 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Grounded Automated Prompt Optimization for LLM Game Agents
Jun 16, 2026LLM agents in interactive environments are highly sensitive to their prompts, yet prompt engineering remains a manual, task-specific process. We introduce an automated prompt optimization framework for LLM agents that decomposes the observation-to-action pipeline into a goal-conditioned descriptor agent and an action selection agent, and iteratively refines each module's prompt through an LLM-driven evolutionary loop guided by environment returns. We propose a behavior analyzer to attribute episode outcomes to specific prompt components, and a mutator to propose targeted revisions to the prompt, before validating them through environment rollouts. We evaluate on all five BabyAI tasks in the BALROG benchmark, comparing our pipeline against BALROG's RobustCoTAgent under both plain and guided prompt initializations. Optimization improves performance consistently across tasks and conditions, without requiring updates to the model weights. On PutNext, a multi-step coordination task where the RobustCoTAgent achieves 0% success, our framework reaches up to 72.5% success rate using the same underlying LLM with optimized prompts. These results suggest that a multi-agent framework, combined with automatic prompt optimization, enhances LLMs without the need for fine-tuning or extensive human supervision.
Learning to Play Blackjack: A Curriculum Learning Perspective
Apr 02, 2026Reinforcement Learning (RL) agents often struggle with efficiency and performance in complex environments. We propose a novel framework that uses a Large Language Model (LLM) to dynamically generate a curriculum over available actions, enabling the agent to incorporate each action individually. We apply this framework to the game of Blackjack, where the LLM creates a multi-stage training path that progressively introduces complex actions to a Tabular Q-Learning and a Deep Q-Network (DQN) agent. Our evaluation in a realistic 8-deck simulation over 10 independent runs demonstrates significant performance gains over standard training methods. The curriculum-based approach increases the DQN agent's average win rate from 43.97% to 47.41%, reduces the average bust rate from 32.9% to 28.0%, and accelerates the overall workflow by over 74%, with the agent's full training completing faster than the baseline's evaluation phase alone. These results validate that LLM-guided curricula can build more effective, robust, and efficient RL agents.
Best Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025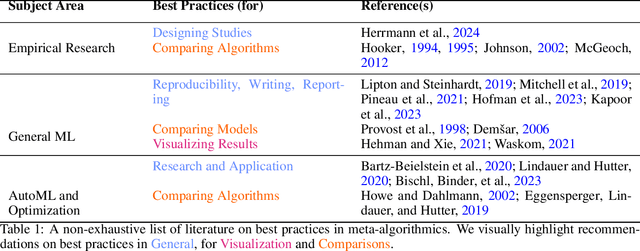
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Revisiting Learning Rate Control
Jul 02, 2025The learning rate is one of the most important hyperparameters in deep learning, and how to control it is an active area within both AutoML and deep learning research. Approaches for learning rate control span from classic optimization to online scheduling based on gradient statistics. This paper compares paradigms to assess the current state of learning rate control. We find that methods from multi-fidelity hyperparameter optimization, fixed-hyperparameter schedules, and hyperparameter-free learning often perform very well on selected deep learning tasks but are not reliable across settings. This highlights the need for algorithm selection methods in learning rate control, which have been neglected so far by both the AutoML and deep learning communities. We also observe a trend of hyperparameter optimization approaches becoming less effective as models and tasks grow in complexity, even when combined with multi-fidelity approaches for more expensive model trainings. A focus on more relevant test tasks and new promising directions like finetunable methods and meta-learning will enable the AutoML community to significantly strengthen its impact on this crucial factor in deep learning.
Growing with Experience: Growing Neural Networks in Deep Reinforcement Learning
Jun 13, 2025While increasingly large models have revolutionized much of the machine learning landscape, training even mid-sized networks for Reinforcement Learning (RL) is still proving to be a struggle. This, however, severely limits the complexity of policies we are able to learn. To enable increased network capacity while maintaining network trainability, we propose GrowNN, a simple yet effective method that utilizes progressive network growth during training. We start training a small network to learn an initial policy. Then we add layers without changing the encoded function. Subsequent updates can utilize the added layers to learn a more expressive policy, adding capacity as the policy's complexity increases. GrowNN can be seamlessly integrated into most existing RL agents. Our experiments on MiniHack and Mujoco show improved agent performance, with incrementally GrowNN-deeper networks outperforming their respective static counterparts of the same size by up to 48% on MiniHack Room and 72% on Ant.
Task Scheduling & Forgetting in Multi-Task Reinforcement Learning
Mar 03, 2025Reinforcement learning (RL) agents can forget tasks they have previously been trained on. There is a rich body of work on such forgetting effects in humans. Therefore we look for commonalities in the forgetting behavior of humans and RL agents across tasks and test the viability of forgetting prevention measures from learning theory in RL. We find that in many cases, RL agents exhibit forgetting curves similar to those of humans. Methods like Leitner or SuperMemo have been shown to be effective at counteracting human forgetting, but we demonstrate they do not transfer as well to RL. We identify a likely cause: asymmetrical learning and retention patterns between tasks that cannot be captured by retention-based or performance-based curriculum strategies.
ARLBench: Flexible and Efficient Benchmarking for Hyperparameter Optimization in Reinforcement Learning
Sep 27, 2024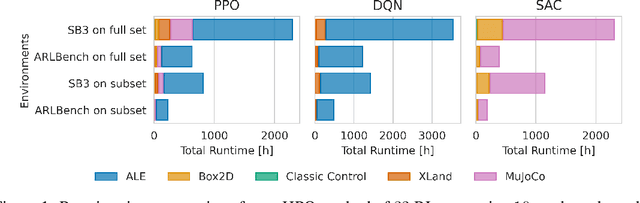


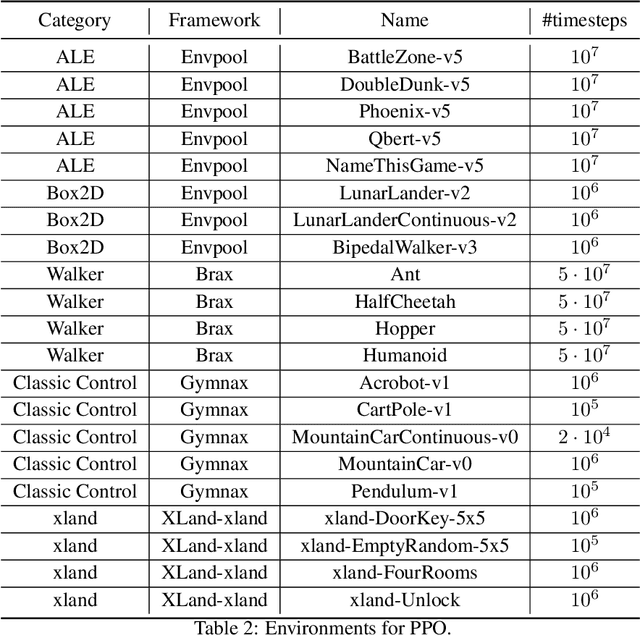
Hyperparameters are a critical factor in reliably training well-performing reinforcement learning (RL) agents. Unfortunately, developing and evaluating automated approaches for tuning such hyperparameters is both costly and time-consuming. As a result, such approaches are often only evaluated on a single domain or algorithm, making comparisons difficult and limiting insights into their generalizability. We propose ARLBench, a benchmark for hyperparameter optimization (HPO) in RL that allows comparisons of diverse HPO approaches while being highly efficient in evaluation. To enable research into HPO in RL, even in settings with low compute resources, we select a representative subset of HPO tasks spanning a variety of algorithm and environment combinations. This selection allows for generating a performance profile of an automated RL (AutoRL) method using only a fraction of the compute previously necessary, enabling a broader range of researchers to work on HPO in RL. With the extensive and large-scale dataset on hyperparameter landscapes that our selection is based on, ARLBench is an efficient, flexible, and future-oriented foundation for research on AutoRL. Both the benchmark and the dataset are available at https://github.com/automl/arlbench.
* Accepted at the 17th European Workshop on Reinforcement Learning
AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks
Jun 13, 2023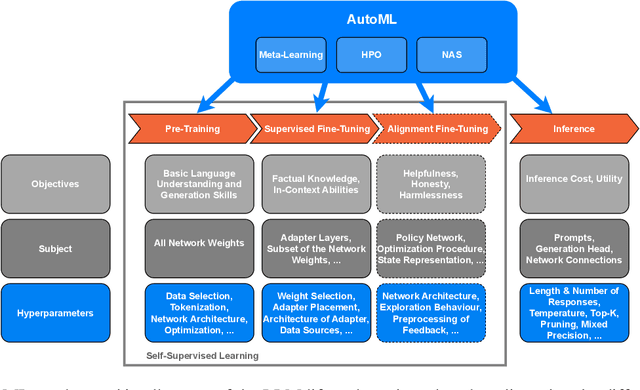
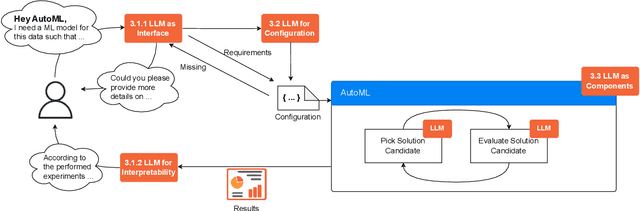
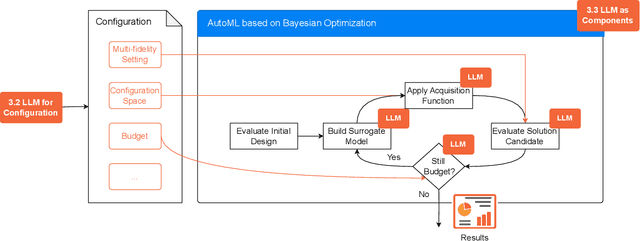
The fields of both Natural Language Processing (NLP) and Automated Machine Learning (AutoML) have achieved remarkable results over the past years. In NLP, especially Large Language Models (LLMs) have experienced a rapid series of breakthroughs very recently. We envision that the two fields can radically push the boundaries of each other through tight integration. To showcase this vision, we explore the potential of a symbiotic relationship between AutoML and LLMs, shedding light on how they can benefit each other. In particular, we investigate both the opportunities to enhance AutoML approaches with LLMs from different perspectives and the challenges of leveraging AutoML to further improve LLMs. To this end, we survey existing work, and we critically assess risks. We strongly believe that the integration of the two fields has the potential to disrupt both fields, NLP and AutoML. By highlighting conceivable synergies, but also risks, we aim to foster further exploration at the intersection of AutoML and LLMs.
Hyperparameters in Reinforcement Learning and How To Tune Them
Jun 02, 2023In order to improve reproducibility, deep reinforcement learning (RL) has been adopting better scientific practices such as standardized evaluation metrics and reporting. However, the process of hyperparameter optimization still varies widely across papers, which makes it challenging to compare RL algorithms fairly. In this paper, we show that hyperparameter choices in RL can significantly affect the agent's final performance and sample efficiency, and that the hyperparameter landscape can strongly depend on the tuning seed which may lead to overfitting. We therefore propose adopting established best practices from AutoML, such as the separation of tuning and testing seeds, as well as principled hyperparameter optimization (HPO) across a broad search space. We support this by comparing multiple state-of-the-art HPO tools on a range of RL algorithms and environments to their hand-tuned counterparts, demonstrating that HPO approaches often have higher performance and lower compute overhead. As a result of our findings, we recommend a set of best practices for the RL community, which should result in stronger empirical results with fewer computational costs, better reproducibility, and thus faster progress. In order to encourage the adoption of these practices, we provide plug-and-play implementations of the tuning algorithms used in this paper at https://github.com/facebookresearch/how-to-autorl.
Hyperparameters in Contextual RL are Highly Situational
Dec 21, 2022Although Reinforcement Learning (RL) has shown impressive results in games and simulation, real-world application of RL suffers from its instability under changing environment conditions and hyperparameters. We give a first impression of the extent of this instability by showing that the hyperparameters found by automatic hyperparameter optimization (HPO) methods are not only dependent on the problem at hand, but even on how well the state describes the environment dynamics. Specifically, we show that agents in contextual RL require different hyperparameters if they are shown how environmental factors change. In addition, finding adequate hyperparameter configurations is not equally easy for both settings, further highlighting the need for research into how hyperparameters influence learning and generalization in RL.