 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeroto 2.0: The Robot Tactile Olympiad
May 20, 2026Tactile-based reinforcement learning (RL) is currently hindered by fragmented research and a focus on over-saturated orientation tasks. We introduce v2 of the Robot Tactile Olympiad (\texttt{roto 2.0}), a GPU-parallelised benchmark designed to standardise tactile-based RL across four distinct robotic morphologies (16-DOF to 24-DOF). Unlike prior benchmarks, roto focuses on end-to-end "blind" manipulation, utilising only proprioception and tactile sensing without state information or distillation. We demonstrate a significant performance leap, with our blind agents achieving 13 Baoding ball rotations in 10 seconds, an order of magnitude faster than current state-of-the-art speeds. By open-sourcing our environments and robustly tuned baselines, we reduce the barrier to entry and enable researchers to prioritise fundamental algorithmic challenges over tedious RL tuning. Website: https://elle-miller.github.io/roto/
Probing Dec-POMDP Reasoning in Cooperative MARL
Feb 24, 2026Cooperative multi-agent reinforcement learning (MARL) is typically framed as a decentralised partially observable Markov decision process (Dec-POMDP), a setting whose hardness stems from two key challenges: partial observability and decentralised coordination. Genuinely solving such tasks requires Dec-POMDP reasoning, where agents use history to infer hidden states and coordinate based on local information. Yet it remains unclear whether popular benchmarks actually demand this reasoning or permit success via simpler strategies. We introduce a diagnostic suite combining statistically grounded performance comparisons and information-theoretic probes to audit the behavioural complexity of baseline policies (IPPO and MAPPO) across 37 scenarios spanning MPE, SMAX, Overcooked, Hanabi, and MaBrax. Our diagnostics reveal that success on these benchmarks rarely requires genuine Dec-POMDP reasoning. Reactive policies match the performance of memory-based agents in over half the scenarios, and emergent coordination frequently relies on brittle, synchronous action coupling rather than robust temporal influence. These findings suggest that some widely used benchmarks may not adequately test core Dec-POMDP assumptions under current training paradigms, potentially leading to over-optimistic assessments of progress. We release our diagnostic tooling to support more rigorous environment design and evaluation in cooperative MARL.
* To appear at the 25th International Conference on Autonomous Agents and Multi-Agent Systems (AAMAS 2026)
Fairness over Equality: Correcting Social Incentives in Asymmetric Sequential Social Dilemmas
Feb 17, 2026Sequential Social Dilemmas (SSDs) provide a key framework for studying how cooperation emerges when individual incentives conflict with collective welfare. In Multi-Agent Reinforcement Learning, these problems are often addressed by incorporating intrinsic drives that encourage prosocial or fair behavior. However, most existing methods assume that agents face identical incentives in the dilemma and require continuous access to global information about other agents to assess fairness. In this work, we introduce asymmetric variants of well-known SSD environments and examine how natural differences between agents influence cooperation dynamics. Our findings reveal that existing fairness-based methods struggle to adapt under asymmetric conditions by enforcing raw equality that wrongfully incentivize defection. To address this, we propose three modifications: (i) redefining fairness by accounting for agents' reward ranges, (ii) introducing an agent-based weighting mechanism to better handle inherent asymmetries, and (iii) localizing social feedback to make the methods effective under partial observability without requiring global information sharing. Experimental results show that in asymmetric scenarios, our method fosters faster emergence of cooperative policies compared to existing approaches, without sacrificing scalability or practicality.
Discovering Coordinated Joint Options via Inter-Agent Relative Dynamics
Dec 31, 2025Temporally extended actions improve the ability to explore and plan in single-agent settings. In multi-agent settings, the exponential growth of the joint state space with the number of agents makes coordinated behaviours even more valuable. Yet, this same exponential growth renders the design of multi-agent options particularly challenging. Existing multi-agent option discovery methods often sacrifice coordination by producing loosely coupled or fully independent behaviours. Toward addressing these limitations, we describe a novel approach for multi-agent option discovery. Specifically, we propose a joint-state abstraction that compresses the state space while preserving the information necessary to discover strongly coordinated behaviours. Our approach builds on the inductive bias that synchronisation over agent states provides a natural foundation for coordination in the absence of explicit objectives. We first approximate a fictitious state of maximal alignment with the team, the \textit{Fermat} state, and use it to define a measure of \textit{spreadness}, capturing team-level misalignment on each individual state dimension. Building on this representation, we then employ a neural graph Laplacian estimator to derive options that capture state synchronisation patterns between agents. We evaluate the resulting options across multiple scenarios in two multi-agent domains, showing that they yield stronger downstream coordination capabilities compared to alternative option discovery methods.
Forgetting is Everywhere
Nov 06, 2025A fundamental challenge in developing general learning algorithms is their tendency to forget past knowledge when adapting to new data. Addressing this problem requires a principled understanding of forgetting; yet, despite decades of study, no unified definition has emerged that provides insights into the underlying dynamics of learning. We propose an algorithm- and task-agnostic theory that characterises forgetting as a lack of self-consistency in a learner's predictive distribution over future experiences, manifesting as a loss of predictive information. Our theory naturally yields a general measure of an algorithm's propensity to forget. To validate the theory, we design a comprehensive set of experiments that span classification, regression, generative modelling, and reinforcement learning. We empirically demonstrate how forgetting is present across all learning settings and plays a significant role in determining learning efficiency. Together, these results establish a principled understanding of forgetting and lay the foundation for analysing and improving the information retention capabilities of general learning algorithms.
Enhancing Tactile-based Reinforcement Learning for Robotic Control
Oct 24, 2025Achieving safe, reliable real-world robotic manipulation requires agents to evolve beyond vision and incorporate tactile sensing to overcome sensory deficits and reliance on idealised state information. Despite its potential, the efficacy of tactile sensing in reinforcement learning (RL) remains inconsistent. We address this by developing self-supervised learning (SSL) methodologies to more effectively harness tactile observations, focusing on a scalable setup of proprioception and sparse binary contacts. We empirically demonstrate that sparse binary tactile signals are critical for dexterity, particularly for interactions that proprioceptive control errors do not register, such as decoupled robot-object motions. Our agents achieve superhuman dexterity in complex contact tasks (ball bouncing and Baoding ball rotation). Furthermore, we find that decoupling the SSL memory from the on-policy memory can improve performance. We release the Robot Tactile Olympiad (RoTO) benchmark to standardise and promote future research in tactile-based manipulation. Project page: https://elle-miller.github.io/tactile_rl
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning
Mar 08, 2025

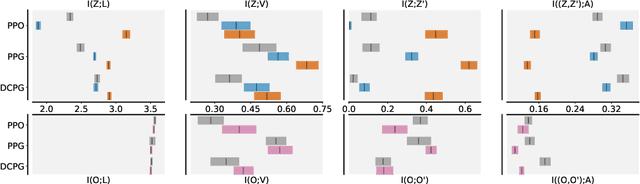
Extracting relevant information from a stream of high-dimensional observations is a central challenge for deep reinforcement learning agents. Actor-critic algorithms add further complexity to this challenge, as it is often unclear whether the same information will be relevant to both the actor and the critic. To this end, we here explore the principles that underlie effective representations for the actor and for the critic in on-policy algorithms. We focus our study on understanding whether the actor and critic will benefit from separate, rather than shared, representations. Our primary finding is that when separated, the representations for the actor and critic systematically specialise in extracting different types of information from the environment -- the actor's representation tends to focus on action-relevant information, while the critic's representation specialises in encoding value and dynamics information. We conduct a rigourous empirical study to understand how different representation learning approaches affect the actor and critic's specialisations and their downstream performance, in terms of sample efficiency and generation capabilities. Finally, we discover that a separated critic plays an important role in exploration and data collection during training. Our code, trained models and data are accessible at https://github.com/francelico/deac-rep.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
A Black Swan Hypothesis in Markov Decision Process via Irrationality
Jul 25, 2024
Black swan events are statistically rare occurrences that carry extremely high risks. A typical view of defining black swan events is heavily assumed to originate from an unpredictable time-varying environments; however, the community lacks a comprehensive definition of black swan events. To this end, this paper challenges that the standard view is incomplete and claims that high-risk, statistically rare events can also occur in unchanging environments due to human misperception of their value and likelihood, which we call as spatial black swan event. We first carefully categorize black swan events, focusing on spatial black swan events, and mathematically formalize the definition of black swan events. We hope these definitions can pave the way for the development of algorithms to prevent such events by rationally correcting human perception