 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout Cards: A Reproducibility Standard for Agent Research
May 12, 2026Reproducibility problems that have long affected machine learning and reinforcement learning are now surfacing in agent research: papers compare systems by reported scores while leaving the rollout records behind those scores difficult to inspect. For agentic tasks, this matters because the same behaviour can receive different reported scores when evaluations select different parts of a rollout or apply different reporting rules. In a structured audit of 50 popular training and evaluation repositories, we find that none report how many runs failed, errored, or were skipped alongside headline scores. We also document 37 cases where reporting rules can change task-success rates, cost/token accounting, or timing measurements for fixed evidence, sometimes dramatically. We treat rollout records, not reported scores, as the unit of reproducibility for agent research. We introduce rollout cards: publication bundles that preserve the rollout record and declare the views, reporting rules, and drops manifests behind reported scores. We validate rollout cards in two settings. First, four partial public releases in tool safety, multi-agent systems, theorem proving, and search let us compute analyses their original reports did not include. Second, re-grading preserved benchmark outputs across short-answer, code-generation, and tool-use tasks shows that changing only the reporting rule can change reported scores by 20.9 absolute percentage points and, in some cases, invert rankings of frontier models. We release a reference implementation integrated into Ergon, an open-source reinforcement learning gym, and publicly publish Ergon-produced rollout-card exports for benchmarks spanning tool use, software engineering, web interaction, multi-agent coordination, safety, and search to support future research.
Fairness over Equality: Correcting Social Incentives in Asymmetric Sequential Social Dilemmas
Feb 17, 2026Sequential Social Dilemmas (SSDs) provide a key framework for studying how cooperation emerges when individual incentives conflict with collective welfare. In Multi-Agent Reinforcement Learning, these problems are often addressed by incorporating intrinsic drives that encourage prosocial or fair behavior. However, most existing methods assume that agents face identical incentives in the dilemma and require continuous access to global information about other agents to assess fairness. In this work, we introduce asymmetric variants of well-known SSD environments and examine how natural differences between agents influence cooperation dynamics. Our findings reveal that existing fairness-based methods struggle to adapt under asymmetric conditions by enforcing raw equality that wrongfully incentivize defection. To address this, we propose three modifications: (i) redefining fairness by accounting for agents' reward ranges, (ii) introducing an agent-based weighting mechanism to better handle inherent asymmetries, and (iii) localizing social feedback to make the methods effective under partial observability without requiring global information sharing. Experimental results show that in asymmetric scenarios, our method fosters faster emergence of cooperative policies compared to existing approaches, without sacrificing scalability or practicality.
Integrating Counterfactual Simulations with Language Models for Explaining Multi-Agent Behaviour
May 23, 2025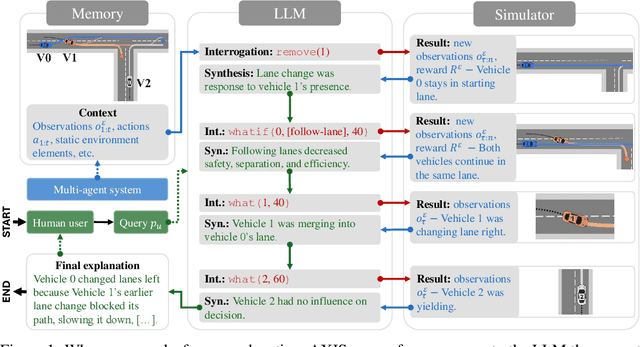

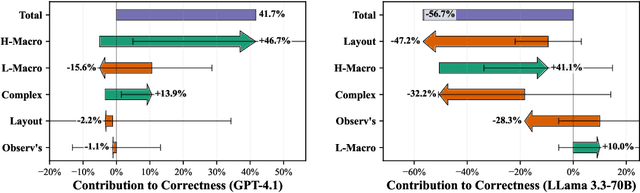
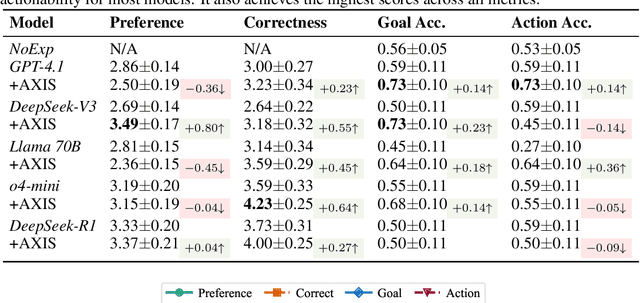
Autonomous multi-agent systems (MAS) are useful for automating complex tasks but raise trust concerns due to risks like miscoordination and goal misalignment. Explainability is vital for trust calibration, but explainable reinforcement learning for MAS faces challenges in state/action space complexity, stakeholder needs, and evaluation. Using the counterfactual theory of causation and LLMs' summarisation capabilities, we propose Agentic eXplanations via Interrogative Simulation (AXIS). AXIS generates intelligible causal explanations for pre-trained multi-agent policies by having an LLM interrogate an environment simulator using queries like 'whatif' and 'remove' to observe and synthesise counterfactual information over multiple rounds. We evaluate AXIS on autonomous driving across 10 scenarios for 5 LLMs with a novel evaluation methodology combining subjective preference, correctness, and goal/action prediction metrics, and an external LLM as evaluator. Compared to baselines, AXIS improves perceived explanation correctness by at least 7.7% across all models and goal prediction accuracy by 23% for 4 models, with improved or comparable action prediction accuracy, achieving the highest scores overall.
HAD-Gen: Human-like and Diverse Driving Behavior Modeling for Controllable Scenario Generation
Mar 19, 2025
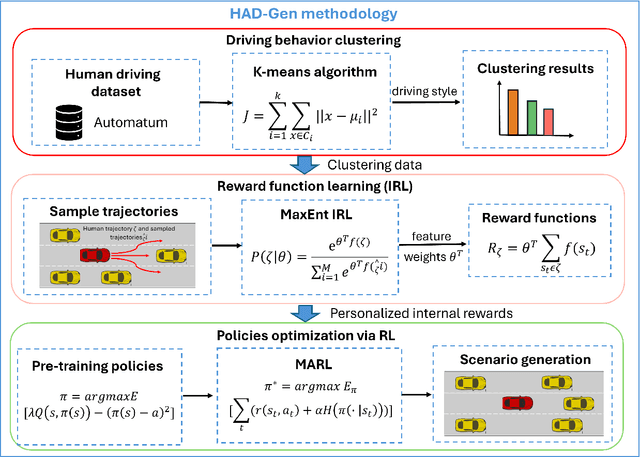


Simulation-based testing has emerged as an essential tool for verifying and validating autonomous vehicles (AVs). However, contemporary methodologies, such as deterministic and imitation learning-based driver models, struggle to capture the variability of human-like driving behavior. Given these challenges, we propose HAD-Gen, a general framework for realistic traffic scenario generation that simulates diverse human-like driving behaviors. The framework first clusters the vehicle trajectory data into different driving styles according to safety features. It then employs maximum entropy inverse reinforcement learning on each of the clusters to learn the reward function corresponding to each driving style. Using these reward functions, the method integrates offline reinforcement learning pre-training and multi-agent reinforcement learning algorithms to obtain general and robust driving policies. Multi-perspective simulation results show that our proposed scenario generation framework can simulate diverse, human-like driving behaviors with strong generalization capability. The proposed framework achieves a 90.96% goal-reaching rate, an off-road rate of 2.08%, and a collision rate of 6.91% in the generalization test, outperforming prior approaches by over 20% in goal-reaching performance. The source code is released at https://github.com/RoboSafe-Lab/Sim4AD.
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning
Mar 08, 2025

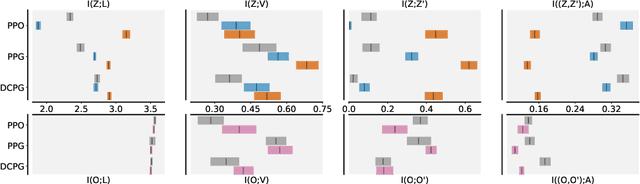
Extracting relevant information from a stream of high-dimensional observations is a central challenge for deep reinforcement learning agents. Actor-critic algorithms add further complexity to this challenge, as it is often unclear whether the same information will be relevant to both the actor and the critic. To this end, we here explore the principles that underlie effective representations for the actor and for the critic in on-policy algorithms. We focus our study on understanding whether the actor and critic will benefit from separate, rather than shared, representations. Our primary finding is that when separated, the representations for the actor and critic systematically specialise in extracting different types of information from the environment -- the actor's representation tends to focus on action-relevant information, while the critic's representation specialises in encoding value and dynamics information. We conduct a rigourous empirical study to understand how different representation learning approaches affect the actor and critic's specialisations and their downstream performance, in terms of sample efficiency and generation capabilities. Finally, we discover that a separated critic plays an important role in exploration and data collection during training. Our code, trained models and data are accessible at https://github.com/francelico/deac-rep.
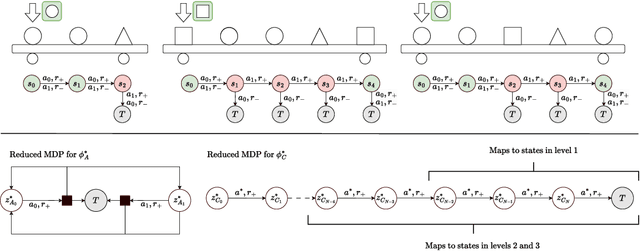
Agent-Temporal Credit Assignment for Optimal Policy Preservation in Sparse Multi-Agent Reinforcement Learning
Dec 19, 2024
In multi-agent environments, agents often struggle to learn optimal policies due to sparse or delayed global rewards, particularly in long-horizon tasks where it is challenging to evaluate actions at intermediate time steps. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), a novel approach designed to address the agent-temporal credit assignment problem by redistributing sparse rewards both temporally and across agents. TAR$^2$ decomposes sparse global rewards into time-step-specific rewards and calculates agent-specific contributions to these rewards. We theoretically prove that TAR$^2$ is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirical results demonstrate that TAR$^2$ stabilizes and accelerates the learning process. Additionally, we show that when TAR$^2$ is integrated with single-agent reinforcement learning algorithms, it performs as well as or better than traditional multi-agent reinforcement learning methods.
HyperMARL: Adaptive Hypernetworks for Multi-Agent RL
Dec 05, 2024



Balancing individual specialisation and shared behaviours is a critical challenge in multi-agent reinforcement learning (MARL). Existing methods typically focus on encouraging diversity or leveraging shared representations. Full parameter sharing (FuPS) improves sample efficiency but struggles to learn diverse behaviours when required, while no parameter sharing (NoPS) enables diversity but is computationally expensive and sample inefficient. To address these challenges, we introduce HyperMARL, a novel approach using hypernetworks to balance efficiency and specialisation. HyperMARL generates agent-specific actor and critic parameters, enabling agents to adaptively exhibit diverse or homogeneous behaviours as needed, without modifying the learning objective or requiring prior knowledge of the optimal diversity. Furthermore, HyperMARL decouples agent-specific and state-based gradients, which empirically correlates with reduced policy gradient variance, potentially offering insights into its ability to capture diverse behaviours. Across MARL benchmarks requiring homogeneous, heterogeneous, or mixed behaviours, HyperMARL consistently matches or outperforms FuPS, NoPS, and diversity-focused methods, achieving NoPS-level diversity with a shared architecture. These results highlight the potential of hypernetworks as a versatile approach to the trade-off between specialisation and shared behaviours in MARL.
Skill-aware Mutual Information Optimisation for Generalisation in Reinforcement Learning
Jun 07, 2024



Meta-Reinforcement Learning (Meta-RL) agents can struggle to operate across tasks with varying environmental features that require different optimal skills (i.e., different modes of behaviours). Using context encoders based on contrastive learning to enhance the generalisability of Meta-RL agents is now widely studied but faces challenges such as the requirement for a large sample size, also referred to as the $\log$-$K$ curse. To improve RL generalisation to different tasks, we first introduce Skill-aware Mutual Information (SaMI), an optimisation objective that aids in distinguishing context embeddings according to skills, thereby equipping RL agents with the ability to identify and execute different skills across tasks. We then propose Skill-aware Noise Contrastive Estimation (SaNCE), a $K$-sample estimator used to optimise the SaMI objective. We provide a framework for equipping an RL agent with SaNCE in practice and conduct experimental validation on modified MuJoCo and Panda-gym benchmarks. We empirically find that RL agents that learn by maximising SaMI achieve substantially improved zero-shot generalisation to unseen tasks. Additionally, the context encoder equipped with SaNCE demonstrates greater robustness to reductions in the number of available samples, thus possessing the potential to overcome the $\log$-$K$ curse.
Highway Graph to Accelerate Reinforcement Learning
May 20, 2024



Reinforcement Learning (RL) algorithms often suffer from low training efficiency. A strategy to mitigate this issue is to incorporate a model-based planning algorithm, such as Monte Carlo Tree Search (MCTS) or Value Iteration (VI), into the environmental model. The major limitation of VI is the need to iterate over a large tensor. These still lead to intensive computations. We focus on improving the training efficiency of RL algorithms by improving the efficiency of the value learning process. For the deterministic environments with discrete state and action spaces, a non-branching sequence of transitions moves the agent without deviating from intermediate states, which we call a highway. On such non-branching highways, the value-updating process can be merged as a one-step process instead of iterating the value step-by-step. Based on this observation, we propose a novel graph structure, named highway graph, to model the state transition. Our highway graph compresses the transition model into a concise graph, where edges can represent multiple state transitions to support value propagation across multiple time steps in each iteration. We thus can obtain a more efficient value learning approach by facilitating the VI algorithm on highway graphs. By integrating the highway graph into RL (as a model-based off-policy RL method), the RL training can be remarkably accelerated in the early stages (within 1 million frames). Comparison against various baselines on four categories of environments reveals that our method outperforms both representative and novel model-free and model-based RL algorithms, demonstrating 10 to more than 150 times more efficiency while maintaining an equal or superior expected return, as confirmed by carefully conducted analyses. Moreover, a deep neural network-based agent is trained using the highway graph, resulting in better generalization and lower storage costs.
LLM-Personalize: Aligning LLM Planners with Human Preferences via Reinforced Self-Training for Housekeeping Robots
Apr 22, 2024



Large language models (LLMs) have shown significant potential for robotics applications, particularly task planning, by harnessing their language comprehension and text generation capabilities. However, in applications such as household robotics, a critical gap remains in the personalization of these models to individual user preferences. We introduce LLM-Personalize, a novel framework with an optimization pipeline designed to personalize LLM planners for household robotics. Our LLM-Personalize framework features an LLM planner that performs iterative planning in multi-room, partially-observable household scenarios, making use of a scene graph constructed with local observations. The generated plan consists of a sequence of high-level actions which are subsequently executed by a controller. Central to our approach is the optimization pipeline, which combines imitation learning and iterative self-training to personalize the LLM planner. In particular, the imitation learning phase performs initial LLM alignment from demonstrations, and bootstraps the model to facilitate effective iterative self-training, which further explores and aligns the model to user preferences. We evaluate LLM-Personalize on Housekeep, a challenging simulated real-world 3D benchmark for household rearrangements, and show that LLM-Personalize achieves more than a 30 percent increase in success rate over existing LLM planners, showcasing significantly improved alignment with human preferences. Project page: https://donggehan.github.io/projectllmpersonalize/.