 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoQuery: Geometry-Query Diffusion for Sparse-View Reconstruction
May 12, 20263D Gaussian Splatting (3DGS) has emerged as a prominent paradigm for 3D reconstruction and novel view synthesis. However, it remains vulnerable to severe artifacts when trained under sparse-view constraints. While recent methods attempt to rectify artifacts in rendered views using image diffusion models, they typically rely on multi-view self-attention to retrieve information from reference images. We observe that this mechanism often fails when the rendered novel views output by 3DGS are heavily corrupted: damaged query features lead to erroneous cross-view retrieval, resulting in inconsistent rendering refinement. To address this, we propose GeoQuery, a geometry-guided diffusion framework that integrates generative priors with explicit geometric cues via a novel Geometry-guided Cross-view Attention (GCA) mechanism. First, by leveraging predicted depth maps and camera poses, we construct a geometry-induced correspondence field to sample reference features, forming a geometry-aligned proxy query that replaces the corrupted rendering features. Furthermore, we design a new cross-view feature aggregation pipeline, in which we restrict the cross-view attention to a local window around each proxy query to effectively retrieve useful features while suppressing spurious matches. GeoQuery can be seamlessly integrated into existing diffusion-based pipelines, enabling robust reconstruction even under extreme view sparsity. Extensive experiments on sparse-view novel view synthesis and rendering artifact removal demonstrate the effectiveness of our approach.
Let Your Image Move with Your Motion! -- Implicit Multi-Object Multi-Motion Transfer
Mar 01, 2026Motion transfer has emerged as a promising direction for controllable video generation, yet existing methods largely focus on single-object scenarios and struggle when multiple objects require distinct motion patterns. In this work, we present FlexiMMT, the first implicit image-to-video (I2V) motion transfer framework that explicitly enables multi-object, multi-motion transfer. Given a static multi-object image and multiple reference videos, FlexiMMT independently extracts motion representations and accurately assigns them to different objects, supporting flexible recombination and arbitrary motion-to-object mappings. To address the core challenge of cross-object motion entanglement, we introduce a Motion Decoupled Mask Attention Mechanism that uses object-specific masks to constrain attention, ensuring that motion and text tokens only influence their designated regions. We further propose a Differentiated Mask Propagation Mechanism that derives object-specific masks directly from diffusion attention and progressively propagates them across frames efficiently. Extensive experiments demonstrate that FlexiMMT achieves precise, compositional, and state-of-the-art performance in I2V-based multi-object multi-motion transfer.
LCDB 1.1: A Database Illustrating Learning Curves Are More Ill-Behaved Than Previously Thought
May 21, 2025



Sample-wise learning curves plot performance versus training set size. They are useful for studying scaling laws and speeding up hyperparameter tuning and model selection. Learning curves are often assumed to be well-behaved: monotone (i.e. improving with more data) and convex. By constructing the Learning Curves Database 1.1 (LCDB 1.1), a large-scale database with high-resolution learning curves, we show that learning curves are less often well-behaved than previously thought. Using statistically rigorous methods, we observe significant ill-behavior in approximately 14% of the learning curves, almost twice as much as in previous estimates. We also identify which learners are to blame and show that specific learners are more ill-behaved than others. Additionally, we demonstrate that different feature scalings rarely resolve ill-behavior. We evaluate the impact of ill-behavior on downstream tasks, such as learning curve fitting and model selection, and find it poses significant challenges, underscoring the relevance and potential of LCDB 1.1 as a challenging benchmark for future research.
ROS-SAM: High-Quality Interactive Segmentation for Remote Sensing Moving Object
Mar 15, 2025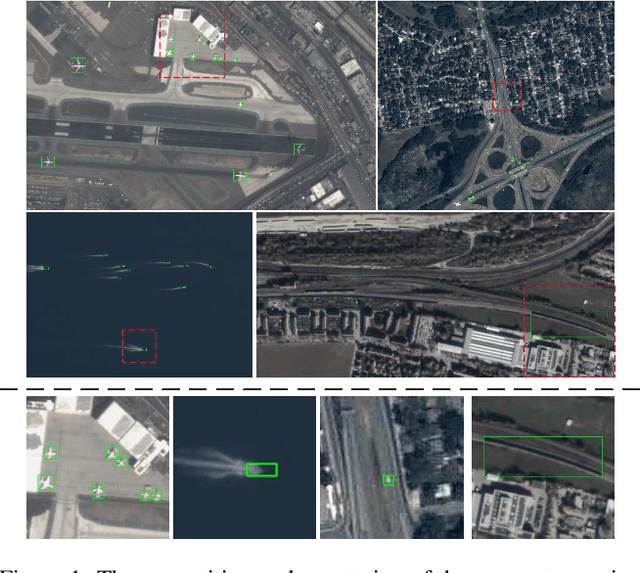

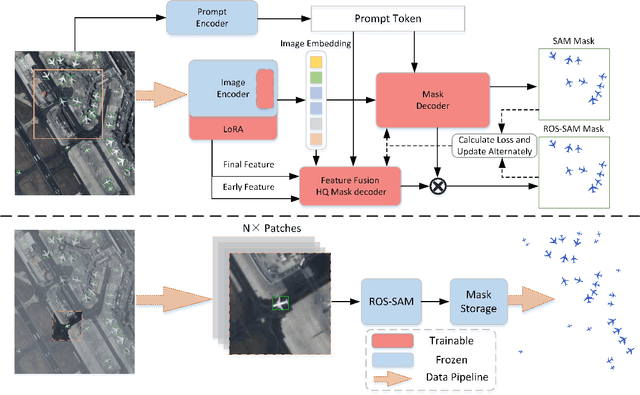

The availability of large-scale remote sensing video data underscores the importance of high-quality interactive segmentation. However, challenges such as small object sizes, ambiguous features, and limited generalization make it difficult for current methods to achieve this goal. In this work, we propose ROS-SAM, a method designed to achieve high-quality interactive segmentation while preserving generalization across diverse remote sensing data. The ROS-SAM is built upon three key innovations: 1) LoRA-based fine-tuning, which enables efficient domain adaptation while maintaining SAM's generalization ability, 2) Enhancement of deep network layers to improve the discriminability of extracted features, thereby reducing misclassifications, and 3) Integration of global context with local boundary details in the mask decoder to generate high-quality segmentation masks. Additionally, we design the data pipeline to ensure the model learns to better handle objects at varying scales during training while focusing on high-quality predictions during inference. Experiments on remote sensing video datasets show that the redesigned data pipeline boosts the IoU by 6%, while ROS-SAM increases the IoU by 13%. Finally, when evaluated on existing remote sensing object tracking datasets, ROS-SAM demonstrates impressive zero-shot capabilities, generating masks that closely resemble manual annotations. These results confirm ROS-SAM as a powerful tool for fine-grained segmentation in remote sensing applications. Code is available at https://github.com/ShanZard/ROS-SAM.
Dual-Modal Prototype Joint Learning for Compositional Zero-Shot Learning
Jan 23, 2025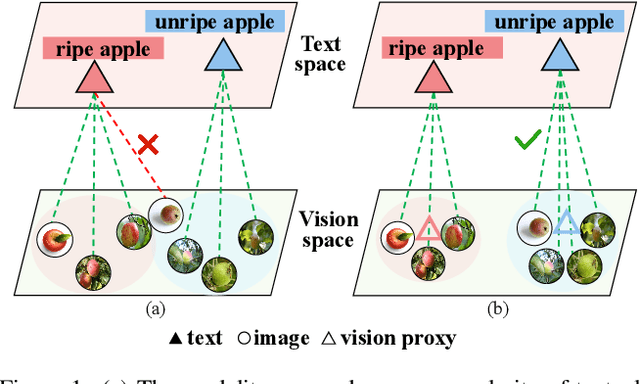

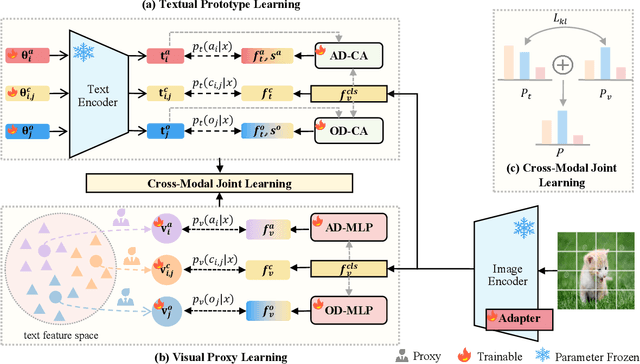
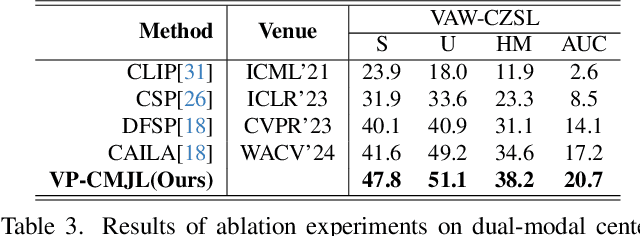
Compositional Zero-Shot Learning (CZSL) aims to recognize novel compositions of attributes and objects by leveraging knowledge learned from seen compositions. Recent approaches have explored the use of Vision-Language Models (VLMs) to align textual and visual modalities. These methods typically employ prompt engineering, parameter-tuning, and modality fusion to generate rich textual prototypes that serve as class prototypes for CZSL. However, the modality gap results in textual prototypes being unable to fully capture the optimal representations of all class prototypes, particularly those with fine-grained features, which can be directly obtained from the visual modality. In this paper, we propose a novel Dual-Modal Prototype Joint Learning framework for the CZSL task. Our approach, based on VLMs, introduces prototypes in both the textual and visual modalities. The textual prototype is optimized to capture broad conceptual information, aiding the model's generalization across unseen compositions. Meanwhile, the visual prototype is used to mitigate the classification errors caused by the modality gap and capture fine-grained details to distinguish images with similar appearances. To effectively optimize these prototypes, we design specialized decomposition modules and a joint learning strategy that enrich the features from both modalities. These prototypes not only capture key category information during training but also serve as crucial reference targets during inference. Experimental results demonstrate that our approach achieves state-of-the-art performance in the closed-world setting and competitive performance in the open-world setting across three publicly available CZSL benchmarks. These findings validate the effectiveness of our method in advancing compositional generalization.
A New Action Recognition Framework for Video Highlights Summarization in Sporting Events
Dec 01, 2020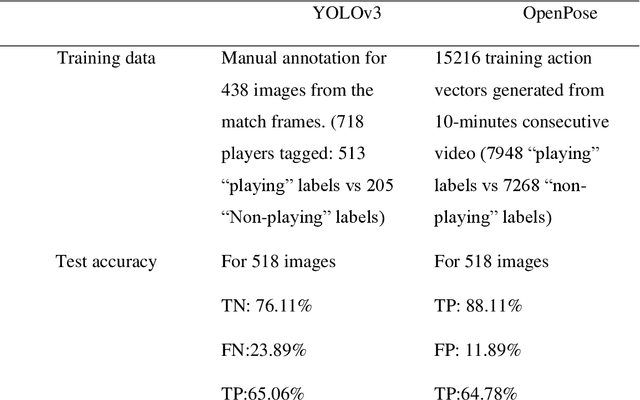
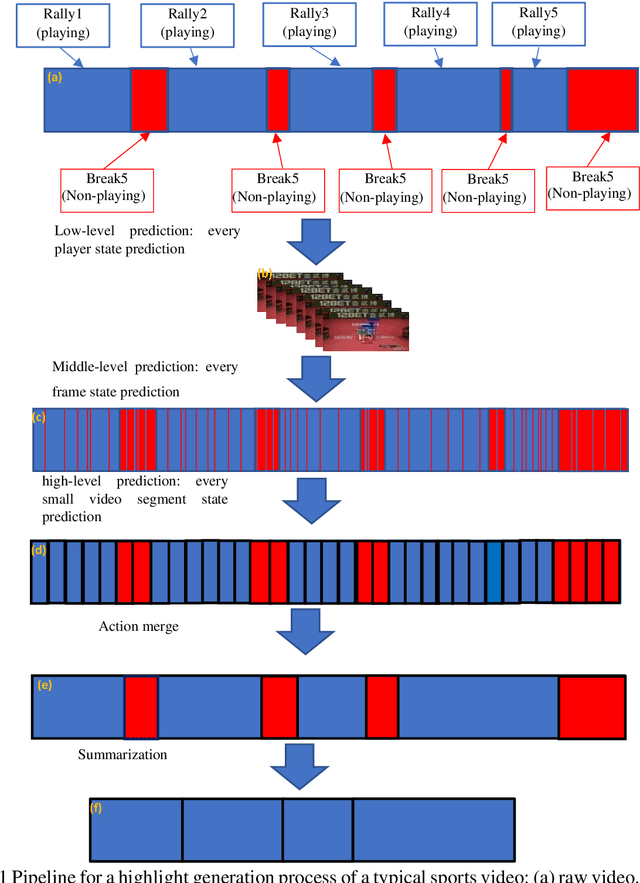


To date, machine learning for human action recognition in video has been widely implemented in sports activities. Although some studies have been successful in the past, precision is still the most significant concern. In this study, we present a high-accuracy framework to automatically clip the sports video stream by using a three-level prediction algorithm based on two classical open-source structures, i.e., YOLO-v3 and OpenPose. It is found that by using a modest amount of sports video training data, our methodology can perform sports activity highlights clipping accurately. Comparing with the previous systems, our methodology shows some advantages in accuracy. This study may serve as a new clipping system to extend the potential applications of the video summarization in sports field, as well as facilitates the development of match analysis system.
Beyond Triplet Loss: Person Re-identification with Fine-grained Difference-aware Pairwise Loss
Sep 22, 2020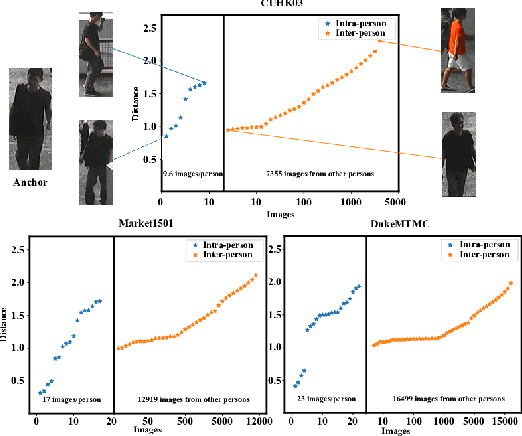
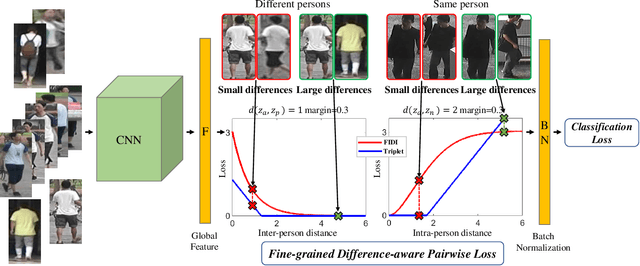
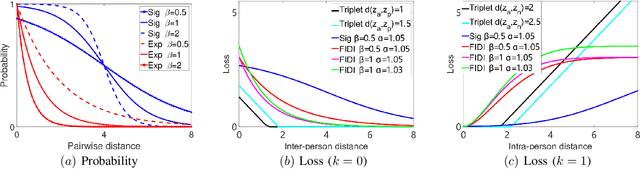

Person Re-IDentification (ReID) aims at re-identifying persons from different viewpoints across multiple cameras. Capturing the fine-grained appearance differences is often the key to accurate person ReID, because many identities can be differentiated only when looking into these fine-grained differences. However, most state-of-the-art person ReID approaches, typically driven by a triplet loss, fail to effectively learn the fine-grained features as they are focused more on differentiating large appearance differences. To address this issue, we introduce a novel pairwise loss function that enables ReID models to learn the fine-grained features by adaptively enforcing an exponential penalization on the images of small differences and a bounded penalization on the images of large differences. The proposed loss is generic and can be used as a plugin to replace the triplet loss to significantly enhance different types of state-of-the-art approaches. Experimental results on four benchmark datasets show that the proposed loss substantially outperforms a number of popular loss functions by large margins; and it also enables significantly improved data efficiency.
Self-trained Deep Ordinal Regression for End-to-End Video Anomaly Detection
Mar 15, 2020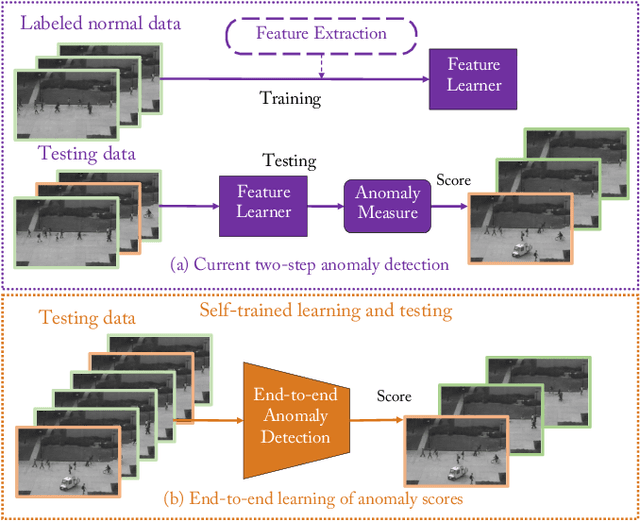
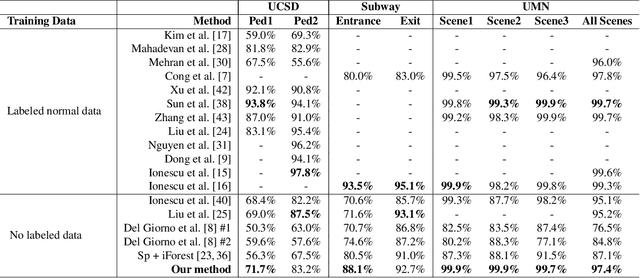
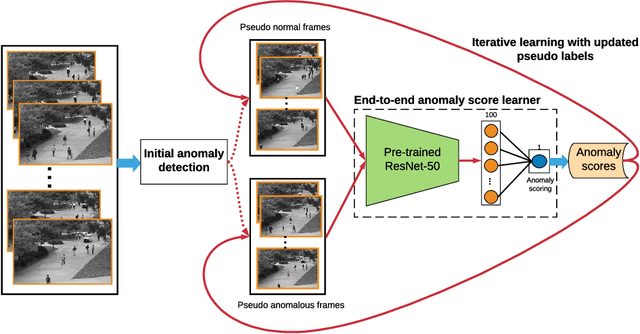
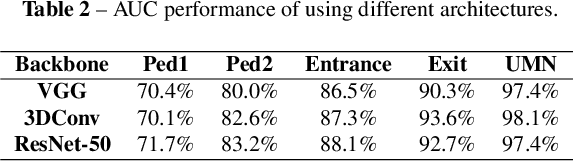
Video anomaly detection is of critical practical importance to a variety of real applications because it allows human attention to be focused on events that are likely to be of interest, in spite of an otherwise overwhelming volume of video. We show that applying self-trained deep ordinal regression to video anomaly detection overcomes two key limitations of existing methods, namely, 1) being highly dependent on manually labeled normal training data; and 2) sub-optimal feature learning. By formulating a surrogate two-class ordinal regression task we devise an end-to-end trainable video anomaly detection approach that enables joint representation learning and anomaly scoring without manually labeled normal/abnormal data. Experiments on eight real-world video scenes show that our proposed method outperforms state-of-the-art methods that require no labeled training data by a substantial margin, and enables easy and accurate localization of the identified anomalies. Furthermore, we demonstrate that our method offers effective human-in-the-loop anomaly detection which can be critical in applications where anomalies are rare and the false-negative cost is high.
Unified Multifaceted Feature Learning for Person Re-Identification
Nov 21, 2019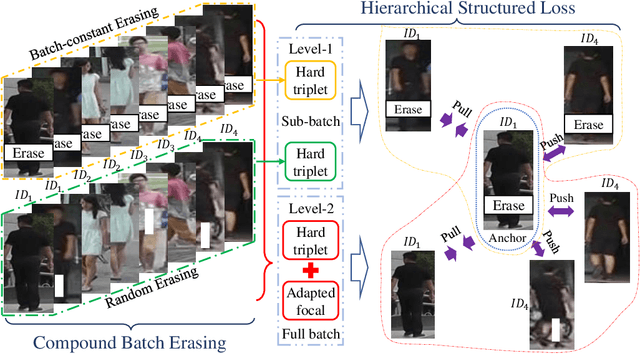
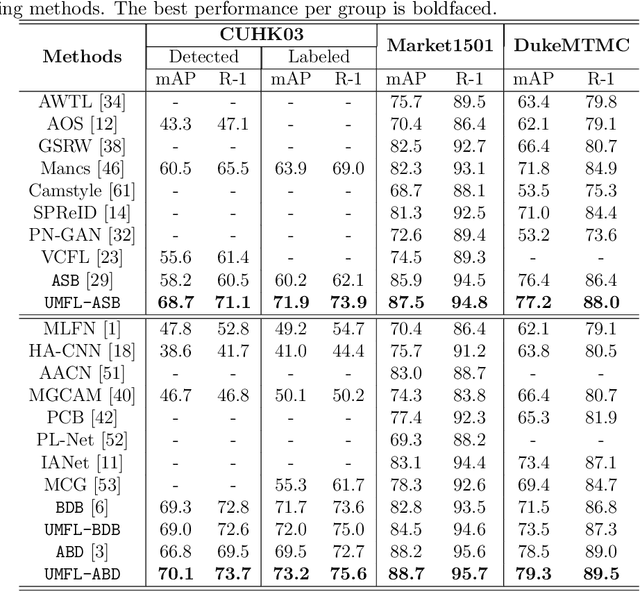
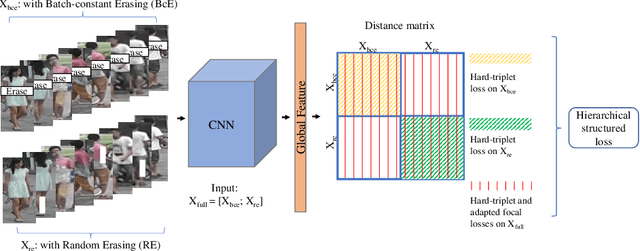
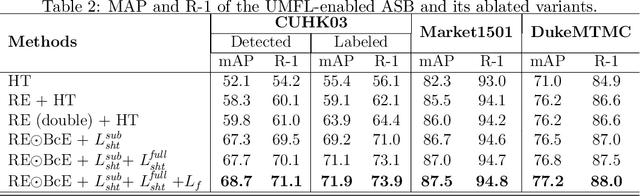
Person re-identification (ReID) aims at re-identifying persons from different viewpoints across multiple cameras, of which it is of great importance to learn multifaceted features expressed in different parts of a person, e.g., clothes, bags, and other accessories in the main body, appearance in the head, and shoes in the foot. To learn such features, existing methods are focused on the striping-based approach that builds multi-branch neural networks to learn local features in each part of the identities, with one-branch network dedicated to one part. This results in complex models with a large number of parameters. To address this issue, this paper proposes to learn the multifaceted features in a simple unified single-branch neural network. The Unified Multifaceted Feature Learning (UMFL) framework is introduced to fulfill this goal, which consists of two key collaborative modules: compound batch image erasing (including batch constant erasing and random erasing) and hierarchical structured loss. The loss structures the augmented images resulted by the two types of image erasing in a two-level hierarchy and enforces multifaceted attention to different parts. As we show in the extensive experimental results on four benchmark person ReID datasets, despite the use of significantly simplified network structure, our method performs substantially better than state-of-the-art competing methods. Our method can also effectively generalize to vehicle ReID, achieving similar improvement on two vehicle ReID datasets.