 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Agent-Specific Adaptation (LoRASA) for Multi-Agent Policy Learning
Feb 08, 2025Multi-agent reinforcement learning (MARL) often relies on \emph{parameter sharing (PS)} to scale efficiently. However, purely shared policies can stifle each agent's unique specialization, reducing overall performance in heterogeneous environments. We propose \textbf{Low-Rank Agent-Specific Adaptation (LoRASA)}, a novel approach that treats each agent's policy as a specialized ``task'' fine-tuned from a shared backbone. Drawing inspiration from parameter-efficient transfer methods, LoRASA appends small, low-rank adaptation matrices to each layer of the shared policy, naturally inducing \emph{parameter-space sparsity} that promotes both specialization and scalability. We evaluate LoRASA on challenging benchmarks including the StarCraft Multi-Agent Challenge (SMAC) and Multi-Agent MuJoCo (MAMuJoCo), implementing it atop widely used algorithms such as MAPPO and A2PO. Across diverse tasks, LoRASA matches or outperforms existing baselines \emph{while reducing memory and computational overhead}. Ablation studies on adapter rank, placement, and timing validate the method's flexibility and efficiency. Our results suggest LoRASA's potential to establish a new norm for MARL policy parameterization: combining a shared foundation for coordination with low-rank agent-specific refinements for individual specialization.
$TAR^2$: Temporal-Agent Reward Redistribution for Optimal Policy Preservation in Multi-Agent Reinforcement Learning
Feb 07, 2025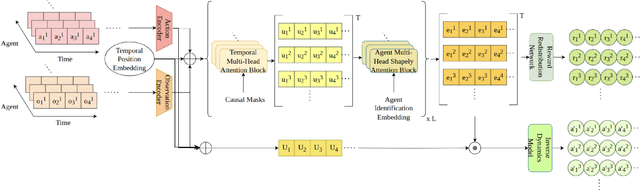

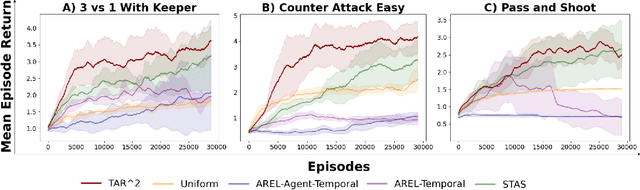

In cooperative multi-agent reinforcement learning (MARL), learning effective policies is challenging when global rewards are sparse and delayed. This difficulty arises from the need to assign credit across both agents and time steps, a problem that existing methods often fail to address in episodic, long-horizon tasks. We propose Temporal-Agent Reward Redistribution $TAR^2$, a novel approach that decomposes sparse global rewards into agent-specific, time-step-specific components, thereby providing more frequent and accurate feedback for policy learning. Theoretically, we show that $TAR^2$ (i) aligns with potential-based reward shaping, preserving the same optimal policies as the original environment, and (ii) maintains policy gradient update directions identical to those under the original sparse reward, ensuring unbiased credit signals. Empirical results on two challenging benchmarks, SMACLite and Google Research Football, demonstrate that $TAR^2$ significantly stabilizes and accelerates convergence, outperforming strong baselines like AREL and STAS in both learning speed and final performance. These findings establish $TAR^2$ as a principled and practical solution for agent-temporal credit assignment in sparse-reward multi-agent systems.
Agent-Temporal Credit Assignment for Optimal Policy Preservation in Sparse Multi-Agent Reinforcement Learning
Dec 19, 2024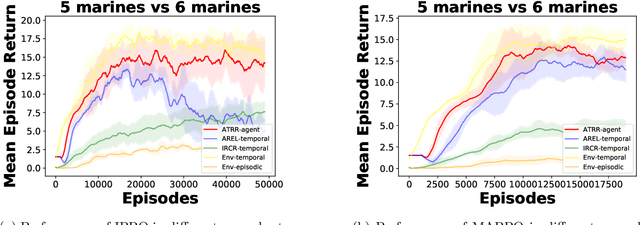
In multi-agent environments, agents often struggle to learn optimal policies due to sparse or delayed global rewards, particularly in long-horizon tasks where it is challenging to evaluate actions at intermediate time steps. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), a novel approach designed to address the agent-temporal credit assignment problem by redistributing sparse rewards both temporally and across agents. TAR$^2$ decomposes sparse global rewards into time-step-specific rewards and calculates agent-specific contributions to these rewards. We theoretically prove that TAR$^2$ is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirical results demonstrate that TAR$^2$ stabilizes and accelerates the learning process. Additionally, we show that when TAR$^2$ is integrated with single-agent reinforcement learning algorithms, it performs as well as or better than traditional multi-agent reinforcement learning methods.
Assigning Credit with Partial Reward Decoupling in Multi-Agent Proximal Policy Optimization
Aug 08, 2024Multi-agent proximal policy optimization (MAPPO) has recently demonstrated state-of-the-art performance on challenging multi-agent reinforcement learning tasks. However, MAPPO still struggles with the credit assignment problem, wherein the sheer difficulty in ascribing credit to individual agents' actions scales poorly with team size. In this paper, we propose a multi-agent reinforcement learning algorithm that adapts recent developments in credit assignment to improve upon MAPPO. Our approach leverages partial reward decoupling (PRD), which uses a learned attention mechanism to estimate which of a particular agent's teammates are relevant to its learning updates. We use this estimate to dynamically decompose large groups of agents into smaller, more manageable subgroups. We empirically demonstrate that our approach, PRD-MAPPO, decouples agents from teammates that do not influence their expected future reward, thereby streamlining credit assignment. We additionally show that PRD-MAPPO yields significantly higher data efficiency and asymptotic performance compared to both MAPPO and other state-of-the-art methods across several multi-agent tasks, including StarCraft II. Finally, we propose a version of PRD-MAPPO that is applicable to \textit{shared} reward settings, where PRD was previously not applicable, and empirically show that this also leads to performance improvements over MAPPO.
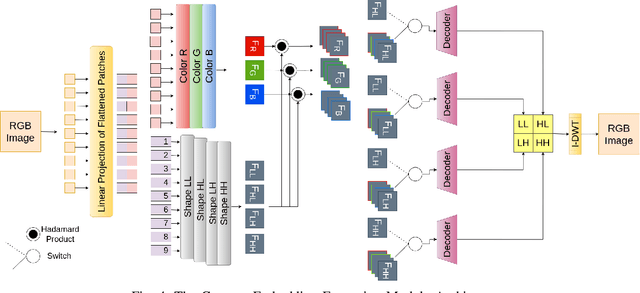
DeepClean: Integrated Distortion Identification and Algorithm Selection for Rectifying Image Corruptions
Jul 23, 2024Distortion identification and rectification in images and videos is vital for achieving good performance in downstream vision applications. Instead of relying on fixed trial-and-error based image processing pipelines, we propose a two-level sequential planning approach for automated image distortion classification and rectification. At the higher level it detects the class of corruptions present in the input image, if any. The lower level selects a specific algorithm to be applied, from a set of externally provided candidate algorithms. The entire two-level setup runs in the form of a single forward pass during inference and it is to be queried iteratively until the retrieval of the original image. We demonstrate improvements compared to three baselines on the object detection task on COCO image dataset with rich set of distortions. The advantage of our approach is its dynamic reconfiguration, conditioned on the input image and generalisability to unseen candidate algorithms at inference time, since it relies only on the comparison of their output of the image embeddings.
Long-Horizon Planning for Multi-Agent Robots in Partially Observable Environments
Jul 14, 2024



The ability of Language Models (LMs) to understand natural language makes them a powerful tool for parsing human instructions into task plans for autonomous robots. Unlike traditional planning methods that rely on domain-specific knowledge and handcrafted rules, LMs generalize from diverse data and adapt to various tasks with minimal tuning, acting as a compressed knowledge base. However, LMs in their standard form face challenges with long-horizon tasks, particularly in partially observable multi-agent settings. We propose an LM-based Long-Horizon Planner for Multi-Agent Robotics (LLaMAR), a cognitive architecture for planning that achieves state-of-the-art results in long-horizon tasks within partially observable environments. LLaMAR employs a plan-act-correct-verify framework, allowing self-correction from action execution feedback without relying on oracles or simulators. Additionally, we present MAP-THOR, a comprehensive test suite encompassing household tasks of varying complexity within the AI2-THOR environment. Experiments show that LLaMAR achieves a 30% higher success rate compared to other state-of-the-art LM-based multi-agent planners.
Concept-based Anomaly Detection in Retail Stores for Automatic Correction using Mobile Robots
Oct 21, 2023
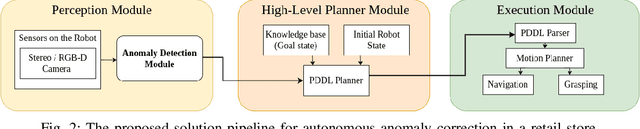

Tracking of inventory and rearrangement of misplaced items are some of the most labor-intensive tasks in a retail environment. While there have been attempts at using vision-based techniques for these tasks, they mostly use planogram compliance for detection of any anomalies, a technique that has been found lacking in robustness and scalability. Moreover, existing systems rely on human intervention to perform corrective actions after detection. In this paper, we present Co-AD, a Concept-based Anomaly Detection approach using a Vision Transformer (ViT) that is able to flag misplaced objects without using a prior knowledge base such as a planogram. It uses an auto-encoder architecture followed by outlier detection in the latent space. Co-AD has a peak success rate of 89.90% on anomaly detection image sets of retail objects drawn from the RP2K dataset, compared to 80.81% on the best-performing baseline of a standard ViT auto-encoder. To demonstrate its utility, we describe a robotic mobile manipulation pipeline to autonomously correct the anomalies flagged by Co-AD. This work is ultimately aimed towards developing autonomous mobile robot solutions that reduce the need for human intervention in retail store management.
SocNavGym: A Reinforcement Learning Gym for Social Navigation
Apr 27, 2023



It is essential for autonomous robots to be socially compliant while navigating in human-populated environments. Machine Learning and, especially, Deep Reinforcement Learning have recently gained considerable traction in the field of Social Navigation. This can be partially attributed to the resulting policies not being bound by human limitations in terms of code complexity or the number of variables that are handled. Unfortunately, the lack of safety guarantees and the large data requirements by DRL algorithms make learning in the real world unfeasible. To bridge this gap, simulation environments are frequently used. We propose SocNavGym, an advanced simulation environment for social navigation that can generate a wide variety of social navigation scenarios and facilitates the development of intelligent social agents. SocNavGym is light-weight, fast, easy-to-use, and can be effortlessly configured to generate different types of social navigation scenarios. It can also be configured to work with different hand-crafted and data-driven social reward signals and to yield a variety of evaluation metrics to benchmark agents' performance. Further, we also provide a case study where a Dueling-DQN agent is trained to learn social-navigation policies using SocNavGym. The results provides evidence that SocNavGym can be used to train an agent from scratch to navigate in simple as well as complex social scenarios. Our experiments also show that the agents trained using the data-driven reward function displays more advanced social compliance in comparison to the heuristic-based reward function.
Auto-TransRL: Autonomous Composition of Vision Pipelines for Robotic Perception
Sep 07, 2022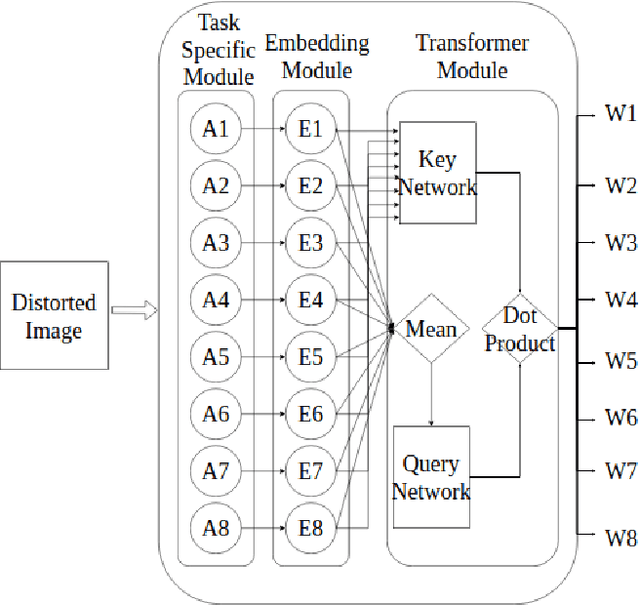
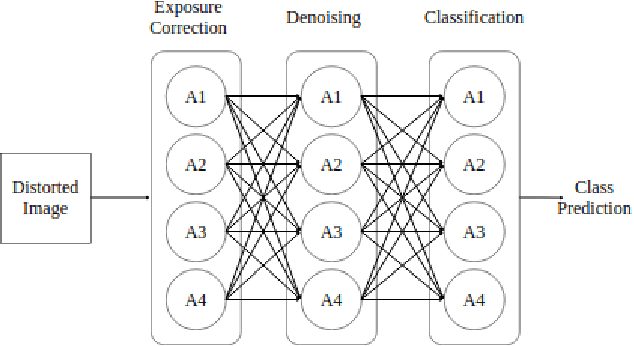
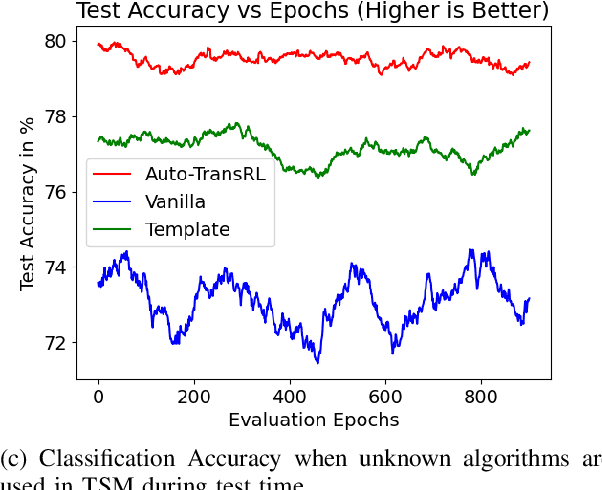
Creating a vision pipeline for different datasets to solve a computer vision task is a complex and time consuming process. Currently, these pipelines are developed with the help of domain experts. Moreover, there is no systematic structure to construct a vision pipeline apart from relying on experience, trial and error or using template-based approaches. As the search space for choosing suitable algorithms for achieving a particular vision task is large, human exploration for finding a good solution requires time and effort. To address the following issues, we propose a dynamic and data-driven way to identify an appropriate set of algorithms that would be fit for building the vision pipeline in order to achieve the goal task. We introduce a Transformer Architecture complemented with Deep Reinforcement Learning to recommend algorithms that can be incorporated at different stages of the vision workflow. This system is both robust and adaptive to dynamic changes in the environment. Experimental results further show that our method also generalizes well to recommend algorithms that have not been used while training and hence alleviates the need of retraining the system on a new set of algorithms introduced during test time.
Challenges in Applying Robotics to Retail Store Management
Aug 18, 2022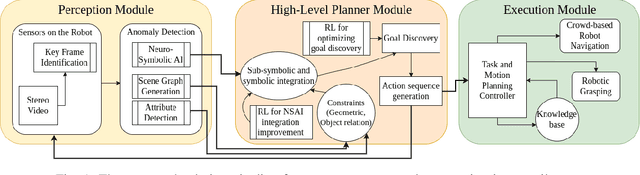
An autonomous retail store management system entails inventory tracking, store monitoring, and anomaly correction. Recent attempts at autonomous retail store management have faced challenges primarily in perception for anomaly detection, as well as new challenges arising in mobile manipulation for executing anomaly correction. Advances in each of these areas along with system integration are necessary for a scalable solution in this domain.