 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREFINE: Preference-Based Implicit Reward and Cost Fine-Tuning for Safety Alignment
May 20, 2026We address the problem of making a pre-trained reinforcement learning (RL) policy safety-aware by incorporating cost constraints without retraining it from scratch. While costs could be numerically encoded, we assume a more general setting is when costs are provided as preferences. Given a reward-optimized policy and a small dataset of preferred (low-cost) and dispreferred (high-cost) trajectories, our goal is to fine-tune the policy to generate low-cost behaviors while retaining high rewards. Unlike standard RLHF in language models, where preferences are defined over responses to the same prompt, our setting involves trajectory-level preferences in continuous control environments. We introduce PREFINE: Preference-based Implicit Reward and Cost Fine-Tuning for Safety Alignment which is a preference-based fine-tuning method that adapts Direct Preference Optimization (DPO), which is now widely used for LLM fine-tuning, to the sequential decision making setting. PREFINE constructs policy-sampled counterfactual trajectories to establish meaningful preference contrasts and jointly optimizes for reward retention and safety alignment. Empirically, PREFINE reduces constraint violations and catastrophic failures by over 60% while maintaining original reward behavior. PREFINE produces policies that achieve low-cost, high-reward performance with significantly improved data and computational efficiency compared to full offline RL or imitation learning, bridging preference alignment and safe policy adaptation in continuous domains.
How Much Online RL is Enough? Informative Rollouts for Offline Preference Optimization in RLVR
May 20, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has emerged as a powerful paradigm for reasoning in language models, with GRPO as its primary example. However, GRPO requires continuous online rollout generation, making it computationally expensive and difficult to scale. While Direct Preference Optimization (DPO) offers a stable and efficient offline alternative, it is typically expected to underperform w.r.t. online RL methods such as GRPO when trained on rollouts from a cold supervised fine-tuned (SFT) policy. We introduce G2D (GRPO to DPO)}, a three-stage pipeline that performs a short GRPO warm-up, constructs a static preference dataset, and fine-tunes a model offline with DPO. Across a set of values of the number of online steps (K) in GRPO on Qwen2.5-7B and Llama-3.1-8B, we find that offline DPO with moderate warm-up matches or outperforms GRPO at substantially lower compute cost in our setting. On Qwen2.5-7B, G2D at K=150 achieves 62.4% on MATH-500, outperforming GRPO (51.6%) by 10.8% at ~4x lower compute. On Llama-3.1-8B, G2D at K=500 achieves 49.4%, surpassing GRPO in our experimental setting. We show that performance is not governed by the number of preference pairs, which does not vary much w.r.t. K, but by their informativeness. Moderate warm-up produces rollouts with calibrated uncertainty, yielding stronger contrastive signal, while excessive warm-up leads to overconfident policies and less informative data. Our results recast the offline-online gap in RLVR as primarily a data informativeness problem, and identify short online RL warm-up with appropriate difficulty calibration of the fine-tuning dataset as a compute-efficient alternative to online RL.
Leveraging Industry 4.0 -- Deep Learning, Surrogate Model and Transfer Learning with Uncertainty Quantification Incorporated into Digital Twin for Nuclear System
Sep 30, 2022Industry 4.0 targets the conversion of the traditional industries into intelligent ones through technological revolution. This revolution is only possible through innovation, optimization, interconnection, and rapid decision-making capability. Numerical models are believed to be the key components of Industry 4.0, facilitating quick decision-making through simulations instead of costly experiments. However, numerical investigation of precise, high-fidelity models for optimization or decision-making is usually time-consuming and computationally expensive. In such instances, data-driven surrogate models are excellent substitutes for fast computational analysis and the probabilistic prediction of the output parameter for new input parameters. The emergence of Internet of Things (IoT) and Machine Learning (ML) has made the concept of surrogate modeling even more viable. However, these surrogate models contain intrinsic uncertainties, originate from modeling defects, or both. These uncertainties, if not quantified and minimized, can produce a skewed result. Therefore, proper implementation of uncertainty quantification techniques is crucial during optimization, cost reduction, or safety enhancement processes analysis. This chapter begins with a brief overview of the concept of surrogate modeling, transfer learning, IoT and digital twins. After that, a detailed overview of uncertainties, uncertainty quantification frameworks, and specifics of uncertainty quantification methodologies for a surrogate model linked to a digital twin is presented. Finally, the use of uncertainty quantification approaches in the nuclear industry has been addressed.
Digital Twin and Artificial Intelligence Incorporated With Surrogate Modeling for Hybrid and Sustainable Energy Systems
Sep 30, 2022
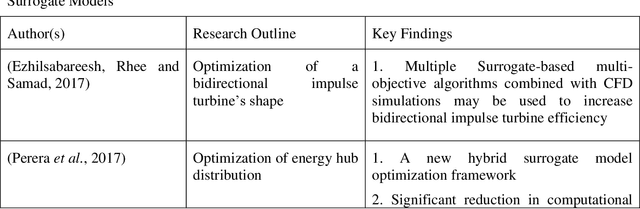
Surrogate modeling has brought about a revolution in computation in the branches of science and engineering. Backed by Artificial Intelligence, a surrogate model can present highly accurate results with a significant reduction in computation time than computer simulation of actual models. Surrogate modeling techniques have found their use in numerous branches of science and engineering, energy system modeling being one of them. Since the idea of hybrid and sustainable energy systems is spreading rapidly in the modern world for the paradigm of the smart energy shift, researchers are exploring the future application of artificial intelligence-based surrogate modeling in analyzing and optimizing hybrid energy systems. One of the promising technologies for assessing applicability for the energy system is the digital twin, which can leverage surrogate modeling. This work presents a comprehensive framework/review on Artificial Intelligence-driven surrogate modeling and its applications with a focus on the digital twin framework and energy systems. The role of machine learning and artificial intelligence in constructing an effective surrogate model is explained. After that, different surrogate models developed for different sustainable energy sources are presented. Finally, digital twin surrogate models and associated uncertainties are described.
Machine Learning and Artificial Intelligence-Driven Multi-Scale Modeling for High Burnup Accident-Tolerant Fuels for Light Water-Based SMR Applications
Sep 25, 2022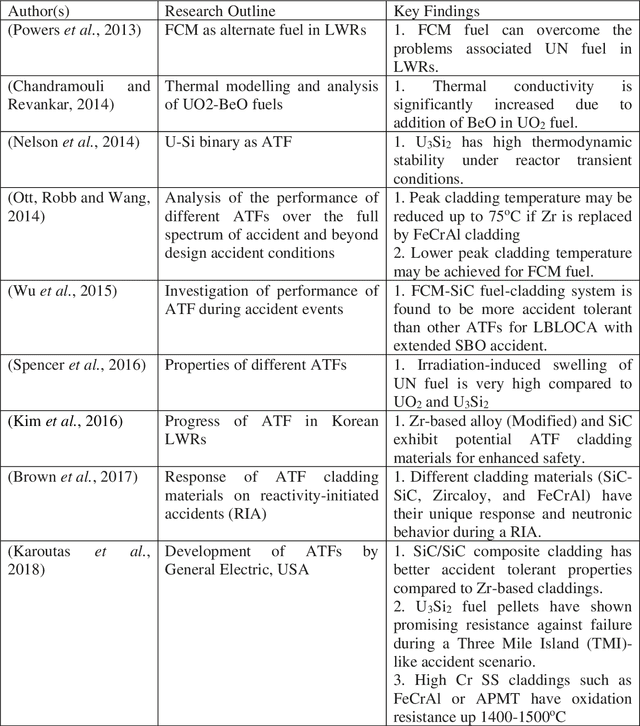

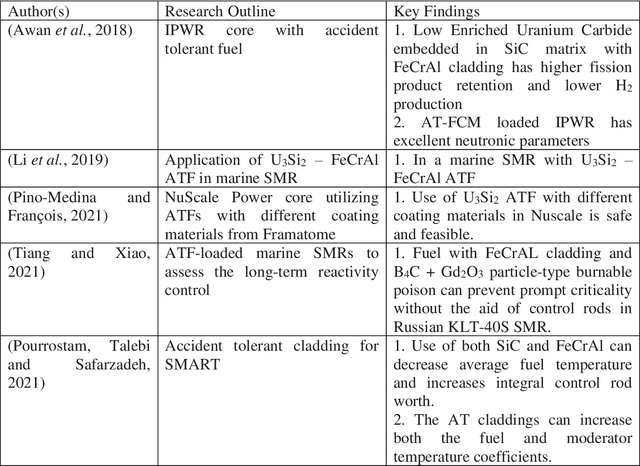
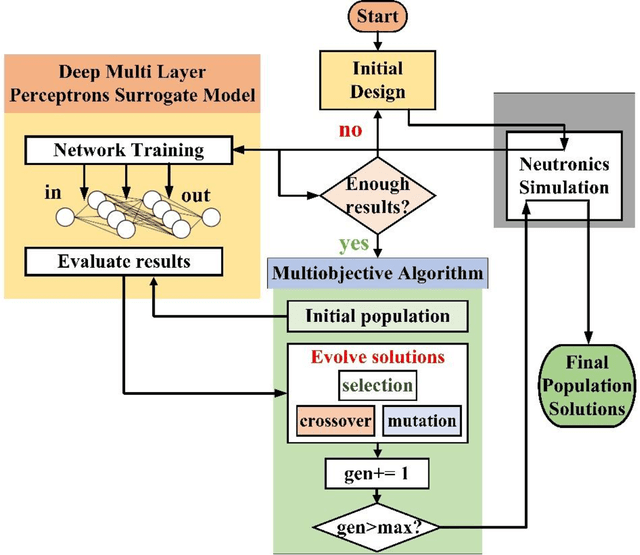
The concept of small modular reactor has changed the outlook for tackling future energy crises. This new reactor technology is very promising considering its lower investment requirements, modularity, design simplicity, and enhanced safety features. The application of artificial intelligence-driven multi-scale modeling (neutronics, thermal hydraulics, fuel performance, etc.) incorporating Digital Twin and associated uncertainties in the research of small modular reactors is a recent concept. In this work, a comprehensive study is conducted on the multiscale modeling of accident-tolerant fuels. The application of these fuels in the light water-based small modular reactors is explored. This chapter also focuses on the application of machine learning and artificial intelligence in the design optimization, control, and monitoring of small modular reactors. Finally, a brief assessment of the research gap on the application of artificial intelligence to the development of high burnup composite accident-tolerant fuels is provided. Necessary actions to fulfill these gaps are also discussed.
LIP: Lightweight Intelligent Preprocessor for meaningful text-to-speech
Jul 11, 2022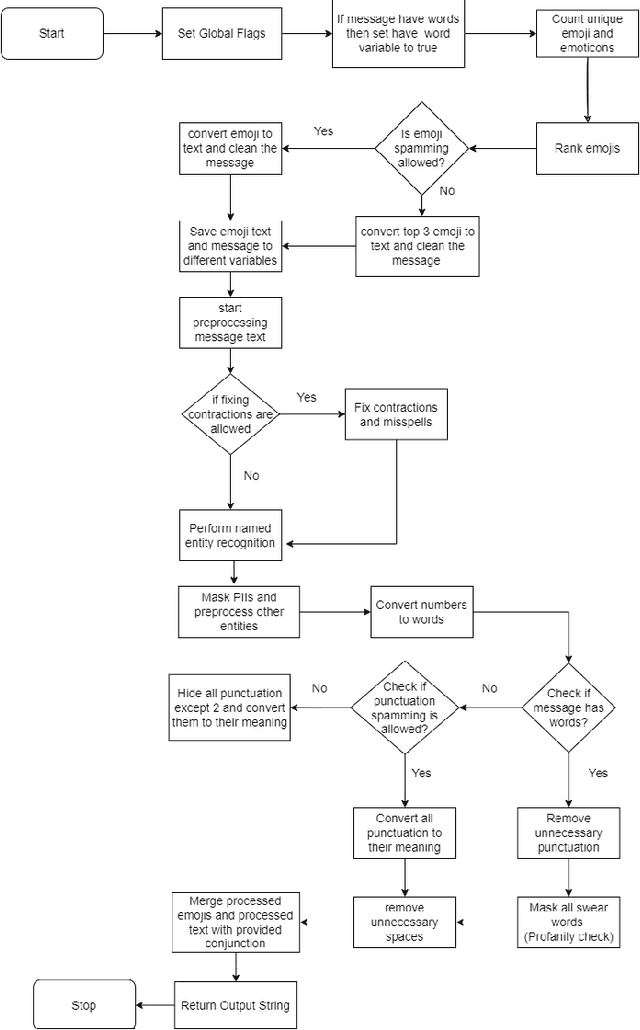
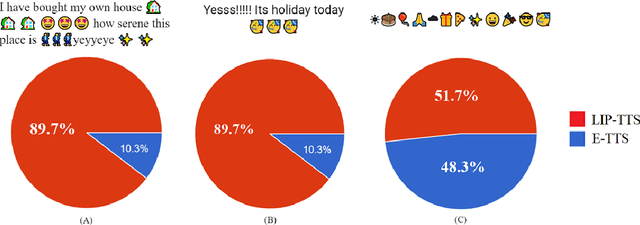
Existing Text-to-Speech (TTS) systems need to read messages from the email which may have Personal Identifiable Information (PII) to text messages that can have a streak of emojis and punctuation. 92% of the world's online population use emoji with more than 10 billion emojis sent everyday. Lack of preprocessor leads to messages being read as-is including punctuation and infographics like emoticons. This problem worsens if there is a continuous sequence of punctuation/emojis that are quite common in real-world communications like messaging, Social Networking Site (SNS) interactions, etc. In this work, we aim to introduce a lightweight intelligent preprocessor (LIP) that can enhance the readability of a message before being passed downstream to existing TTS systems. We propose multiple sub-modules including: expanding contraction, censoring swear words, and masking of PII, as part of our preprocessor to enhance the readability of text. With a memory footprint of only 3.55 MB and inference time of 4 ms for up to 50-character text, our solution is suitable for real-time deployment. This work being the first of its kind, we try to benchmark with an open independent survey, the result of which shows 76.5% preference towards LIP enabled TTS engine as compared to standard TTS.
A Generalized Reinforcement Learning Algorithm for Online 3D Bin-Packing
Jul 01, 2020
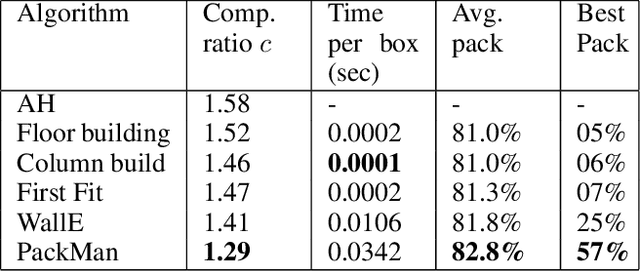
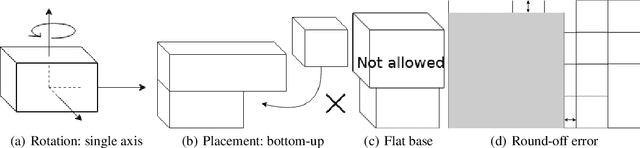

We propose a Deep Reinforcement Learning (Deep RL) algorithm for solving the online 3D bin packing problem for an arbitrary number of bins and any bin size. The focus is on producing decisions that can be physically implemented by a robotic loading arm, a laboratory prototype used for testing the concept. The problem considered in this paper is novel in two ways. First, unlike the traditional 3D bin packing problem, we assume that the entire set of objects to be packed is not known a priori. Instead, a fixed number of upcoming objects is visible to the loading system, and they must be loaded in the order of arrival. Second, the goal is not to move objects from one point to another via a feasible path, but to find a location and orientation for each object that maximises the overall packing efficiency of the bin(s). Finally, the learnt model is designed to work with problem instances of arbitrary size without retraining. Simulation results show that the RL-based method outperforms state-of-the-art online bin packing heuristics in terms of empirical competitive ratio and volume efficiency.
SIBRE: Self Improvement Based REwards for Reinforcement Learning
Apr 22, 2020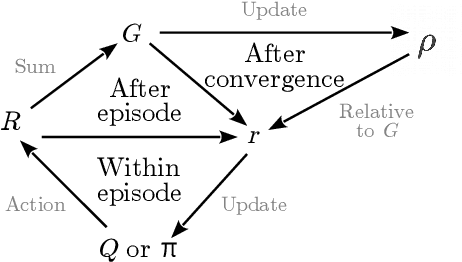
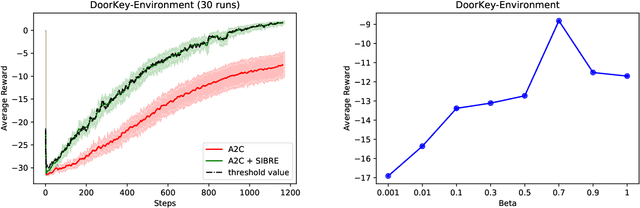
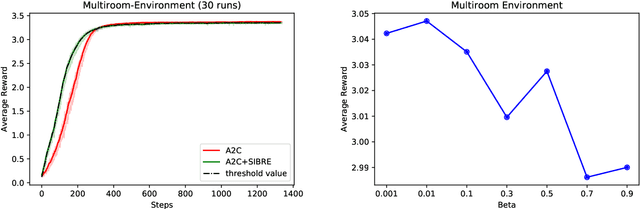
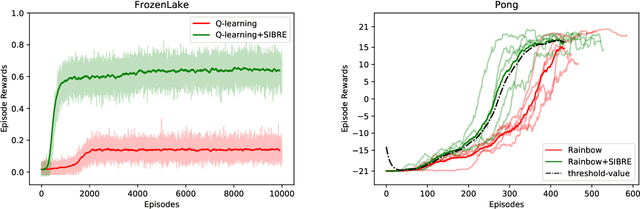
We propose a generic reward shaping approach for improving rate of convergence in reinforcement learning (RL), called Self Improvement Based REwards, or SIBRE. The approach can be used for episodic environments in conjunction with any existing RL algorithm, and consists of rewarding improvement over the agent's own past performance. We show that SIBRE converges under the same conditions as the algorithm whose reward has been modified. The new rewards help discriminate between policies when the original rewards are either weakly discriminated or sparse. Experiments show that in certain environments, this approach speeds up learning and converges to the optimal policy faster. We analyse SIBRE theoretically, and follow it up with tests on several well-known benchmark environments for reinforcement learning.
Accelerating Training in Pommerman with Imitation and Reinforcement Learning
Nov 13, 2019


The Pommerman simulation was recently developed to mimic the classic Japanese game Bomberman, and focuses on competitive gameplay in a multi-agent setting. We focus on the 2$\times$2 team version of Pommerman, developed for a competition at NeurIPS 2018. Our methodology involves training an agent initially through imitation learning on a noisy expert policy, followed by a proximal-policy optimization (PPO) reinforcement learning algorithm. The basic PPO approach is modified for stable transition from the imitation learning phase through reward shaping, action filters based on heuristics, and curriculum learning. The proposed methodology is able to beat heuristic and pure reinforcement learning baselines with a combined 100,000 training games, significantly faster than other non-tree-search methods in literature. We present results against multiple agents provided by the developers of the simulation, including some that we have enhanced. We include a sensitivity analysis over different parameters, and highlight undesirable effects of some strategies that initially appear promising. Since Pommerman is a complex multi-agent competitive environment, the strategies developed here provide insights into several real-world problems with characteristics such as partial observability, decentralized execution (without communication), and very sparse and delayed rewards.
MAPEL: Multi-Agent Pursuer-Evader Learning using Situation Report
Oct 17, 2019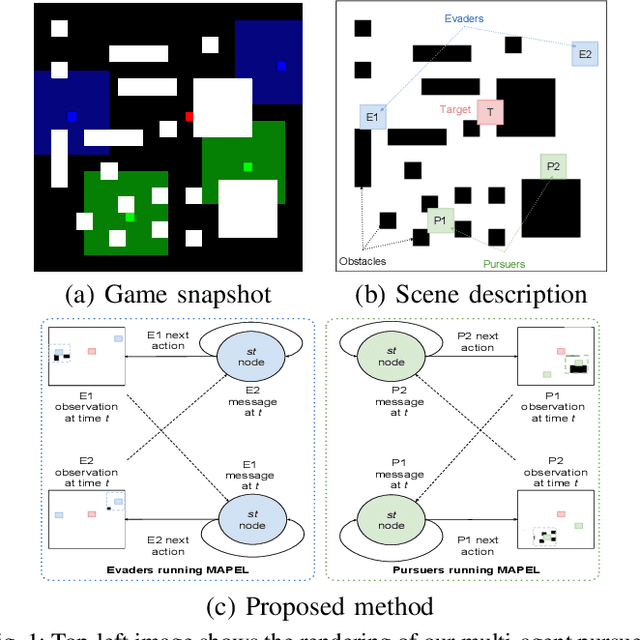
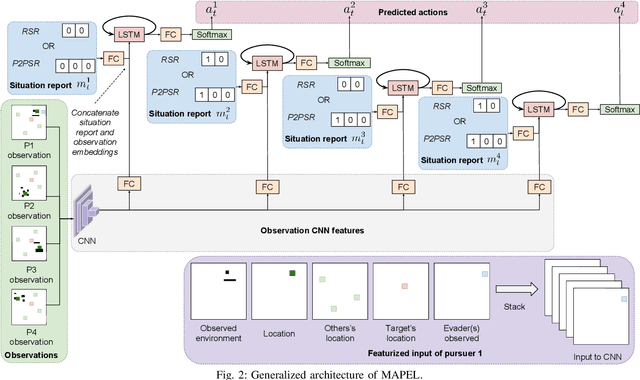
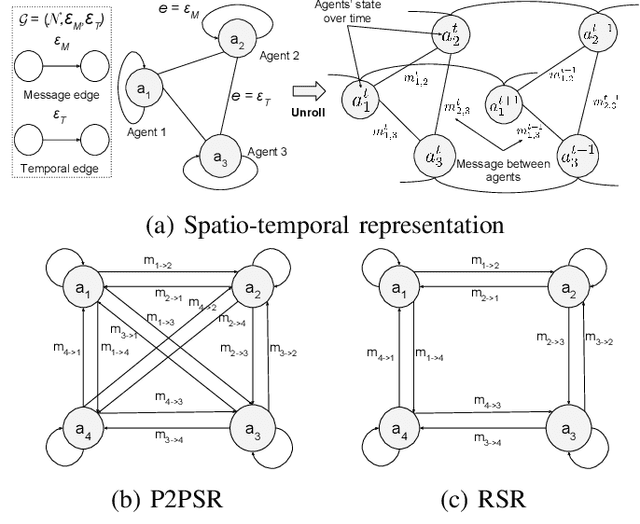
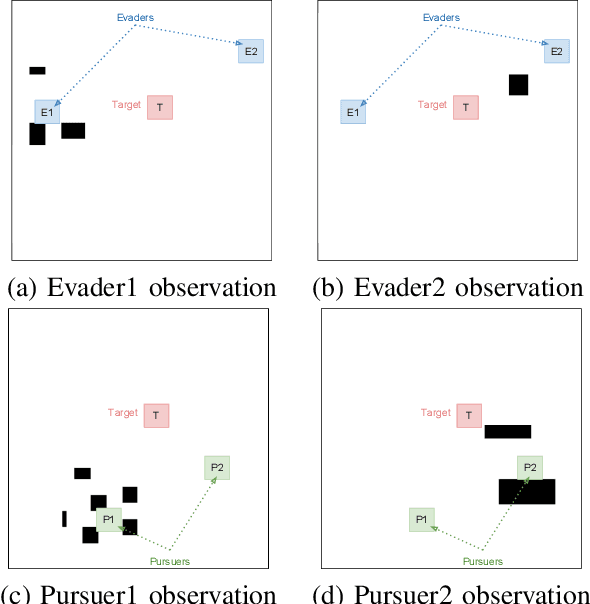
In this paper, we consider a territory guarding game involving pursuers, evaders and a target in an environment that contains obstacles. The goal of the evaders is to capture the target, while that of the pursuers is to capture the evaders before they reach the target. All the agents have limited sensing range and can only detect each other when they are in their observation space. We focus on the challenge of effective cooperation between agents of a team. Finding exact solutions for such multi-agent systems is difficult because of the inherent complexity. We present Multi-Agent Pursuer-Evader Learning (MAPEL), a class of algorithms that use spatio-temporal graph representation to learn structured cooperation. The key concept is that the learning takes place in a decentralized manner and agents use situation report updates to learn about the whole environment from each others' partial observations. We use Recurrent Neural Networks (RNNs) to parameterize the spatio-temporal graph. An agent in MAPEL only updates all the other agents if an opponent or the target is inside its observation space by using situation report. We present two methods for cooperation via situation report update: a) Peer-to-Peer Situation Report (P2PSR) and b) Ring Situation Report (RSR). We present a detailed analysis of how these two cooperation methods perform when the number of agents in the game are increased. We provide empirical results to show how agents cooperate under these two methods.