 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Learning of Efficient Fulfilment and Routing Strategies in E-Commerce
Nov 20, 2023This paper presents an integrated algorithmic framework for minimising product delivery costs in e-commerce (known as the cost-to-serve or C2S). One of the major challenges in e-commerce is the large volume of spatio-temporally diverse orders from multiple customers, each of which has to be fulfilled from one of several warehouses using a fleet of vehicles. This results in two levels of decision-making: (i) selection of a fulfillment node for each order (including the option of deferral to a future time), and then (ii) routing of vehicles (each of which can carry multiple orders originating from the same warehouse). We propose an approach that combines graph neural networks and reinforcement learning to train the node selection and vehicle routing agents. We include real-world constraints such as warehouse inventory capacity, vehicle characteristics such as travel times, service times, carrying capacity, and customer constraints including time windows for delivery. The complexity of this problem arises from the fact that outcomes (rewards) are driven both by the fulfillment node mapping as well as the routing algorithms, and are spatio-temporally distributed. Our experiments show that this algorithmic pipeline outperforms pure heuristic policies.
Using General Value Functions to Learn Domain-Backed Inventory Management Policies
Nov 03, 2023



We consider the inventory management problem, where the goal is to balance conflicting objectives such as availability and wastage of a large range of products in a store. We propose a reinforcement learning (RL) approach that utilises General Value Functions (GVFs) to derive domain-backed inventory replenishment policies. The inventory replenishment decisions are modelled as a sequential decision making problem, which is challenging due to uncertain demand and the existence of aggregate (cross-product) constraints. In existing literature, GVFs have primarily been used for auxiliary task learning. We use this capability to train GVFs on domain-critical characteristics such as prediction of stock-out probability and wastage quantity. Using this domain expertise for more effective exploration, we train an RL agent to compute the inventory replenishment quantities for a large range of products (up to 6000 in the reported experiments), which share aggregate constraints such as the total weight/volume per delivery. Additionally, we show that the GVF predictions can be used to provide additional domain-backed insights into the decisions proposed by the RL agent. Finally, since the environment dynamics are fully transferred, the trained GVFs can be used for faster adaptation to vastly different business objectives (for example, due to the start of a promotional period or due to deployment in a new customer environment).
Follow your Nose: Using General Value Functions for Directed Exploration in Reinforcement Learning
Mar 02, 2022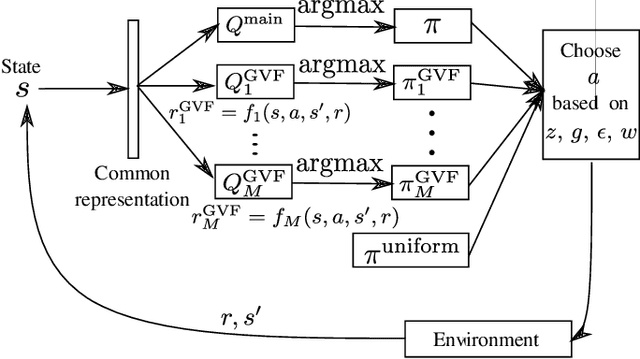
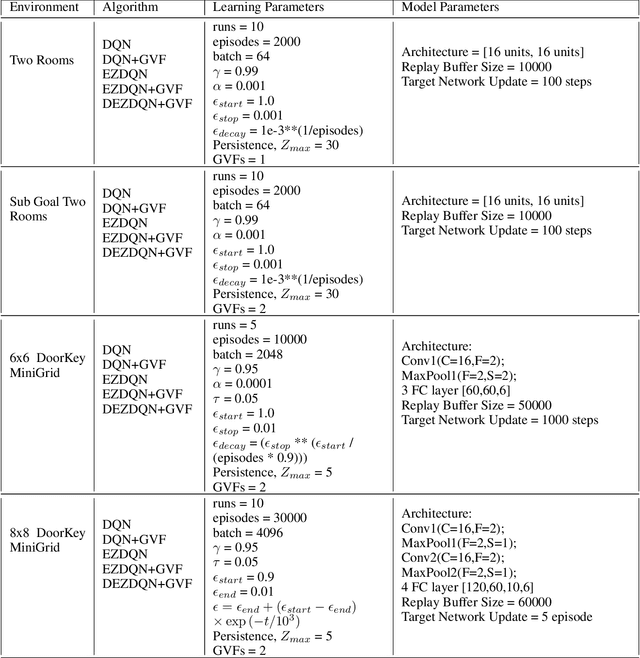
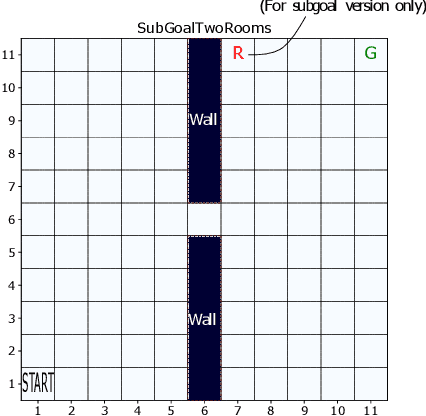
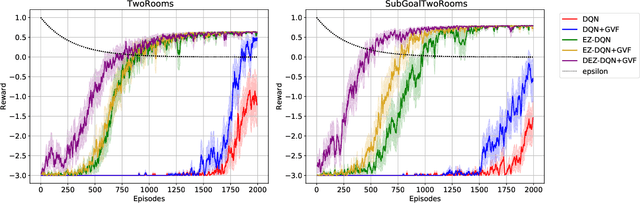
Exploration versus exploitation dilemma is a significant problem in reinforcement learning (RL), particularly in complex environments with large state space and sparse rewards. When optimizing for a particular goal, running simple smaller tasks can often be a good way to learn additional information about the environment. Exploration methods have been used to sample better trajectories from the environment for improved performance while auxiliary tasks have been incorporated generally where the reward is sparse. If there is little reward signal available, the agent requires clever exploration strategies to reach parts of the state space that contain relevant sub-goals. However, that exploration needs to be balanced with the need for exploiting the learned policy. This paper explores the idea of combining exploration with auxiliary task learning using General Value Functions (GVFs) and a directed exploration strategy. We provide a simple way to learn options (sequences of actions) instead of having to handcraft them, and demonstrate the performance advantage in three navigation tasks.
School of hard knocks: Curriculum analysis for Pommerman with a fixed computational budget
Feb 24, 2021
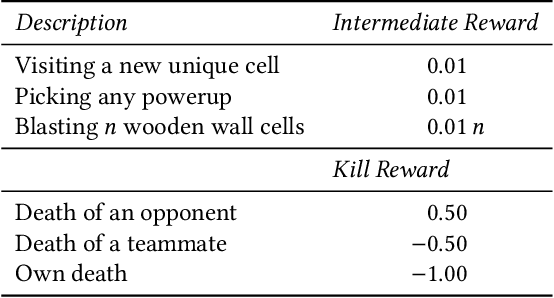

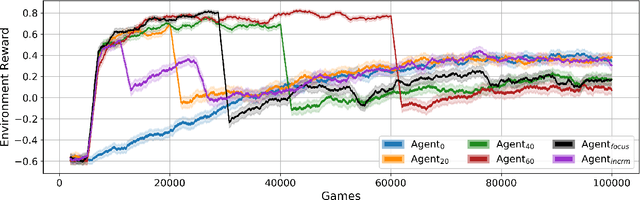
Pommerman is a hybrid cooperative/adversarial multi-agent environment, with challenging characteristics in terms of partial observability, limited or no communication, sparse and delayed rewards, and restrictive computational time limits. This makes it a challenging environment for reinforcement learning (RL) approaches. In this paper, we focus on developing a curriculum for learning a robust and promising policy in a constrained computational budget of 100,000 games, starting from a fixed base policy (which is itself trained to imitate a noisy expert policy). All RL algorithms starting from the base policy use vanilla proximal-policy optimization (PPO) with the same reward function, and the only difference between their training is the mix and sequence of opponent policies. One expects that beginning training with simpler opponents and then gradually increasing the opponent difficulty will facilitate faster learning, leading to more robust policies compared against a baseline where all available opponent policies are introduced from the start. We test this hypothesis and show that within constrained computational budgets, it is in fact better to "learn in the school of hard knocks", i.e., against all available opponent policies nearly from the start. We also include ablation studies where we study the effect of modifying the base environment properties of ammo and bomb blast strength on the agent performance.
Accelerating Training in Pommerman with Imitation and Reinforcement Learning
Nov 13, 2019

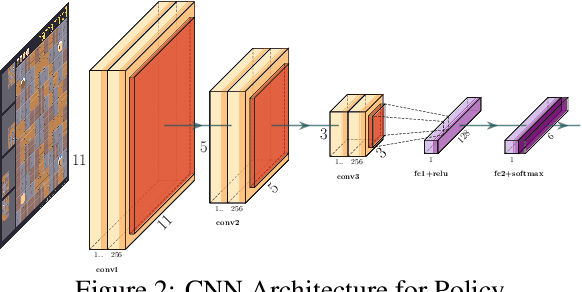

The Pommerman simulation was recently developed to mimic the classic Japanese game Bomberman, and focuses on competitive gameplay in a multi-agent setting. We focus on the 2$\times$2 team version of Pommerman, developed for a competition at NeurIPS 2018. Our methodology involves training an agent initially through imitation learning on a noisy expert policy, followed by a proximal-policy optimization (PPO) reinforcement learning algorithm. The basic PPO approach is modified for stable transition from the imitation learning phase through reward shaping, action filters based on heuristics, and curriculum learning. The proposed methodology is able to beat heuristic and pure reinforcement learning baselines with a combined 100,000 training games, significantly faster than other non-tree-search methods in literature. We present results against multiple agents provided by the developers of the simulation, including some that we have enhanced. We include a sensitivity analysis over different parameters, and highlight undesirable effects of some strategies that initially appear promising. Since Pommerman is a complex multi-agent competitive environment, the strategies developed here provide insights into several real-world problems with characteristics such as partial observability, decentralized execution (without communication), and very sparse and delayed rewards.