 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Exploration and Co-Exploitation via Shared Structure in Multi-Task Bandits
Dec 14, 2025We propose a novel Bayesian framework for efficient exploration in contextual multi-task multi-armed bandit settings, where the context is only observed partially and dependencies between reward distributions are induced by latent context variables. In order to exploit these structural dependencies, our approach integrates observations across all tasks and learns a global joint distribution, while still allowing personalised inference for new tasks. In this regard, we identify two key sources of epistemic uncertainty, namely structural uncertainty in the latent reward dependencies across arms and tasks, and user-specific uncertainty due to incomplete context and limited interaction history. To put our method into practice, we represent the joint distribution over tasks and rewards using a particle-based approximation of a log-density Gaussian process. This representation enables flexible, data-driven discovery of both inter-arm and inter-task dependencies without prior assumptions on the latent variables. Empirically, we demonstrate that our method outperforms baselines such as hierarchical model bandits, especially in settings with model misspecification or complex latent heterogeneity.
Probabilistic Scoring Lists for Interpretable Machine Learning
Jul 31, 2024



A scoring system is a simple decision model that checks a set of features, adds a certain number of points to a total score for each feature that is satisfied, and finally makes a decision by comparing the total score to a threshold. Scoring systems have a long history of active use in safety-critical domains such as healthcare and justice, where they provide guidance for making objective and accurate decisions. Given their genuine interpretability, the idea of learning scoring systems from data is obviously appealing from the perspective of explainable AI. In this paper, we propose a practically motivated extension of scoring systems called probabilistic scoring lists (PSL), as well as a method for learning PSLs from data. Instead of making a deterministic decision, a PSL represents uncertainty in the form of probability distributions, or, more generally, probability intervals. Moreover, in the spirit of decision lists, a PSL evaluates features one by one and stops as soon as a decision can be made with enough confidence. To evaluate our approach, we conduct a case study in the medical domain.
PyExperimenter: Easily distribute experiments and track results
Jan 16, 2023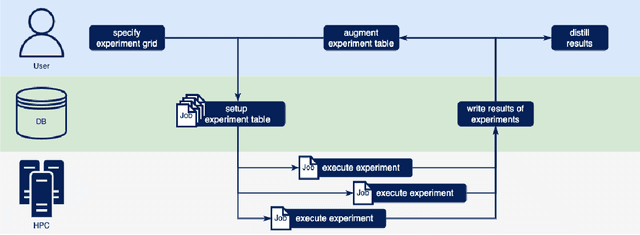
PyExperimenter is a tool to facilitate the setup, documentation, execution, and subsequent evaluation of results from an empirical study of algorithms and in particular is designed to reduce the involved manual effort significantly. It is intended to be used by researchers in the field of artificial intelligence, but is not limited to those.
HARRIS: Hybrid Ranking and Regression Forests for Algorithm Selection
Oct 31, 2022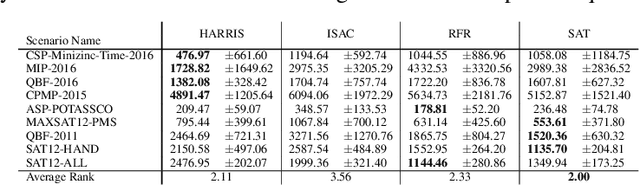
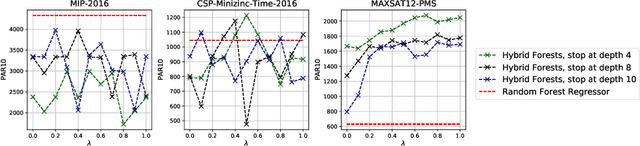

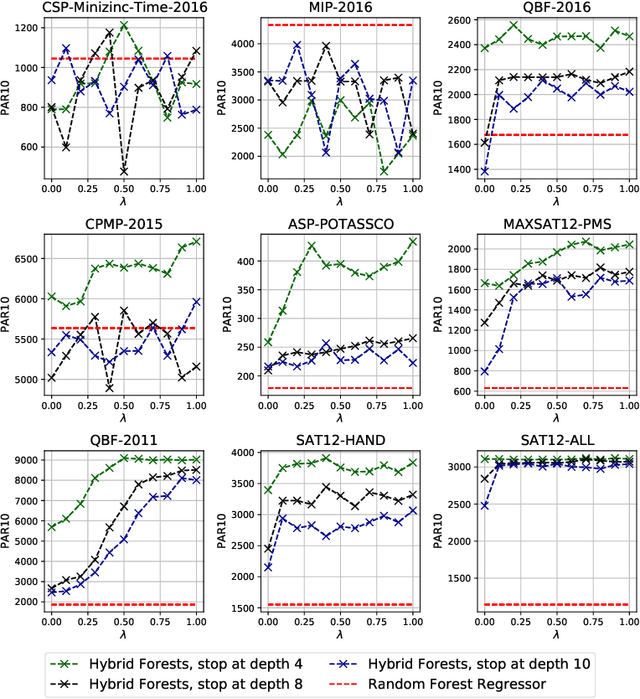
It is well known that different algorithms perform differently well on an instance of an algorithmic problem, motivating algorithm selection (AS): Given an instance of an algorithmic problem, which is the most suitable algorithm to solve it? As such, the AS problem has received considerable attention resulting in various approaches - many of which either solve a regression or ranking problem under the hood. Although both of these formulations yield very natural ways to tackle AS, they have considerable weaknesses. On the one hand, correctly predicting the performance of an algorithm on an instance is a sufficient, but not a necessary condition to produce a correct ranking over algorithms and in particular ranking the best algorithm first. On the other hand, classical ranking approaches often do not account for concrete performance values available in the training data, but only leverage rankings composed from such data. We propose HARRIS- Hybrid rAnking and RegRessIon foreSts - a new algorithm selector leveraging special forests, combining the strengths of both approaches while alleviating their weaknesses. HARRIS' decisions are based on a forest model, whose trees are created based on splits optimized on a hybrid ranking and regression loss function. As our preliminary experimental study on ASLib shows, HARRIS improves over standard algorithm selection approaches on some scenarios showing that combining ranking and regression in trees is indeed promising for AS.
Towards Green Automated Machine Learning: Status Quo and Future Directions
Nov 10, 2021
Automated machine learning (AutoML) strives for the automatic configuration of machine learning algorithms and their composition into an overall (software) solution - a machine learning pipeline - tailored to the learning task (dataset) at hand. Over the last decade, AutoML has become a hot research topic with hundreds of contributions. While AutoML offers many prospects, it is also known to be quite resource-intensive, which is one of its major points of criticism. The primary cause for a high resource consumption is that many approaches rely on the (costly) evaluation of many ML pipelines while searching for good candidates. This problem is amplified in the context of research on AutoML methods, due to large scale experiments conducted with many datasets and approaches, each of them being run with several repetitions to rule out random effects. In the spirit of recent work on Green AI, this paper is written in an attempt to raise the awareness of AutoML researchers for the problem and to elaborate on possible remedies. To this end, we identify four categories of actions the community may take towards more sustainable research on AutoML, namely approach design, benchmarking, research incentives, and transparency.