 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Models as a Source of Rewards
Dec 14, 2023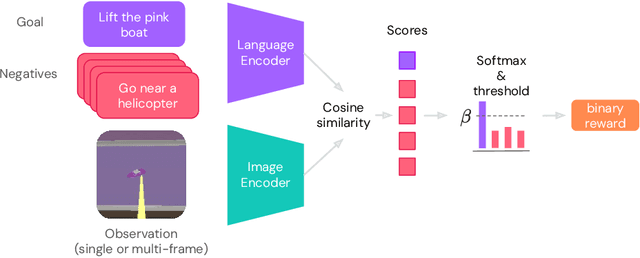
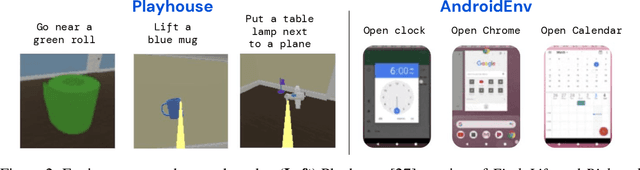
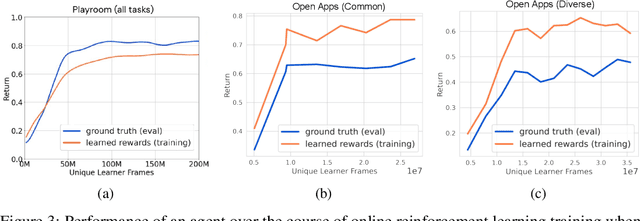
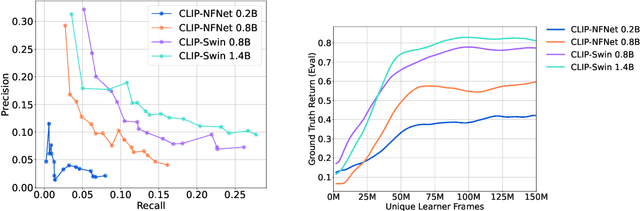
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
Optimism and Adaptivity in Policy Optimization
Jun 18, 2023We work towards a unifying paradigm for accelerating policy optimization methods in reinforcement learning (RL) through \emph{optimism} \& \emph{adaptivity}. Leveraging the deep connection between policy iteration and policy gradient methods, we recast seemingly unrelated policy optimization algorithms as the repeated application of two interleaving steps (i) an \emph{optimistic policy improvement operator} maps a prior policy $\pi_t$ to a hypothesis $\pi_{t+1}$ using a \emph{gradient ascent prediction}, followed by (ii) a \emph{hindsight adaptation} of the optimistic prediction based on a partial evaluation of the performance of $\pi_{t+1}$. We use this shared lens to jointly express other well-known algorithms, including soft and optimistic policy iteration, natural actor-critic methods, model-based policy improvement based on forward search, and meta-learning algorithms. By doing so, we shed light on collective theoretical properties related to acceleration via optimism \& adaptivity. Building on these insights, we design an \emph{adaptive \& optimistic policy gradient} algorithm via meta-gradient learning, and empirically highlight several design choices pertaining to optimism, in an illustrative task.
Discovering Attention-Based Genetic Algorithms via Meta-Black-Box Optimization
Apr 08, 2023



Genetic algorithms constitute a family of black-box optimization algorithms, which take inspiration from the principles of biological evolution. While they provide a general-purpose tool for optimization, their particular instantiations can be heuristic and motivated by loose biological intuition. In this work we explore a fundamentally different approach: Given a sufficiently flexible parametrization of the genetic operators, we discover entirely new genetic algorithms in a data-driven fashion. More specifically, we parametrize selection and mutation rate adaptation as cross- and self-attention modules and use Meta-Black-Box-Optimization to evolve their parameters on a set of diverse optimization tasks. The resulting Learned Genetic Algorithm outperforms state-of-the-art adaptive baseline genetic algorithms and generalizes far beyond its meta-training settings. The learned algorithm can be applied to previously unseen optimization problems, search dimensions & evaluation budgets. We conduct extensive analysis of the discovered operators and provide ablation experiments, which highlight the benefits of flexible module parametrization and the ability to transfer (`plug-in') the learned operators to conventional genetic algorithms.
ReLOAD: Reinforcement Learning with Optimistic Ascent-Descent for Last-Iterate Convergence in Constrained MDPs
Feb 02, 2023
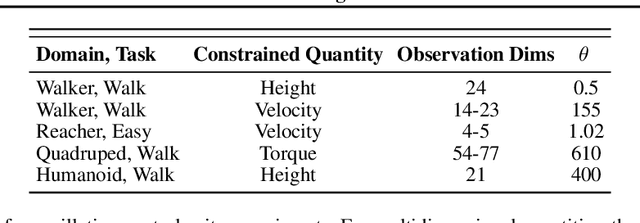
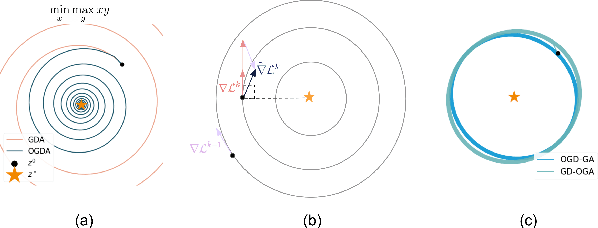
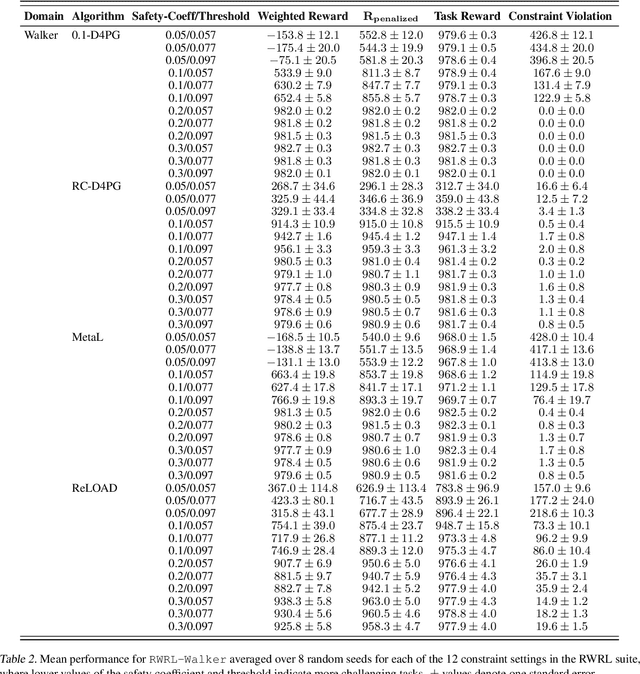
In recent years, Reinforcement Learning (RL) has been applied to real-world problems with increasing success. Such applications often require to put constraints on the agent's behavior. Existing algorithms for constrained RL (CRL) rely on gradient descent-ascent, but this approach comes with a caveat. While these algorithms are guaranteed to converge on average, they do not guarantee last-iterate convergence, i.e., the current policy of the agent may never converge to the optimal solution. In practice, it is often observed that the policy alternates between satisfying the constraints and maximizing the reward, rarely accomplishing both objectives simultaneously. Here, we address this problem by introducing Reinforcement Learning with Optimistic Ascent-Descent (ReLOAD), a principled CRL method with guaranteed last-iterate convergence. We demonstrate its empirical effectiveness on a wide variety of CRL problems including discrete MDPs and continuous control. In the process we establish a benchmark of challenging CRL problems.
Optimistic Meta-Gradients
Jan 09, 2023



We study the connection between gradient-based meta-learning and convex op-timisation. We observe that gradient descent with momentum is a special case of meta-gradients, and building on recent results in optimisation, we prove convergence rates for meta-learning in the single task setting. While a meta-learned update rule can yield faster convergence up to constant factor, it is not sufficient for acceleration. Instead, some form of optimism is required. We show that optimism in meta-learning can be captured through Bootstrapped Meta-Gradients (Flennerhag et al., 2022), providing deeper insight into its underlying mechanics.
Discovering Evolution Strategies via Meta-Black-Box Optimization
Nov 25, 2022



Optimizing functions without access to gradients is the remit of black-box methods such as evolution strategies. While highly general, their learning dynamics are often times heuristic and inflexible - exactly the limitations that meta-learning can address. Hence, we propose to discover effective update rules for evolution strategies via meta-learning. Concretely, our approach employs a search strategy parametrized by a self-attention-based architecture, which guarantees the update rule is invariant to the ordering of the candidate solutions. We show that meta-evolving this system on a small set of representative low-dimensional analytic optimization problems is sufficient to discover new evolution strategies capable of generalizing to unseen optimization problems, population sizes and optimization horizons. Furthermore, the same learned evolution strategy can outperform established neuroevolution baselines on supervised and continuous control tasks. As additional contributions, we ablate the individual neural network components of our method; reverse engineer the learned strategy into an explicit heuristic form, which remains highly competitive; and show that it is possible to self-referentially train an evolution strategy from scratch, with the learned update rule used to drive the outer meta-learning loop.
Meta-Gradients in Non-Stationary Environments
Sep 13, 2022
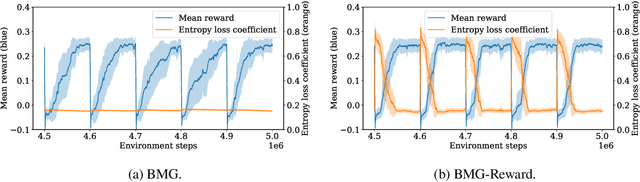
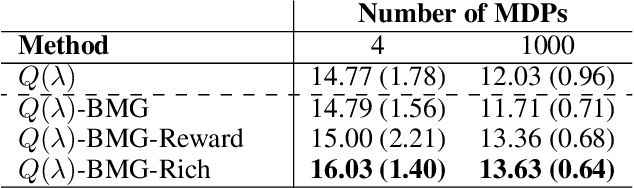
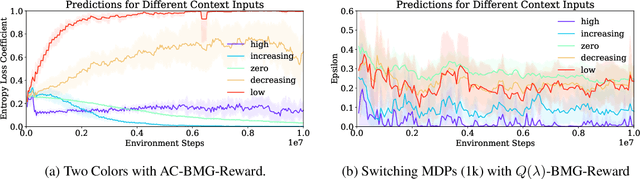
Meta-gradient methods (Xu et al., 2018; Zahavy et al., 2020) offer a promising solution to the problem of hyperparameter selection and adaptation in non-stationary reinforcement learning problems. However, the properties of meta-gradients in such environments have not been systematically studied. In this work, we bring new clarity to meta-gradients in non-stationary environments. Concretely, we ask: (i) how much information should be given to the learned optimizers, so as to enable faster adaptation and generalization over a lifetime, (ii) what meta-optimizer functions are learned in this process, and (iii) whether meta-gradient methods provide a bigger advantage in highly non-stationary environments. To study the effect of information provided to the meta-optimizer, as in recent works (Flennerhag et al., 2021; Almeida et al., 2021), we replace the tuned meta-parameters of fixed update rules with learned meta-parameter functions of selected context features. The context features carry information about agent performance and changes in the environment and hence can inform learned meta-parameter schedules. We find that adding more contextual information is generally beneficial, leading to faster adaptation of meta-parameter values and increased performance over a lifetime. We support these results with a qualitative analysis of resulting meta-parameter schedules and learned functions of context features. Lastly, we find that without context, meta-gradients do not provide a consistent advantage over the baseline in highly non-stationary environments. Our findings suggest that contextualizing meta-gradients can play a pivotal role in extracting high performance from meta-gradients in non-stationary settings.
Discovering Policies with DOMiNO: Diversity Optimization Maintaining Near Optimality
May 26, 2022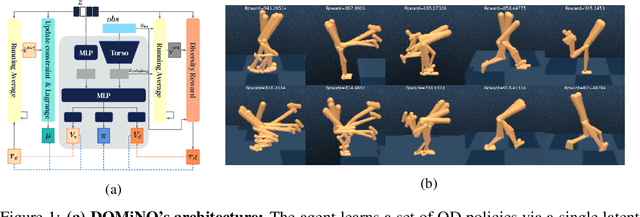
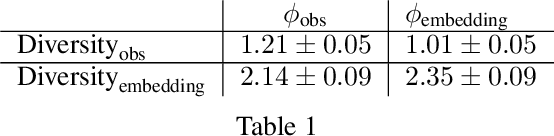
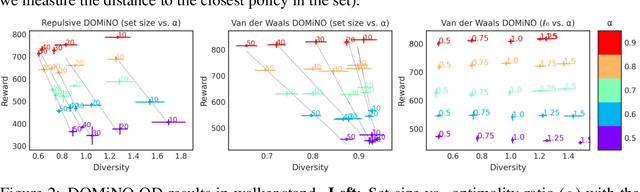
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose DOMiNO, a method for Diversity Optimization Maintaining Near Optimality. We formalize the problem as a Constrained Markov Decision Process where the objective is to find diverse policies, measured by the distance between the state occupancies of the policies in the set, while remaining near-optimal with respect to the extrinsic reward. We demonstrate that the method can discover diverse and meaningful behaviors in various domains, such as different locomotion patterns in the DeepMind Control Suite. We perform extensive analysis of our approach, compare it with other multi-objective baselines, demonstrate that we can control both the quality and the diversity of the set via interpretable hyperparameters, and show that the discovered set is robust to perturbations.
Introducing Symmetries to Black Box Meta Reinforcement Learning
Sep 22, 2021



Meta reinforcement learning (RL) attempts to discover new RL algorithms automatically from environment interaction. In so-called black-box approaches, the policy and the learning algorithm are jointly represented by a single neural network. These methods are very flexible, but they tend to underperform in terms of generalisation to new, unseen environments. In this paper, we explore the role of symmetries in meta-generalisation. We show that a recent successful meta RL approach that meta-learns an objective for backpropagation-based learning exhibits certain symmetries (specifically the reuse of the learning rule, and invariance to input and output permutations) that are not present in typical black-box meta RL systems. We hypothesise that these symmetries can play an important role in meta-generalisation. Building off recent work in black-box supervised meta learning, we develop a black-box meta RL system that exhibits these same symmetries. We show through careful experimentation that incorporating these symmetries can lead to algorithms with a greater ability to generalise to unseen action & observation spaces, tasks, and environments.
Bootstrapped Meta-Learning
Sep 09, 2021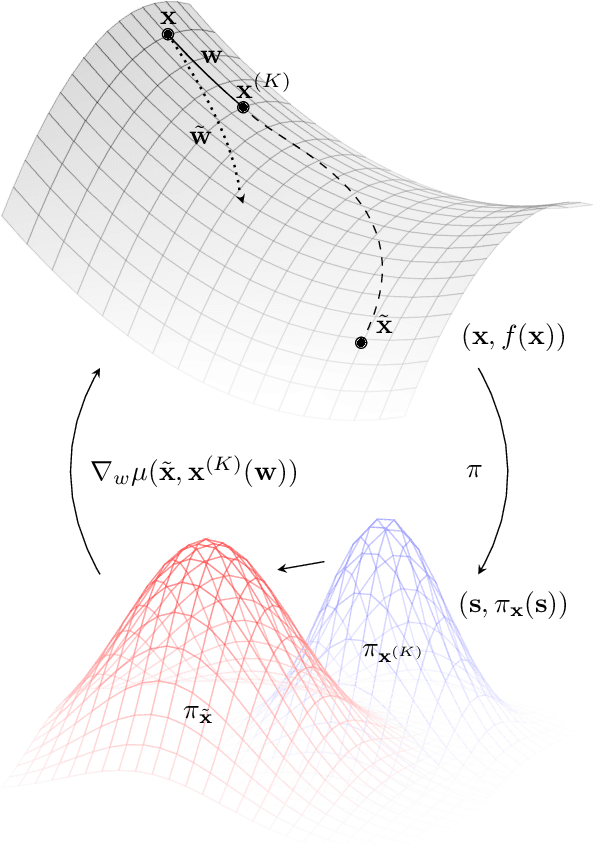

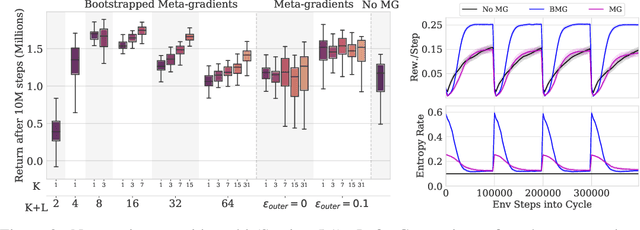
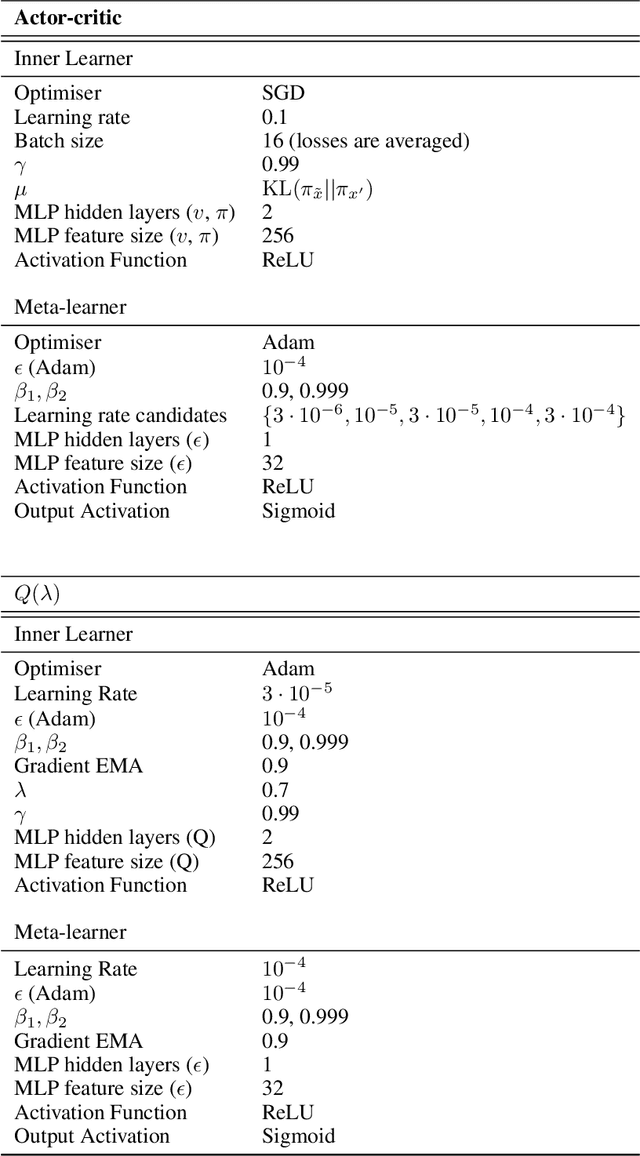
Meta-learning empowers artificial intelligence to increase its efficiency by learning how to learn. Unlocking this potential involves overcoming a challenging meta-optimisation problem that often exhibits ill-conditioning, and myopic meta-objectives. We propose an algorithm that tackles these issues by letting the meta-learner teach itself. The algorithm first bootstraps a target from the meta-learner, then optimises the meta-learner by minimising the distance to that target under a chosen (pseudo-)metric. Focusing on meta-learning with gradients, we establish conditions that guarantee performance improvements and show that the improvement is related to the target distance. Thus, by controlling curvature, the distance measure can be used to ease meta-optimization, for instance by reducing ill-conditioning. Further, the bootstrapping mechanism can extend the effective meta-learning horizon without requiring backpropagation through all updates. The algorithm is versatile and easy to implement. We achieve a new state-of-the art for model-free agents on the Atari ALE benchmark, improve upon MAML in few-shot learning, and demonstrate how our approach opens up new possibilities by meta-learning efficient exploration in a Q-learning agent.