 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency Boost in Decentralized Optimization: Reimagining Neighborhood Aggregation with Minimal Overhead
Sep 26, 2025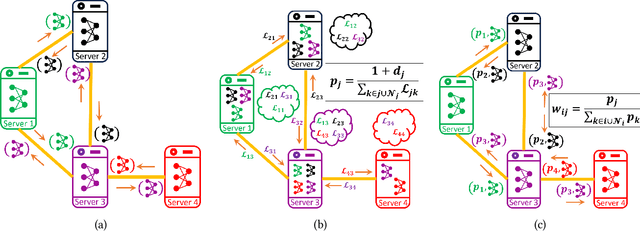
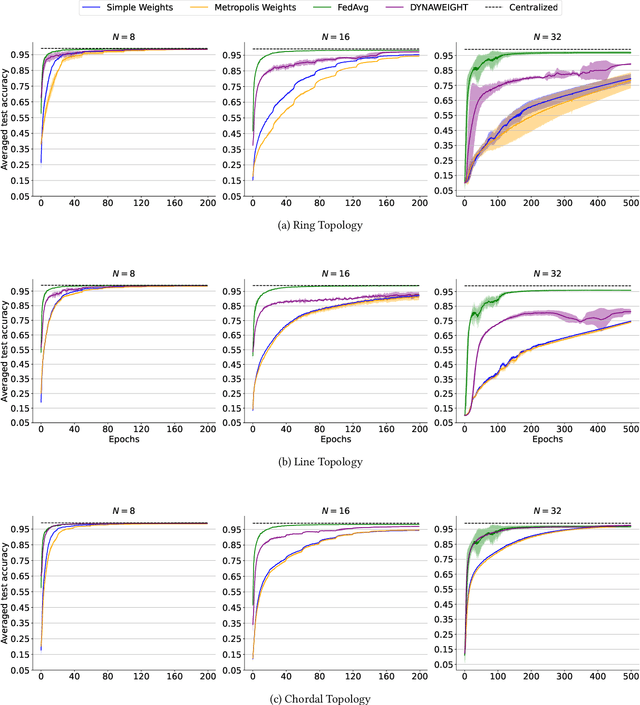
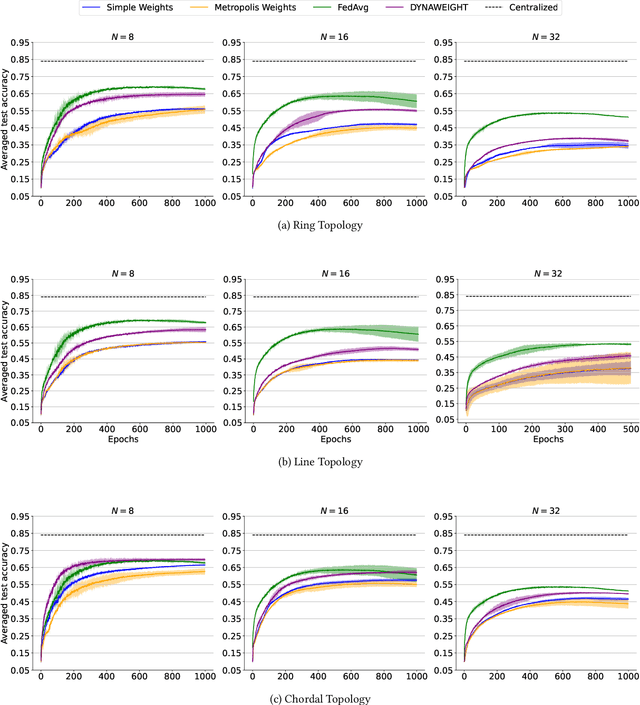
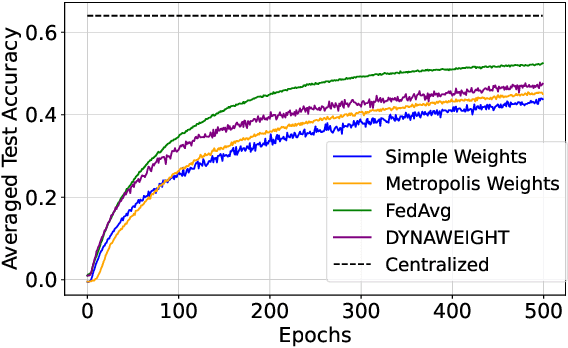
In today's data-sensitive landscape, distributed learning emerges as a vital tool, not only fortifying privacy measures but also streamlining computational operations. This becomes especially crucial within fully decentralized infrastructures where local processing is imperative due to the absence of centralized aggregation. Here, we introduce DYNAWEIGHT, a novel framework to information aggregation in multi-agent networks. DYNAWEIGHT offers substantial acceleration in decentralized learning with minimal additional communication and memory overhead. Unlike traditional static weight assignments, such as Metropolis weights, DYNAWEIGHT dynamically allocates weights to neighboring servers based on their relative losses on local datasets. Consequently, it favors servers possessing diverse information, particularly in scenarios of substantial data heterogeneity. Our experiments on various datasets MNIST, CIFAR10, and CIFAR100 incorporating various server counts and graph topologies, demonstrate notable enhancements in training speeds. Notably, DYNAWEIGHT functions as an aggregation scheme compatible with any underlying server-level optimization algorithm, underscoring its versatility and potential for widespread integration.
Causal-Counterfactual RAG: The Integration of Causal-Counterfactual Reasoning into RAG
Sep 17, 2025


Large language models (LLMs) have transformed natural language processing (NLP), enabling diverse applications by integrating large-scale pre-trained knowledge. However, their static knowledge limits dynamic reasoning over external information, especially in knowledge-intensive domains. Retrieval-Augmented Generation (RAG) addresses this challenge by combining retrieval mechanisms with generative modeling to improve contextual understanding. Traditional RAG systems suffer from disrupted contextual integrity due to text chunking and over-reliance on semantic similarity for retrieval, often resulting in shallow and less accurate responses. We propose Causal-Counterfactual RAG, a novel framework that integrates explicit causal graphs representing cause-effect relationships into the retrieval process and incorporates counterfactual reasoning grounded on the causal structure. Unlike conventional methods, our framework evaluates not only direct causal evidence but also the counterfactuality of associated causes, combining results from both to generate more robust, accurate, and interpretable answers. By leveraging causal pathways and associated hypothetical scenarios, Causal-Counterfactual RAG preserves contextual coherence, reduces hallucination, and enhances reasoning fidelity.
AEGIS: An Agent for Extraction and Geographic Identification in Scholarly Proceedings
Sep 11, 2025Keeping pace with the rapid growth of academia literature presents a significant challenge for researchers, funding bodies, and academic societies. To address the time-consuming manual effort required for scholarly discovery, we present a novel, fully automated system that transitions from data discovery to direct action. Our pipeline demonstrates how a specialized AI agent, 'Agent-E', can be tasked with identifying papers from specific geographic regions within conference proceedings and then executing a Robotic Process Automation (RPA) to complete a predefined action, such as submitting a nomination form. We validated our system on 586 papers from five different conferences, where it successfully identified every target paper with a recall of 100% and a near perfect accuracy of 99.4%. This demonstration highlights the potential of task-oriented AI agents to not only filter information but also to actively participate in and accelerate the workflows of the academic community.
$TAR^2$: Temporal-Agent Reward Redistribution for Optimal Policy Preservation in Multi-Agent Reinforcement Learning
Feb 07, 2025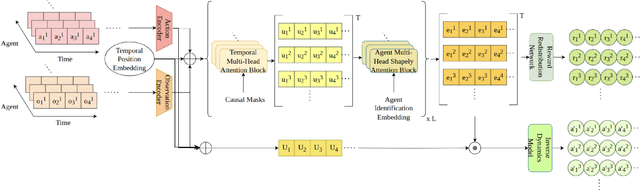

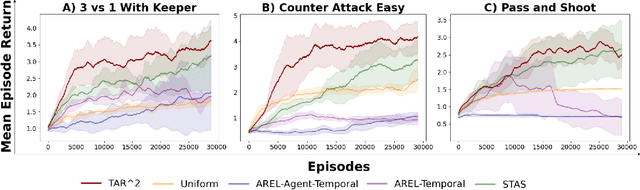

In cooperative multi-agent reinforcement learning (MARL), learning effective policies is challenging when global rewards are sparse and delayed. This difficulty arises from the need to assign credit across both agents and time steps, a problem that existing methods often fail to address in episodic, long-horizon tasks. We propose Temporal-Agent Reward Redistribution $TAR^2$, a novel approach that decomposes sparse global rewards into agent-specific, time-step-specific components, thereby providing more frequent and accurate feedback for policy learning. Theoretically, we show that $TAR^2$ (i) aligns with potential-based reward shaping, preserving the same optimal policies as the original environment, and (ii) maintains policy gradient update directions identical to those under the original sparse reward, ensuring unbiased credit signals. Empirical results on two challenging benchmarks, SMACLite and Google Research Football, demonstrate that $TAR^2$ significantly stabilizes and accelerates convergence, outperforming strong baselines like AREL and STAS in both learning speed and final performance. These findings establish $TAR^2$ as a principled and practical solution for agent-temporal credit assignment in sparse-reward multi-agent systems.
Agent-Temporal Credit Assignment for Optimal Policy Preservation in Sparse Multi-Agent Reinforcement Learning
Dec 19, 2024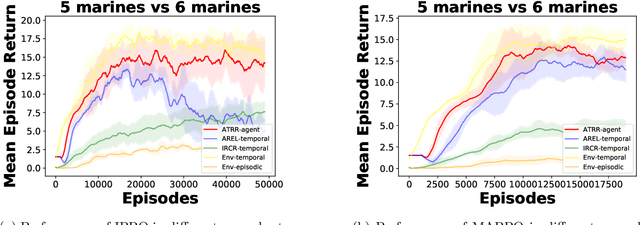
In multi-agent environments, agents often struggle to learn optimal policies due to sparse or delayed global rewards, particularly in long-horizon tasks where it is challenging to evaluate actions at intermediate time steps. We introduce Temporal-Agent Reward Redistribution (TAR$^2$), a novel approach designed to address the agent-temporal credit assignment problem by redistributing sparse rewards both temporally and across agents. TAR$^2$ decomposes sparse global rewards into time-step-specific rewards and calculates agent-specific contributions to these rewards. We theoretically prove that TAR$^2$ is equivalent to potential-based reward shaping, ensuring that the optimal policy remains unchanged. Empirical results demonstrate that TAR$^2$ stabilizes and accelerates the learning process. Additionally, we show that when TAR$^2$ is integrated with single-agent reinforcement learning algorithms, it performs as well as or better than traditional multi-agent reinforcement learning methods.
DeepClean: Integrated Distortion Identification and Algorithm Selection for Rectifying Image Corruptions
Jul 23, 2024Distortion identification and rectification in images and videos is vital for achieving good performance in downstream vision applications. Instead of relying on fixed trial-and-error based image processing pipelines, we propose a two-level sequential planning approach for automated image distortion classification and rectification. At the higher level it detects the class of corruptions present in the input image, if any. The lower level selects a specific algorithm to be applied, from a set of externally provided candidate algorithms. The entire two-level setup runs in the form of a single forward pass during inference and it is to be queried iteratively until the retrieval of the original image. We demonstrate improvements compared to three baselines on the object detection task on COCO image dataset with rich set of distortions. The advantage of our approach is its dynamic reconfiguration, conditioned on the input image and generalisability to unseen candidate algorithms at inference time, since it relies only on the comparison of their output of the image embeddings.
Transformers are Expressive, But Are They Expressive Enough for Regression?
Feb 23, 2024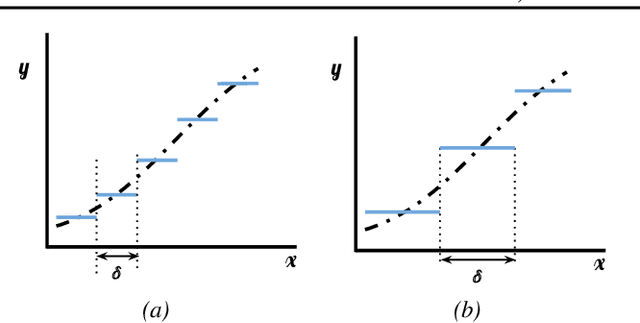


Transformers have become pivotal in Natural Language Processing, demonstrating remarkable success in applications like Machine Translation and Summarization. Given their widespread adoption, several works have attempted to analyze the expressivity of Transformers. Expressivity of a neural network is the class of functions it can approximate. A neural network is fully expressive if it can act as a universal function approximator. We attempt to analyze the same for Transformers. Contrary to existing claims, our findings reveal that Transformers struggle to reliably approximate continuous functions, relying on piecewise constant approximations with sizable intervals. The central question emerges as: "\textit{Are Transformers truly Universal Function Approximators}?" To address this, we conduct a thorough investigation, providing theoretical insights and supporting evidence through experiments. Our contributions include a theoretical analysis pinpointing the root of Transformers' limitation in function approximation and extensive experiments to verify the limitation. By shedding light on these challenges, we advocate a refined understanding of Transformers' capabilities.
Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF: A Case-Study in E-Commerce Opinion Summarization
Feb 23, 2024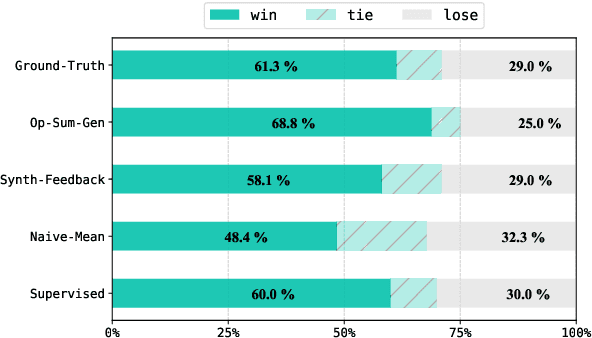



Reinforcement Learning from Human Feedback (RLHF) has become a dominating strategy in steering Language Models (LMs) towards human values/goals. The key to the strategy is employing a reward model ({$\varphi$}) which can reflect a latent reward model with humans. While this strategy has proven to be effective, the training methodology requires a lot of human preference annotation (usually of the order of tens of thousands) to train {$\varphi$}. Such large-scale preference annotations can be achievable if the reward model can be ubiquitously used. However, human values/goals are subjective and depend on the nature of the task. This poses a challenge in collecting diverse preferences for downstream applications. To address this, we propose a novel methodology to infuse domain knowledge into {$\varphi$}, which reduces the size of preference annotation required. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (just $940$ samples) while advancing the state-of-the-art. Our contributions include a novel Reward Modelling technique, a new dataset (PromptOpinSumm) for Opinion Summarization, and a human preference dataset (OpinPref). The proposed methodology opens avenues for efficient RLHF, making it more adaptable to diverse applications with varying human values. We release the artifacts for usage under MIT License.
Reinforcement Replaces Supervision: Query focused Summarization using Deep Reinforcement Learning
Nov 29, 2023Query-focused Summarization (QfS) deals with systems that generate summaries from document(s) based on a query. Motivated by the insight that Reinforcement Learning (RL) provides a generalization to Supervised Learning (SL) for Natural Language Generation, and thereby performs better (empirically) than SL, we use an RL-based approach for this task of QfS. Additionally, we also resolve the conflict of employing RL in Transformers with Teacher Forcing. We develop multiple Policy Gradient networks, trained on various reward signals: ROUGE, BLEU, and Semantic Similarity, which lead to a 10-point improvement over the State-of-the-Art approach on the ROUGE-L metric for a benchmark dataset (ELI5). We also show performance of our approach in zero-shot setting for another benchmark dataset (DebatePedia) -- our approach leads to results comparable to baselines, which were specifically trained on DebatePedia. To aid the RL training, we propose a better semantic similarity reward, enabled by a novel Passage Embedding scheme developed using Cluster Hypothesis. Lastly, we contribute a gold-standard test dataset to further research in QfS and Long-form Question Answering (LfQA).
Multi-Agent Learning of Efficient Fulfilment and Routing Strategies in E-Commerce
Nov 20, 2023This paper presents an integrated algorithmic framework for minimising product delivery costs in e-commerce (known as the cost-to-serve or C2S). One of the major challenges in e-commerce is the large volume of spatio-temporally diverse orders from multiple customers, each of which has to be fulfilled from one of several warehouses using a fleet of vehicles. This results in two levels of decision-making: (i) selection of a fulfillment node for each order (including the option of deferral to a future time), and then (ii) routing of vehicles (each of which can carry multiple orders originating from the same warehouse). We propose an approach that combines graph neural networks and reinforcement learning to train the node selection and vehicle routing agents. We include real-world constraints such as warehouse inventory capacity, vehicle characteristics such as travel times, service times, carrying capacity, and customer constraints including time windows for delivery. The complexity of this problem arises from the fact that outcomes (rewards) are driven both by the fulfillment node mapping as well as the routing algorithms, and are spatio-temporally distributed. Our experiments show that this algorithmic pipeline outperforms pure heuristic policies.