 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDAR: Lightweight Adaptive Cue-Aware Fusion Vision Mamba for Multimodal Segmentation of Structural Cracks
Jul 30, 2025Achieving pixel-level segmentation with low computational cost using multimodal data remains a key challenge in crack segmentation tasks. Existing methods lack the capability for adaptive perception and efficient interactive fusion of cross-modal features. To address these challenges, we propose a Lightweight Adaptive Cue-Aware Vision Mamba network (LIDAR), which efficiently perceives and integrates morphological and textural cues from different modalities under multimodal crack scenarios, generating clear pixel-level crack segmentation maps. Specifically, LIDAR is composed of a Lightweight Adaptive Cue-Aware Visual State Space module (LacaVSS) and a Lightweight Dual Domain Dynamic Collaborative Fusion module (LD3CF). LacaVSS adaptively models crack cues through the proposed mask-guided Efficient Dynamic Guided Scanning Strategy (EDG-SS), while LD3CF leverages an Adaptive Frequency Domain Perceptron (AFDP) and a dual-pooling fusion strategy to effectively capture spatial and frequency-domain cues across modalities. Moreover, we design a Lightweight Dynamically Modulated Multi-Kernel convolution (LDMK) to perceive complex morphological structures with minimal computational overhead, replacing most convolutional operations in LIDAR. Experiments on three datasets demonstrate that our method outperforms other state-of-the-art (SOTA) methods. On the light-field depth dataset, our method achieves 0.8204 in F1 and 0.8465 in mIoU with only 5.35M parameters. Code and datasets are available at https://github.com/Karl1109/LIDAR-Mamba.
Non-Registration Change Detection: A Novel Change Detection Task and Benchmark Dataset
May 15, 2025


In this study, we propose a novel remote sensing change detection task, non-registration change detection, to address the increasing number of emergencies such as natural disasters, anthropogenic accidents, and military strikes. First, in light of the limited discourse on the issue of non-registration change detection, we systematically propose eight scenarios that could arise in the real world and potentially contribute to the occurrence of non-registration problems. Second, we develop distinct image transformation schemes tailored to various scenarios to convert the available registration change detection dataset into a non-registration version. Finally, we demonstrate that non-registration change detection can cause catastrophic damage to the state-of-the-art methods. Our code and dataset are available at https://github.com/ShanZard/NRCD.
ROS-SAM: High-Quality Interactive Segmentation for Remote Sensing Moving Object
Mar 15, 2025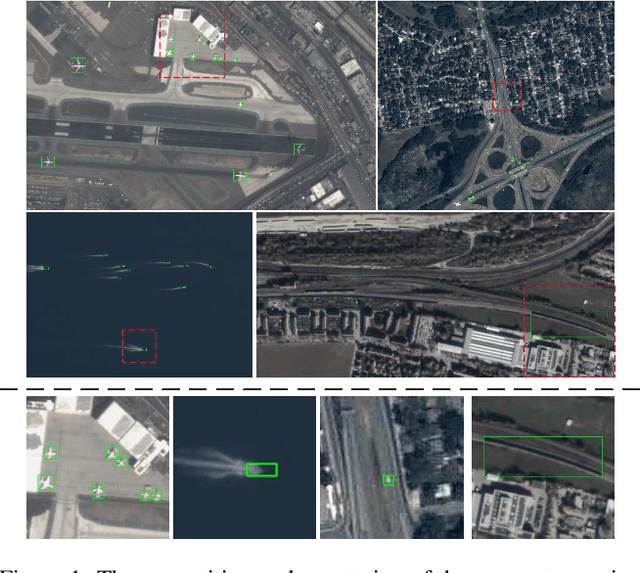

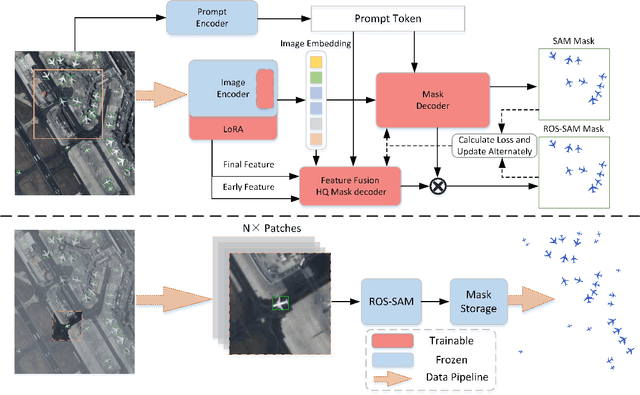

The availability of large-scale remote sensing video data underscores the importance of high-quality interactive segmentation. However, challenges such as small object sizes, ambiguous features, and limited generalization make it difficult for current methods to achieve this goal. In this work, we propose ROS-SAM, a method designed to achieve high-quality interactive segmentation while preserving generalization across diverse remote sensing data. The ROS-SAM is built upon three key innovations: 1) LoRA-based fine-tuning, which enables efficient domain adaptation while maintaining SAM's generalization ability, 2) Enhancement of deep network layers to improve the discriminability of extracted features, thereby reducing misclassifications, and 3) Integration of global context with local boundary details in the mask decoder to generate high-quality segmentation masks. Additionally, we design the data pipeline to ensure the model learns to better handle objects at varying scales during training while focusing on high-quality predictions during inference. Experiments on remote sensing video datasets show that the redesigned data pipeline boosts the IoU by 6%, while ROS-SAM increases the IoU by 13%. Finally, when evaluated on existing remote sensing object tracking datasets, ROS-SAM demonstrates impressive zero-shot capabilities, generating masks that closely resemble manual annotations. These results confirm ROS-SAM as a powerful tool for fine-grained segmentation in remote sensing applications. Code is available at https://github.com/ShanZard/ROS-SAM.
Harnessing the Power of Large Language Model for Uncertainty Aware Graph Processing
Apr 12, 2024


Handling graph data is one of the most difficult tasks. Traditional techniques, such as those based on geometry and matrix factorization, rely on assumptions about the data relations that become inadequate when handling large and complex graph data. On the other hand, deep learning approaches demonstrate promising results in handling large graph data, but they often fall short of providing interpretable explanations. To equip the graph processing with both high accuracy and explainability, we introduce a novel approach that harnesses the power of a large language model (LLM), enhanced by an uncertainty-aware module to provide a confidence score on the generated answer. We experiment with our approach on two graph processing tasks: few-shot knowledge graph completion and graph classification. Our results demonstrate that through parameter efficient fine-tuning, the LLM surpasses state-of-the-art algorithms by a substantial margin across ten diverse benchmark datasets. Moreover, to address the challenge of explainability, we propose an uncertainty estimation based on perturbation, along with a calibration scheme to quantify the confidence scores of the generated answers. Our confidence measure achieves an AUC of 0.8 or higher on seven out of the ten datasets in predicting the correctness of the answer generated by LLM.
Unsupervised Deep Cross-Language Entity Alignment
Sep 19, 2023Cross-lingual entity alignment is the task of finding the same semantic entities from different language knowledge graphs. In this paper, we propose a simple and novel unsupervised method for cross-language entity alignment. We utilize the deep learning multi-language encoder combined with a machine translator to encode knowledge graph text, which reduces the reliance on label data. Unlike traditional methods that only emphasize global or local alignment, our method simultaneously considers both alignment strategies. We first view the alignment task as a bipartite matching problem and then adopt the re-exchanging idea to accomplish alignment. Compared with the traditional bipartite matching algorithm that only gives one optimal solution, our algorithm generates ranked matching results which enabled many potentials downstream tasks. Additionally, our method can adapt two different types of optimization (minimal and maximal) in the bipartite matching process, which provides more flexibility. Our evaluation shows, we each scored 0.966, 0.990, and 0.996 Hits@1 rates on the DBP15K dataset in Chinese, Japanese, and French to English alignment tasks. We outperformed the state-of-the-art method in unsupervised and semi-supervised categories. Compared with the state-of-the-art supervised method, our method outperforms 2.6% and 0.4% in Ja-En and Fr-En alignment tasks while marginally lower by 0.2% in the Zh-En alignment task.