 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Attention Search Linear: Towards Adaptive Token-Level Hybrid Attention Models
Feb 03, 2026The quadratic computational complexity of softmax transformers has become a bottleneck in long-context scenarios. In contrast, linear attention model families provide a promising direction towards a more efficient sequential model. These linear attention models compress past KV values into a single hidden state, thereby efficiently reducing complexity during both training and inference. However, their expressivity remains limited by the size of their hidden state. Previous work proposed interleaving softmax and linear attention layers to reduce computational complexity while preserving expressivity. Nevertheless, the efficiency of these models remains bottlenecked by their softmax attention layers. In this paper, we propose Neural Attention Search Linear (NAtS-L), a framework that applies both linear attention and softmax attention operations within the same layer on different tokens. NAtS-L automatically determines whether a token can be handled by a linear attention model, i.e., tokens that have only short-term impact and can be encoded into fixed-size hidden states, or require softmax attention, i.e., tokens that contain information related to long-term retrieval and need to be preserved for future queries. By searching for optimal Gated DeltaNet and softmax attention combinations across tokens, we show that NAtS-L provides a strong yet efficient token-level hybrid architecture.
Growing with Experience: Growing Neural Networks in Deep Reinforcement Learning
Jun 13, 2025While increasingly large models have revolutionized much of the machine learning landscape, training even mid-sized networks for Reinforcement Learning (RL) is still proving to be a struggle. This, however, severely limits the complexity of policies we are able to learn. To enable increased network capacity while maintaining network trainability, we propose GrowNN, a simple yet effective method that utilizes progressive network growth during training. We start training a small network to learn an initial policy. Then we add layers without changing the encoded function. Subsequent updates can utilize the added layers to learn a more expressive policy, adding capacity as the policy's complexity increases. GrowNN can be seamlessly integrated into most existing RL agents. Our experiments on MiniHack and Mujoco show improved agent performance, with incrementally GrowNN-deeper networks outperforming their respective static counterparts of the same size by up to 48% on MiniHack Room and 72% on Ant.
PyExperimenter: Easily distribute experiments and track results
Jan 16, 2023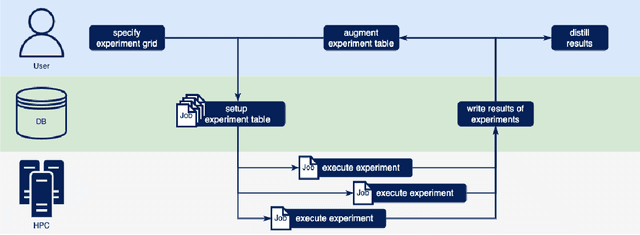
PyExperimenter is a tool to facilitate the setup, documentation, execution, and subsequent evaluation of results from an empirical study of algorithms and in particular is designed to reduce the involved manual effort significantly. It is intended to be used by researchers in the field of artificial intelligence, but is not limited to those.
HARRIS: Hybrid Ranking and Regression Forests for Algorithm Selection
Oct 31, 2022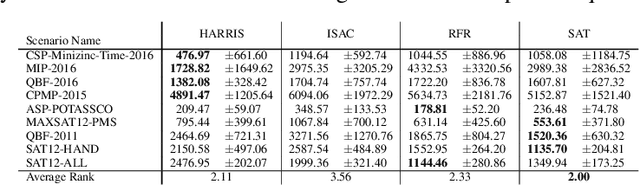
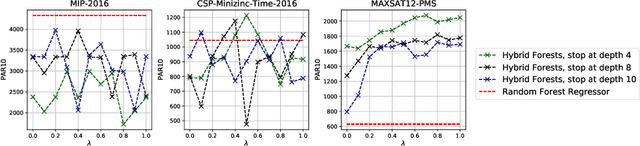

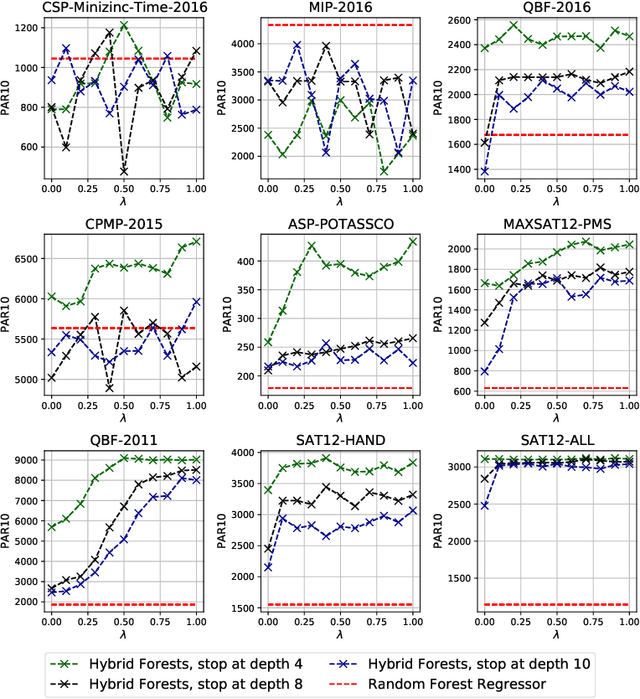
It is well known that different algorithms perform differently well on an instance of an algorithmic problem, motivating algorithm selection (AS): Given an instance of an algorithmic problem, which is the most suitable algorithm to solve it? As such, the AS problem has received considerable attention resulting in various approaches - many of which either solve a regression or ranking problem under the hood. Although both of these formulations yield very natural ways to tackle AS, they have considerable weaknesses. On the one hand, correctly predicting the performance of an algorithm on an instance is a sufficient, but not a necessary condition to produce a correct ranking over algorithms and in particular ranking the best algorithm first. On the other hand, classical ranking approaches often do not account for concrete performance values available in the training data, but only leverage rankings composed from such data. We propose HARRIS- Hybrid rAnking and RegRessIon foreSts - a new algorithm selector leveraging special forests, combining the strengths of both approaches while alleviating their weaknesses. HARRIS' decisions are based on a forest model, whose trees are created based on splits optimized on a hybrid ranking and regression loss function. As our preliminary experimental study on ASLib shows, HARRIS improves over standard algorithm selection approaches on some scenarios showing that combining ranking and regression in trees is indeed promising for AS.