existing remote sensing object tracking datasets, ROS-SAM demonstrates impressive zero-shot capabilities, generating masks that closely resemble manual annotations. These results confirm ROS-SAM as a powerful tool for fine-grained segmentation in remote sensing applications. Code is available at https://github.com/ShanZard/ROS-SAM.
FUIA: Model Inversion Attack against Federated Unlearning
Feb 20, 2025



With the introduction of regulations related to the ``right to be forgotten", federated learning (FL) is facing new privacy compliance challenges. To address these challenges, researchers have proposed federated unlearning (FU). However, existing FU research has primarily focused on improving the efficiency of unlearning, with less attention paid to the potential privacy vulnerabilities inherent in these methods. To address this gap, we draw inspiration from gradient inversion attacks in FL and propose the federated unlearning inversion attack (FUIA). The FUIA is specifically designed for the three types of FU (sample unlearning, client unlearning, and class unlearning), aiming to provide a comprehensive analysis of the privacy leakage risks associated with FU. In FUIA, the server acts as an honest-but-curious attacker, recording and exploiting the model differences before and after unlearning to expose the features and labels of forgotten data. FUIA significantly leaks the privacy of forgotten data and can target all types of FU. This attack contradicts the goal of FU to eliminate specific data influence, instead exploiting its vulnerabilities to recover forgotten data and expose its privacy flaws. Extensive experimental results show that FUIA can effectively reveal the private information of forgotten data. To mitigate this privacy leakage, we also explore two potential defense methods, although these come at the cost of reduced unlearning effectiveness and the usability of the unlearned model.