 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredal Prediction based on Relative Likelihood
May 28, 2025Predictions in the form of sets of probability distributions, so-called credal sets, provide a suitable means to represent a learner's epistemic uncertainty. In this paper, we propose a theoretically grounded approach to credal prediction based on the statistical notion of relative likelihood: The target of prediction is the set of all (conditional) probability distributions produced by the collection of plausible models, namely those models whose relative likelihood exceeds a specified threshold. This threshold has an intuitive interpretation and allows for controlling the trade-off between correctness and precision of credal predictions. We tackle the problem of approximating credal sets defined in this way by means of suitably modified ensemble learning techniques. To validate our approach, we illustrate its effectiveness by experiments on benchmark datasets demonstrating superior uncertainty representation without compromising predictive performance. We also compare our method against several state-of-the-art baselines in credal prediction.
LCDB 1.1: A Database Illustrating Learning Curves Are More Ill-Behaved Than Previously Thought
May 21, 2025



Sample-wise learning curves plot performance versus training set size. They are useful for studying scaling laws and speeding up hyperparameter tuning and model selection. Learning curves are often assumed to be well-behaved: monotone (i.e. improving with more data) and convex. By constructing the Learning Curves Database 1.1 (LCDB 1.1), a large-scale database with high-resolution learning curves, we show that learning curves are less often well-behaved than previously thought. Using statistically rigorous methods, we observe significant ill-behavior in approximately 14% of the learning curves, almost twice as much as in previous estimates. We also identify which learners are to blame and show that specific learners are more ill-behaved than others. Additionally, we demonstrate that different feature scalings rarely resolve ill-behavior. We evaluate the impact of ill-behavior on downstream tasks, such as learning curve fitting and model selection, and find it poses significant challenges, underscoring the relevance and potential of LCDB 1.1 as a challenging benchmark for future research.
Automated Phytosensing: Ozone Exposure Classification Based on Plant Electrical Signals
Dec 17, 2024In our project WatchPlant, we propose to use a decentralized network of living plants as air-quality sensors by measuring their electrophysiology to infer the environmental state, also called phytosensing. We conducted in-lab experiments exposing ivy (Hedera helix) plants to ozone, an important pollutant to monitor, and measured their electrophysiological response. However, there is no well established automated way of detecting ozone exposure in plants. We propose a generic automatic toolchain to select a high-performance subset of features and highly accurate models for plant electrophysiology. Our approach derives plant- and stimulus-generic features from the electrophysiological signal using the tsfresh library. Based on these features, we automatically select and optimize machine learning models using AutoML. We use forward feature selection to increase model performance. We show that our approach successfully classifies plant ozone exposure with accuracies of up to 94.6% on unseen data. We also show that our approach can be used for other plant species and stimuli. Our toolchain automates the development of monitoring algorithms for plants as pollutant monitors. Our results help implement significant advancements for phytosensing devices contributing to the development of cost-effective, high-density urban air monitoring systems in the future.
The Unreasonable Effectiveness Of Early Discarding After One Epoch In Neural Network Hyperparameter Optimization
Apr 05, 2024



To reach high performance with deep learning, hyperparameter optimization (HPO) is essential. This process is usually time-consuming due to costly evaluations of neural networks. Early discarding techniques limit the resources granted to unpromising candidates by observing the empirical learning curves and canceling neural network training as soon as the lack of competitiveness of a candidate becomes evident. Despite two decades of research, little is understood about the trade-off between the aggressiveness of discarding and the loss of predictive performance. Our paper studies this trade-off for several commonly used discarding techniques such as successive halving and learning curve extrapolation. Our surprising finding is that these commonly used techniques offer minimal to no added value compared to the simple strategy of discarding after a constant number of epochs of training. The chosen number of epochs depends mostly on the available compute budget. We call this approach i-Epoch (i being the constant number of epochs with which neural networks are trained) and suggest to assess the quality of early discarding techniques by comparing how their Pareto-Front (in consumed training epochs and predictive performance) complement the Pareto-Front of i-Epoch.
RRR-Net: Reusing, Reducing, and Recycling a Deep Backbone Network
Oct 02, 2023



It has become mainstream in computer vision and other machine learning domains to reuse backbone networks pre-trained on large datasets as preprocessors. Typically, the last layer is replaced by a shallow learning machine of sorts; the newly-added classification head and (optionally) deeper layers are fine-tuned on a new task. Due to its strong performance and simplicity, a common pre-trained backbone network is ResNet152.However, ResNet152 is relatively large and induces inference latency. In many cases, a compact and efficient backbone with similar performance would be preferable over a larger, slower one. This paper investigates techniques to reuse a pre-trained backbone with the objective of creating a smaller and faster model. Starting from a large ResNet152 backbone pre-trained on ImageNet, we first reduce it from 51 blocks to 5 blocks, reducing its number of parameters and FLOPs by more than 6 times, without significant performance degradation. Then, we split the model after 3 blocks into several branches, while preserving the same number of parameters and FLOPs, to create an ensemble of sub-networks to improve performance. Our experiments on a large benchmark of $40$ image classification datasets from various domains suggest that our techniques match the performance (if not better) of ``classical backbone fine-tuning'' while achieving a smaller model size and faster inference speed.
Meta-Album: Multi-domain Meta-Dataset for Few-Shot Image Classification
Feb 16, 2023We introduce Meta-Album, an image classification meta-dataset designed to facilitate few-shot learning, transfer learning, meta-learning, among other tasks. It includes 40 open datasets, each having at least 20 classes with 40 examples per class, with verified licences. They stem from diverse domains, such as ecology (fauna and flora), manufacturing (textures, vehicles), human actions, and optical character recognition, featuring various image scales (microscopic, human scales, remote sensing). All datasets are preprocessed, annotated, and formatted uniformly, and come in 3 versions (Micro $\subset$ Mini $\subset$ Extended) to match users' computational resources. We showcase the utility of the first 30 datasets on few-shot learning problems. The other 10 will be released shortly after. Meta-Album is already more diverse and larger (in number of datasets) than similar efforts, and we are committed to keep enlarging it via a series of competitions. As competitions terminate, their test data are released, thus creating a rolling benchmark, available through OpenML.org. Our website https://meta-album.github.io/ contains the source code of challenge winning methods, baseline methods, data loaders, and instructions for contributing either new datasets or algorithms to our expandable meta-dataset.
PyExperimenter: Easily distribute experiments and track results
Jan 16, 2023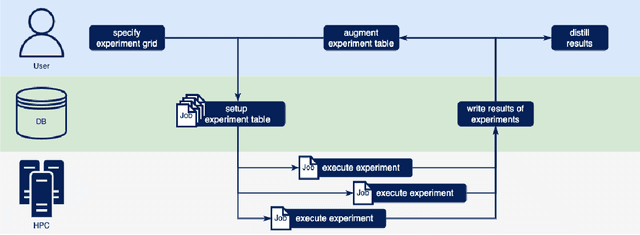
PyExperimenter is a tool to facilitate the setup, documentation, execution, and subsequent evaluation of results from an empirical study of algorithms and in particular is designed to reduce the involved manual effort significantly. It is intended to be used by researchers in the field of artificial intelligence, but is not limited to those.
Lessons learned from the NeurIPS 2021 MetaDL challenge: Backbone fine-tuning without episodic meta-learning dominates for few-shot learning image classification
Jun 15, 2022

Although deep neural networks are capable of achieving performance superior to humans on various tasks, they are notorious for requiring large amounts of data and computing resources, restricting their success to domains where such resources are available. Metalearning methods can address this problem by transferring knowledge from related tasks, thus reducing the amount of data and computing resources needed to learn new tasks. We organize the MetaDL competition series, which provide opportunities for research groups all over the world to create and experimentally assess new meta-(deep)learning solutions for real problems. In this paper, authored collaboratively between the competition organizers and the top-ranked participants, we describe the design of the competition, the datasets, the best experimental results, as well as the top-ranked methods in the NeurIPS 2021 challenge, which attracted 15 active teams who made it to the final phase (by outperforming the baseline), making over 100 code submissions during the feedback phase. The solutions of the top participants have been open-sourced. The lessons learned include that learning good representations is essential for effective transfer learning.
Learning Curves for Decision Making in Supervised Machine Learning -- A Survey
Jan 28, 2022
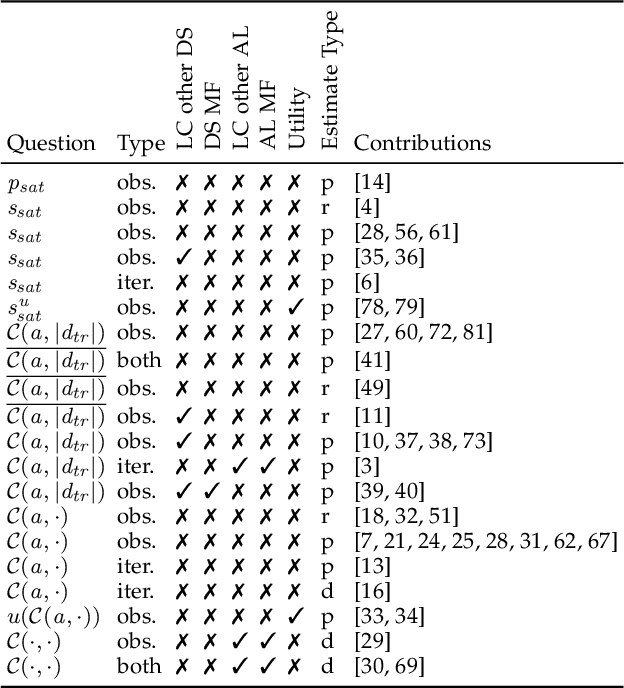


Learning curves are a concept from social sciences that has been adopted in the context of machine learning to assess the performance of a learning algorithm with respect to a certain resource, e.g. the number of training examples or the number of training iterations. Learning curves have important applications in several contexts of machine learning, most importantly for the context of data acquisition, early stopping of model training and model selection. For example, by modelling the learning curves, one can assess at an early stage whether the algorithm and hyperparameter configuration have the potential to be a suitable choice, often speeding up the algorithm selection process. A variety of approaches has been proposed to use learning curves for decision making. Some models answer the binary decision question of whether a certain algorithm at a certain budget will outperform a certain reference performance, whereas more complex models predict the entire learning curve of an algorithm. We contribute a framework that categorizes learning curve approaches using three criteria: the decision situation that they address, the intrinsic learning curve question that they answer and the type of resources that they use. We survey papers from literature and classify them into this framework.
Naive Automated Machine Learning
Nov 29, 2021


An essential task of Automated Machine Learning (AutoML) is the problem of automatically finding the pipeline with the best generalization performance on a given dataset. This problem has been addressed with sophisticated black-box optimization techniques such as Bayesian Optimization, Grammar-Based Genetic Algorithms, and tree search algorithms. Most of the current approaches are motivated by the assumption that optimizing the components of a pipeline in isolation may yield sub-optimal results. We present Naive AutoML, an approach that does precisely this: It optimizes the different algorithms of a pre-defined pipeline scheme in isolation. The finally returned pipeline is obtained by just taking the best algorithm of each slot. The isolated optimization leads to substantially reduced search spaces, and, surprisingly, this approach yields comparable and sometimes even better performance than current state-of-the-art optimizers.