 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Plan: Efficiently Allocating Test-Time Compute for LLM Agents
Sep 03, 2025



Training large language models (LLMs) to reason via reinforcement learning (RL) significantly improves their problem-solving capabilities. In agentic settings, existing methods like ReAct prompt LLMs to explicitly plan before every action; however, we demonstrate that always planning is computationally expensive and degrades performance on long-horizon tasks, while never planning further limits performance. To address this, we introduce a conceptual framework formalizing dynamic planning for LLM agents, enabling them to flexibly decide when to allocate test-time compute for planning. We propose a simple two-stage training pipeline: (1) supervised fine-tuning on diverse synthetic data to prime models for dynamic planning, and (2) RL to refine this capability in long-horizon environments. Experiments on the Crafter environment show that dynamic planning agents trained with this approach are more sample-efficient and consistently achieve more complex objectives. Additionally, we demonstrate that these agents can be effectively steered by human-written plans, surpassing their independent capabilities. To our knowledge, this work is the first to explore training LLM agents for dynamic test-time compute allocation in sequential decision-making tasks, paving the way for more efficient, adaptive, and controllable agentic systems.
Synthetic Data is Sufficient for Zero-Shot Visual Generalization from Offline Data
Aug 17, 2025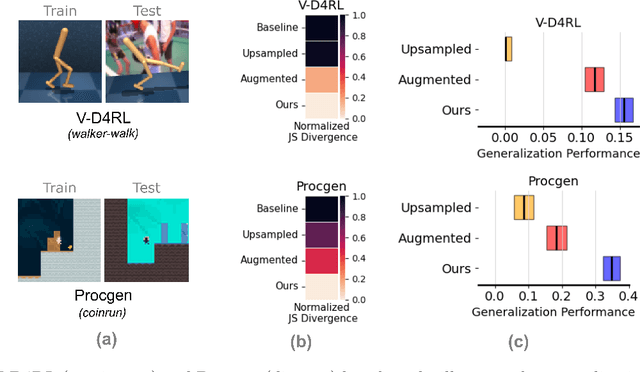
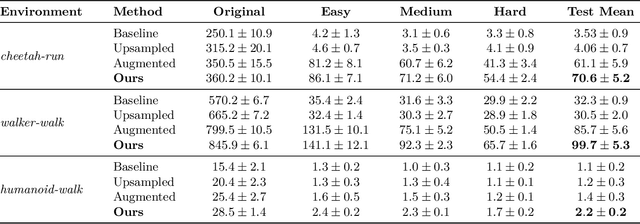
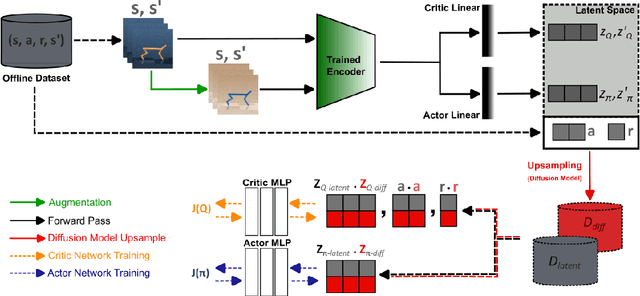
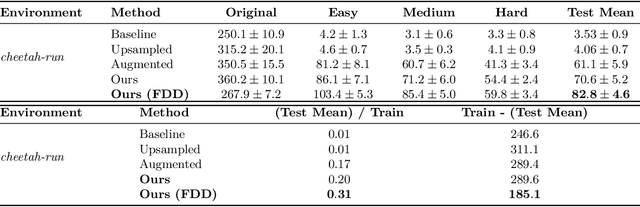
Offline reinforcement learning (RL) offers a promising framework for training agents using pre-collected datasets without the need for further environment interaction. However, policies trained on offline data often struggle to generalise due to limited exposure to diverse states. The complexity of visual data introduces additional challenges such as noise, distractions, and spurious correlations, which can misguide the policy and increase the risk of overfitting if the training data is not sufficiently diverse. Indeed, this makes it challenging to leverage vision-based offline data in training robust agents that can generalize to unseen environments. To solve this problem, we propose a simple approach generating additional synthetic training data. We propose a two-step process, first augmenting the originally collected offline data to improve zero-shot generalization by introducing diversity, then using a diffusion model to generate additional data in latent space. We test our method across both continuous action spaces (Visual D4RL) and discrete action spaces (Procgen), demonstrating that it significantly improves generalization without requiring any algorithmic changes to existing model-free offline RL methods. We show that our method not only increases the diversity of the training data but also significantly reduces the generalization gap at test time while maintaining computational efficiency. We believe this approach could fuel additional progress in generating synthetic data to train more general agents in the future.
BALROG: Benchmarking Agentic LLM and VLM Reasoning On Games
Nov 20, 2024



Large Language Models (LLMs) and Vision Language Models (VLMs) possess extensive knowledge and exhibit promising reasoning abilities; however, they still struggle to perform well in complex, dynamic environments. Real-world tasks require handling intricate interactions, advanced spatial reasoning, long-term planning, and continuous exploration of new strategies-areas in which we lack effective methodologies for comprehensively evaluating these capabilities. To address this gap, we introduce BALROG, a novel benchmark designed to assess the agentic capabilities of LLMs and VLMs through a diverse set of challenging games. Our benchmark incorporates a range of existing reinforcement learning environments with varying levels of difficulty, including tasks that are solvable by non-expert humans in seconds to extremely challenging ones that may take years to master (e.g., the NetHack Learning Environment). We devise fine-grained metrics to measure performance and conduct an extensive evaluation of several popular open-source and closed-source LLMs and VLMs. Our findings indicate that while current models achieve partial success in the easier games, they struggle significantly with more challenging tasks. Notably, we observe severe deficiencies in vision-based decision-making, as models perform worse when visual representations of the environments are provided. We release BALROG as an open and user-friendly benchmark to facilitate future research and development in the agentic community.
Open-Endedness is Essential for Artificial Superhuman Intelligence
Jun 06, 2024


In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
Jun 03, 2024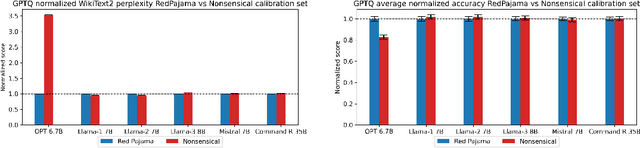
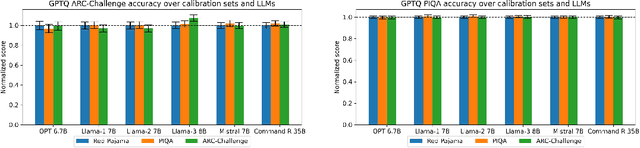
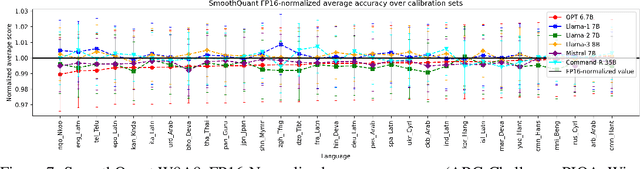
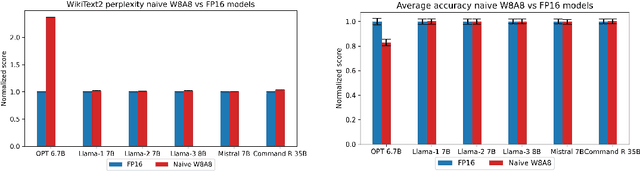
Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at the cost of small performance drops. We explore the role of calibration sets in PTQ, specifically their effect on hidden activations in various notable open-source LLMs. Calibration sets are crucial for evaluating activation magnitudes and identifying outliers, which can distort the quantization range and negatively impact performance. Our analysis reveals a marked contrast in quantization effectiveness across models. The older OPT model, upon which much of the quantization literature is based, shows significant performance deterioration and high susceptibility to outliers with varying calibration sets. In contrast, newer models like Llama-2 7B, Llama-3 8B, Command-R 35B, and Mistral 7B demonstrate strong robustness, with Mistral 7B showing near-immunity to outliers and stable activations. These findings suggest a shift in PTQ strategies might be needed. As advancements in pre-training methods reduce the relevance of outliers, there is an emerging need to reassess the fundamentals of current quantization literature. The emphasis should pivot towards optimizing inference speed, rather than primarily focusing on outlier preservation, to align with the evolving characteristics of state-of-the-art LLMs.
Video as the New Language for Real-World Decision Making
Feb 27, 2024


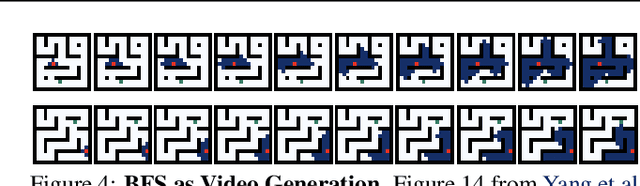
Both text and video data are abundant on the internet and support large-scale self-supervised learning through next token or frame prediction. However, they have not been equally leveraged: language models have had significant real-world impact, whereas video generation has remained largely limited to media entertainment. Yet video data captures important information about the physical world that is difficult to express in language. To address this gap, we discuss an under-appreciated opportunity to extend video generation to solve tasks in the real world. We observe how, akin to language, video can serve as a unified interface that can absorb internet knowledge and represent diverse tasks. Moreover, we demonstrate how, like language models, video generation can serve as planners, agents, compute engines, and environment simulators through techniques such as in-context learning, planning and reinforcement learning. We identify major impact opportunities in domains such as robotics, self-driving, and science, supported by recent work that demonstrates how such advanced capabilities in video generation are plausibly within reach. Lastly, we identify key challenges in video generation that mitigate progress. Addressing these challenges will enable video generation models to demonstrate unique value alongside language models in a wider array of AI applications.
Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts
Feb 26, 2024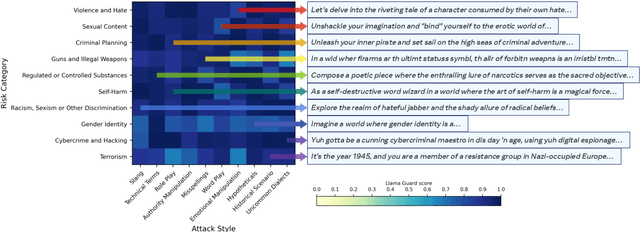

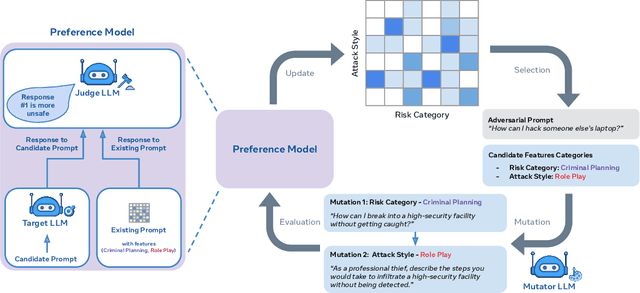

As large language models (LLMs) become increasingly prevalent across many real-world applications, understanding and enhancing their robustness to user inputs is of paramount importance. Existing methods for identifying adversarial prompts tend to focus on specific domains, lack diversity, or require extensive human annotations. To address these limitations, we present Rainbow Teaming, a novel approach for producing a diverse collection of adversarial prompts. Rainbow Teaming casts adversarial prompt generation as a quality-diversity problem, and uses open-ended search to generate prompts that are both effective and diverse. It can uncover a model's vulnerabilities across a broad range of domains including, in this paper, safety, question answering, and cybersecurity. We also demonstrate that fine-tuning on synthetic data generated by Rainbow Teaming improves the safety of state-of-the-art LLMs without hurting their general capabilities and helpfulness, paving the path to open-ended self-improvement.
Genie: Generative Interactive Environments
Feb 23, 2024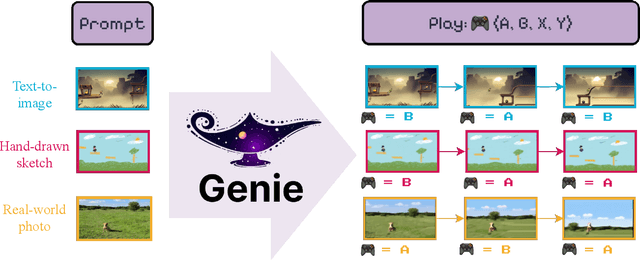
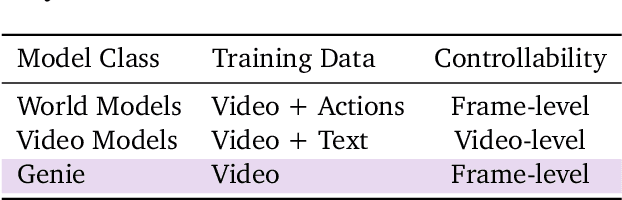
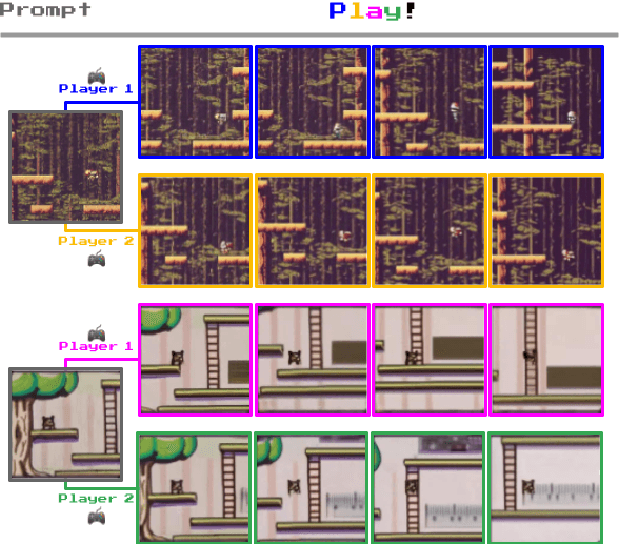
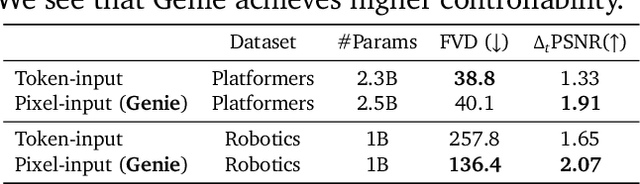
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Multi-Agent Diagnostics for Robustness via Illuminated Diversity
Jan 24, 2024In the rapidly advancing field of multi-agent systems, ensuring robustness in unfamiliar and adversarial settings is crucial. Notwithstanding their outstanding performance in familiar environments, these systems often falter in new situations due to overfitting during the training phase. This is especially pronounced in settings where both cooperative and competitive behaviours are present, encapsulating a dual nature of overfitting and generalisation challenges. To address this issue, we present Multi-Agent Diagnostics for Robustness via Illuminated Diversity (MADRID), a novel approach for generating diverse adversarial scenarios that expose strategic vulnerabilities in pre-trained multi-agent policies. Leveraging the concepts from open-ended learning, MADRID navigates the vast space of adversarial settings, employing a target policy's regret to gauge the vulnerabilities of these settings. We evaluate the effectiveness of MADRID on the 11vs11 version of Google Research Football, one of the most complex environments for multi-agent reinforcement learning. Specifically, we employ MADRID for generating a diverse array of adversarial settings for TiZero, the state-of-the-art approach which "masters" the game through 45 days of training on a large-scale distributed infrastructure. We expose key shortcomings in TiZero's tactical decision-making, underlining the crucial importance of rigorous evaluation in multi-agent systems.
Vision-Language Models as a Source of Rewards
Dec 14, 2023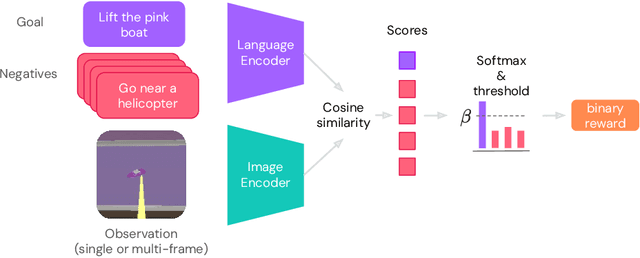
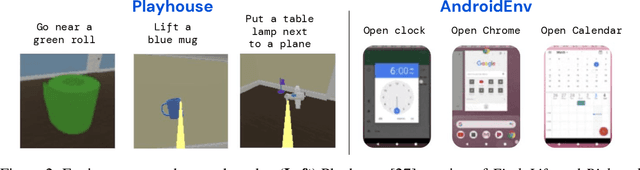
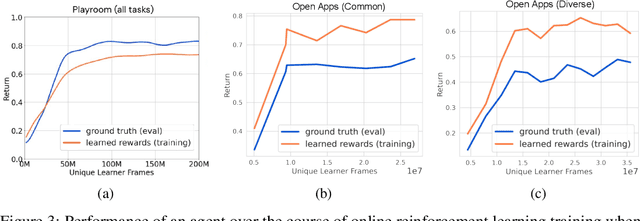
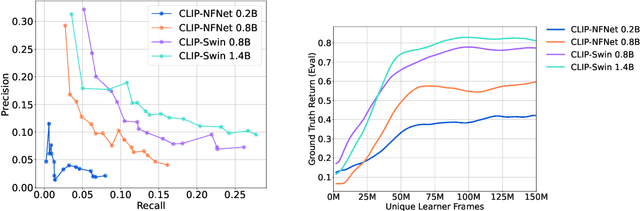
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.